爬虫基本原理
阅读目录
一 爬虫介绍
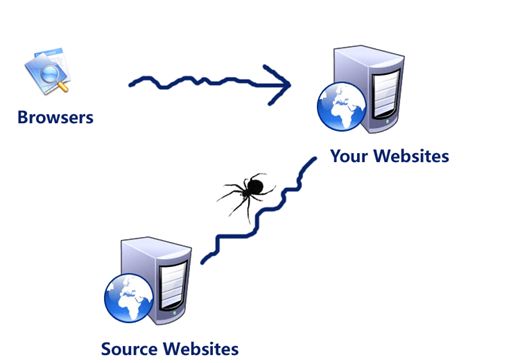

近年来,随着网络应用逐渐扩展与深入,如何高效地获取网上数据成为了无数公司和个人的追求,在如今这大数据时代里,谁能掌握更多的数据,谁就可以获取更高的利益,而网络爬虫其中最为常用的一种手段就是从网上爬虫数据。
网络爬虫,即Web Spider,是一个很形象的名字,如果把互联网比喻成蜘蛛网,互联网中的数据比喻成蜘蛛网上的猎物,那么Spider就是在网上爬来爬去的蜘蛛。网络爬虫是通过网页的链接地址来寻找网页的,从网页的主页开始,读取网页的内容,找到在主页中的其他链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页都抓取完为止。如果把整个互联网当成一个网站,那么网上的蜘蛛就可以通过这个原理把互联网上所有的页面都抓取下来。
1、什么是互联网?
互联网其实是由一堆网络设备(比如: 网线、路由器、交换机、防火墙等等...)与一台台的计算机连接而成,就像一张蜘蛛网一样。
2、互联网建立的目的
互联网的核心价值: 数据是存放在一台台计算机中的,而互联网是把计算机互联到一起,也就是说把一台台计算机中的数据都捆绑到一起了,目的就是为了能够方便每台计算机彼此之间数据的传递与数据的共享,否则你只能拿到U盘或者是移动硬盘去别人的计算机上拷贝数据了。
3、什么是上网?
上网其实指的是有用户端(客户端)的计算机向目标计算机发送请求,将目标计算机的数据下载到客户端计算机的过程。
- 普通用户获取数据的方式:
浏览器提交请求 ---> 下载页面代码 ---> 解析/渲染成页面。 - 爬虫程序获取数据的方式:
模拟浏览器发送请求 ---> 下载页面代码 ---> 只提取有用的数据 ---> 存放于数据库中或文件中。 - 普通用户与爬虫程序的区别:
- 普通用户: 普通用户是通过打开浏览器访问网页,浏览器会接收所有的数据。
- 爬虫程序: 爬虫程序只提取网页代码中对我们有价值的数据。
- 普通用户: 普通用户是通过打开浏览器访问网页,浏览器会接收所有的数据。
- 普通用户获取数据的方式:
4、爬虫总结
-
- 爬虫的比喻:
如果我们把互联网比喻成一张大的蜘蛛网,那一台计算机上的数据就是蜘蛛网上的猎物,而爬虫程序就是一只小蜘蛛,沿着蜘蛛网抓取自己想要的猎物(数据)。 - 爬虫的定义:
伪装成浏览器向目标网站发送请求,获取响应资源后解析并提取有价值的数据的程序。 - 爬虫的价值:
互联网中最有价值的便是数据,例如: 天猫、淘宝、京东商品的商品信息,链家网的租房/房源信息,雪球网的证券投资信息等等...这些数据都代表了各个行业最有价值的东西,若谁掌握了行业内的第一手数据,那么谁就能成为这个行业的主宰。如果把互联网中的数据比喻成一座宝藏,那我们的爬虫课程就是教大家如何高效地挖掘这些宝藏,掌握了爬虫技能,你就能成为所有互联网信息公司的幕后老板,换言之,他们都是在免费为你提供有价值的数据。
- 爬虫的比喻:
5、 爬虫的应用
'''
1.通用爬虫: 通用爬虫是搜索引擎(Baidu、Google、Yahoo等)"抓取系统" 的重要组成部分。主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份。
搜索引擎如何抓取互联网上的网站数据:
a) 目标网站主动向搜索引擎公司提供其网站的url。 b) 搜索引擎公司与DNS服务商合作,获取目标网站的url。 c) 目标网站主动挂靠在一些知名网站的友情链接中。 2.聚焦爬虫: 聚焦爬虫是根据指定的需求抓取网络上指定的数据。例如: 获取豆瓣上电影的名称和影评,而不是获取整张页面中所有的数据值。 3.数据分析的数据样本 4.机器学习的数据样本 '''
6、实现爬虫的编程语言
''' 1.python: 可以实现爬虫。python实现和处理爬虫语法简单,代码优美,支持的模块繁多,学习成本低,具有非常强大的框架(scrapy等)且一句难以言表的好!没有但是! 2.java: 可以实现爬虫。java可以非常好的处理和实现爬虫,是唯一可以与python并驾齐驱且是python的头号劲敌。但是java实现爬虫代码较为臃肿,重构成本较大。 3.c、c++: 可以实现爬虫。但是使用这种方式实现爬虫纯粹是是某些人(大佬们)能力的体现,却不是明智和合理的选择。 4.php: 可以实现爬虫。php被号称是全世界最优美的语言(当然是其自己号称的,就是王婆卖瓜的意思),但是php在实现爬虫中支持多线程和多进程方面做的不好。 '''
二 爬虫的基本流程
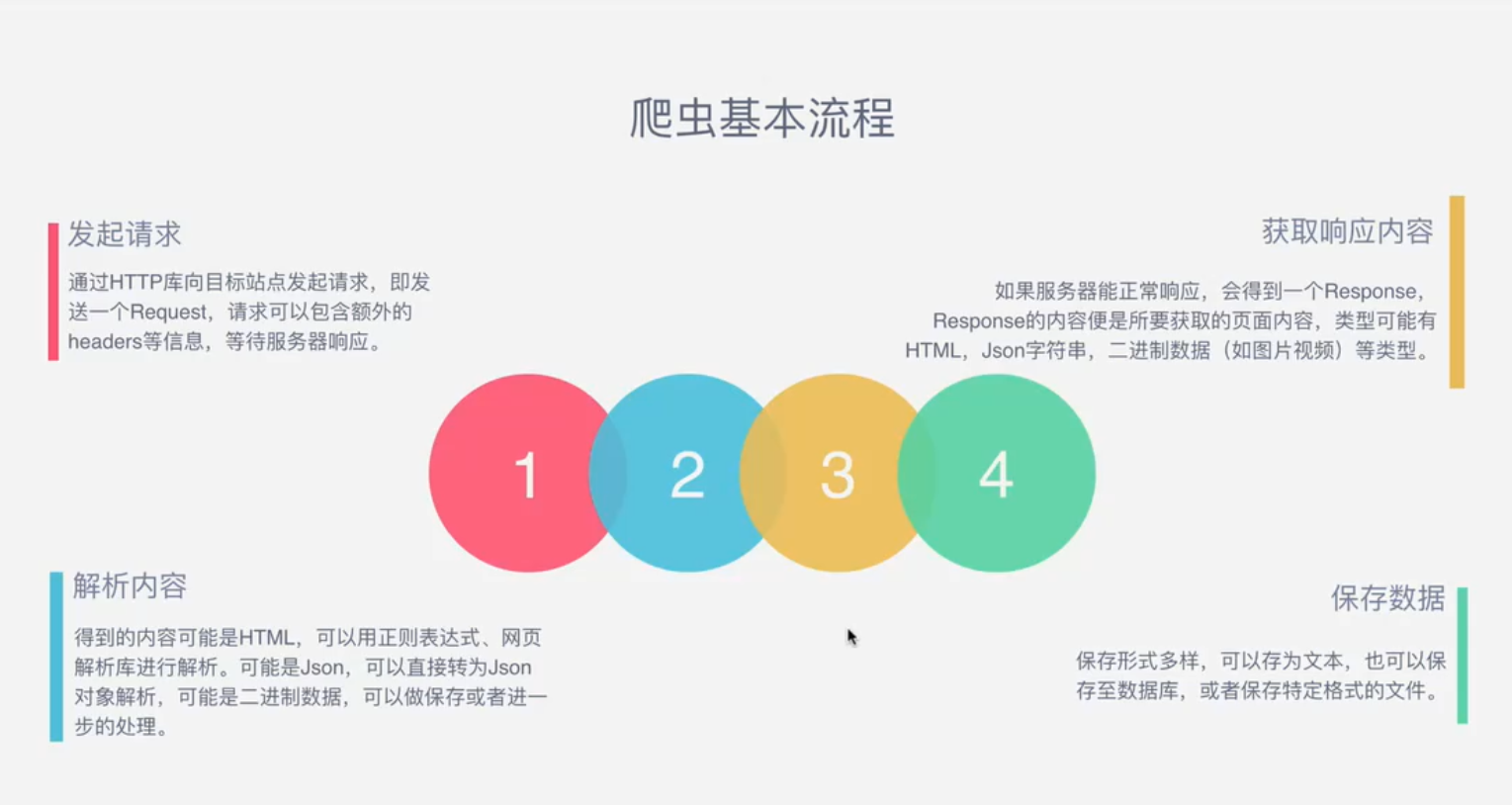
爬虫的基本流程其实就是模拟浏览器往目标站点发送请求,那浏览器发送的是http协议数据格式的请求,http协议的底层其实就是TCP协议数据格式。其实浏览器是一个套接字客户端,访问的目标站点是一个套接字服务端。那套接字客户端要与套接字服务端建立链接,得先拿到 ”客户端的ip和端口“ 与 ”服务端的ip和端口“ ,然后套接字客户端才向套接字服务端发送一次connection的请求,通过三次握手建立双向链接,此时形成了两条管道,一条是客户端往服务端发送数据的管道,另一条是服务端接收到请求后把数据返回给客户端的管道。那浏览器会沿着第一条管道往服务端发送的http协议的请求,服务端会把响应数据打包成http协议的数据格式,沿着第二条管道返回给客户端。这就是爬虫的基本流程。
''' 1.发起请求: 使用http库向目标站点发起请求,即发送一个Request Request包含:请求头、请求体等... 2.获取响应内容 如果服务器能正常响应,则会得到一个Response Response包含:html,json,图片,视频等... 3.解析内容 解析html数据: 正则表达式,第三方解析库如Beautifulsoup,pyquery等 解析json数据: json模块 解析二进制数据: 以b的方式写入文件 4.保存数据 数据库 文件 '''
三 请求与响应

''' URL: 即统一资源定位符,也就是我们说的网址,统一资源定位符是对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。 互联网上的每个文件都有一个唯一的URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它。 URL的格式由三部分组成: ①第一部分是协议(或称为服务方式)。 ②第二部分是存有该资源的主机IP地址(有时也包括端口号)。 ③第三部分是主机资源的具体地址,如目录和文件名等 http协议: https://www.cnblogs.com/kermitjam/p/10432198.html robots协议: https://www.cnblogs.com/kermitjam/articles/9692568.html Request: 用户将自己的信息通过浏览器(socket client)发送给服务器(socket server) Response: 服务器接收请求,分析用户发来的请求信息,然后返回数据(返回的数据中可能包含其他链接,如:图片,js,css等) ps: 浏览器在接收Response后,会解析其内容来显示给用户,而爬虫程序在模拟浏览器发送请求然后接收Response后,是要提取其中的有用数据。 '''
四 Request
1、请求方式
''' 常用的请求方式: GET,POST 其他请求方式: HEAD,PUT,DELETE,OPTHONS POST与GET请求最终都会拼接成这种形式: k1=xxx&k2=yyy&k3=zzz POST请求的参数放在请求体内: 可用浏览器查看,存放于form data内。而GET请求的参数直接放在url后。 示例: 演示登录与不登录获取的数据,以及请求方式。 '''
2、请求url
''' url全称统一资源定位符: 如一个网页文档,一张图片,一个视频等都可以用url唯一来确定。 url编码: https://www.baidu.com/s?wd=图片 图片会被编码(看示例代码) 网页的加载过程是: 加载一个网页,通常都是先加载document文档,在解析document文档的时候,遇到链接,则针对超链接发起下载图片的请求。 '''
3、请求头
''' User-Agent: 请求头中如果没有user-agent客户端配置,服务端可能将你当做一个非法用户。 Cookies: cookie用来保存登录信息。 Referer: 浏览器上次访问的网页url, 一般做爬虫都会加上请求头。 '''


''' Cookie ``` Cookie: "......" 同样是一个比较关键的字段,Cookie是 client 请求 服务器时,服务器会返回一个键值对样的数据给浏览器,下一次浏览器再访问这个域名下的网页时,就需要携带这些键值对数据在 Cookie中,用来跟踪浏览器用户的访问前后路径。 在爬虫时,我会根据前次访问得到 cookie数据,然后添加到下一次的访问请求头中。 ``` - User-Agent ``` 中文名用户代理,服务器从此处知道客户端的 操作系统类型和版本,电脑CPU类型,浏览器种类版本,浏览器渲染引擎,等等。这是爬虫当中最最重要的一个请求头参数,所以一定要伪造,甚至多个。如果不进行伪造,而直接使用各种爬虫框架中自定义的user-agent,很容易被封禁。举例: User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:52.0) Gecko/20100101 Firefox/52.0 User-Agent: Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36 网上有很多的用户代理大全,用户代理大全越多越好,用以伪造多个请求头。 ``` - Referer ``` 浏览器上次访问的网页url,uri。由于http协议的无记忆性,服务器可从这里了解到客户端访问的前后路径,并做一些判断,如果后一次访问的 url 不能从前一次访问的页面上跳转获得,在一定程度上说明了请求头有可能伪造。 我在爬虫时,起始入口我会给一个随意的百度搜索地址,然后,在爬取过程中,不断将索引页面的url添加在伪造请求头中。 Referer: https://www.baidu.com/s?wd=%E7%BE%8E%E5%A5%B3&rsv_spt=1&rsv_iqid=0xce19ceff0002f196&issp=1&f=8&rsv_bp=1&rsv_idx=2&ie=utf-8&rqlang=cn&tn=baiduhome_pg&rsv_enter=1&oq=%25E7%25BE%258E%25E5%25A5%25B3&inputT=4&rsv_t=46216vF7O9LH18hEfGKnjaFukwpJdM3UIwrvEb6LkFIXOIsDt2OQf5Ocfy%2F5LJsCTnkJ&rsv_sug3=9&rsv_sug1=6&rsv_sug7=100&rsv_sug2=0&rsv_pq=e4b29f73000184eb&rsv_sug4=596&rsv_sug=1 ``` - Accept: ``` Accept:text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8 指定客户端可以接受的内容类型,比如文本,图片,应用等等,内容的先后排序表示客户端接收的先后次序,每种类型之间用逗号隔开。 其中,对于每一种内容类型,分号 ; 后面会加一个 q=0.6 这样的 q 值,表示该种类型被客户端喜欢接受的程度,如果没有表示 q=1,数值越高,客户端越喜欢这种类型。 爬虫的时候,我一般会伪造若干,将想要找的文字,图片放在前面,其他的放在后面,最后一定加上*/*;q=0.8。 比如Accept: image/gif,image/x-xbitmap,image/jpeg,application/x-shockwave-flash,application/vnd.ms-excel,application/vnd.ms-powerpoint,application/msword,*/* text/xml,text/shtml:文本类型,斜杠后表示文档的类型,xml,或者shtml application/xml,application/xhtml+xml:应用类型,后面表示文档类型,比如 flash动画,excel表格等等 image/gif,image/x-xbitmap:图片类型,表示接收何种类型的图片 ``` - Accept-Language ``` 客户端可以接受的语言类型,参数值规范和 accept的很像。一般就接收中文和英文,有其他语言需求自行添加。比如: Accept-Language: zh-CN,zh;q=0.8,en-US;q=0.6,en;q=0.4 zh-CN:中文简体大陆? zh:其他中文 en-US:英语美语 en:其他英语 Accept-Language: zh-CN,zh;q=0.9 ``` - Accept-Encoding: ``` 客户端接收编码类型,一些网络压缩格式。我看了很多常见的请求头,基本上都不变,就是如下: Accept-Encoding: gzip, deflate, sdch。相对来说,deflate是一种过时的压缩格式,现在常用的是gzip ``` - Cache-Control ``` Cache-Control: no-cache 指定了服务器和客户端在交互时遵循的缓存机制,即是否要留下缓存页面数据。 一般在使用浏览器访问时,都会在计算机本地留下缓存页面,相当于是浏览器中的页面保存和下载选项。但是爬虫就是为了从网络上爬取数据,所以几乎不会从缓存中读取数据。所以在设置的时候要侧重从服务器请求数据而非加载缓存。 no-cache:客户端告诉服务器,自己不要读取缓存,要向服务器发起请求 no-store:同时也是响应头的参数,请求和响应都禁止缓存,即不存储 max-age=0:表示当访问过此网页后的多少秒内再次访问,只加载缓存,而不去服务器请求,在爬虫时一般就写0秒 一般爬虫就使用以上几个参数,其他的参数都是接受缓存的,所以就不列出了。 ``` - Connection ``` Connection: keep-alive 请求头的 header字段指的是当 client 浏览器和 server 通信时对于长链接如何处理。由于http请求是无记忆性的,长连接指的是在 client 和server 之间建立一个通道,方便两者之间进行多次数据传输,而不用来回传输数据。有 close,keep-alive 等几种赋值,close表示不想建立长连接在操作完成后关闭链接,而keep-alive 表示希望保持畅通来回传输数据。 此外,connection还可以存放一些自定义声明,比如: Connection: my-header, close My-Header: xxx 其中,my-header指的是当前访问请求中使用的请求头,close表示数据传输完毕后不保持畅通,关闭链接。 在爬虫时我一般都建立一个长链接。 ``` - Host ``` Host:www.baidu.com 访问的服务器主机名,比如百度的 www.baidu.com。这个值在爬虫时可以从 访问的 URI 中获得 ``` - Pragma ``` Pragma: no-cache 和 cache-control类似的一个字段,但是具体什么含义我还没有查清楚,一般爬虫时我都写成 no-cache。 ``` - Proxy-Connection ``` 当使用代理服务器的时候,这个就指明了代理服务器是否使用长链接。但是,数据在从client 到代理服务器,和从代理服务器到被请求的服务器之间如果存在信息差异的话,会造成信息请求不到,但是在大多数情况下,都还是能够成立的。 ``` - Accept-Charset ``` 指的是规定好服务器处理表单数据所接受的字符集,也就是说,客户端浏览器告诉服务器自己的表单数据的字符集类型,用以正确接收。若没有定义,则默认值为“unknown”。如果服务器没有包含此种字符集,就无法正确接收。一般情况下,在爬虫时我不定义该属性,如果定义,例子如下: Accept-Charset:gb2312,gbk;q=0.7,utf-8;q=0.7,*;q=0.7 ``` - Upgrade-Insecure-Requests ``` 自动将不安全的访问请求转换成安全的请求 request。赋值数字1表示可以,0就表示不可以。 ``` - Range ``` 浏览器告诉 WEB 服务器自己想取对象的哪部分。这个在爬虫时我接触比较少,一般都是爬取整个页面,然后再做分析处理。 ``` - If-Modified-Since ``` 只有当所请求的内容在指定的日期之后又经过修改才返回它,否则返回304。其目的是为了提高访问效率。但是在爬虫时,不设置这个值,而在增量爬取时才设置一个这样的值,用以更新信息。 ``` '''
# PC端 # Opera Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 OPR/26.0.1656.60 Opera/8.0 (Windows NT 5.1; U; en) Mozilla/5.0 (Windows NT 5.1; U; en; rv:1.8.1) Gecko/20061208 Firefox/2.0.0 Opera 9.50 Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; en) Opera 9.50 # Firefox Mozilla/5.0 (Windows NT 6.1; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0 Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10 # Safari Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.57.2 (KHTML, like Gecko) Version/5.1.7 Safari/534.57.2 # chrome Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36 Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11 Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.648.133 Safari/534.16 # 360 Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.1599.101 Safari/537.36 Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko # 淘宝浏览器 Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11 # 猎豹浏览器 Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; LBBROWSER) Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E; LBBROWSER)" # QQ浏览器 Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; QQBrowser/7.0.3698.400) Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E) # sogou浏览器 Mozilla/5.0 (Windows NT 5.1) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 SE 2.X MetaSr 1.0 Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; SE 2.X MetaSr 1.0) # maxthon浏览器 Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Maxthon/4.4.3.4000 Chrome/30.0.1599.101 Safari/537.36 # UC浏览器 Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 UBrowser/4.0.3214.0 Safari/537.36 # 手机端: # IPhone Mozilla/5.0 (iPhone; U; CPU iPhone OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5 # IPod Mozilla/5.0 (iPod; U; CPU iPhone OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5 # IPAD Mozilla/5.0 (iPad; U; CPU OS 4_2_1 like Mac OS X; zh-cn) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8C148 Safari/6533.18.5 Mozilla/5.0 (iPad; U; CPU OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5 # Android Mozilla/5.0 (Linux; U; Android 2.2.1; zh-cn; HTC_Wildfire_A3333 Build/FRG83D) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1 Mozilla/5.0 (Linux; U; Android 2.3.7; en-us; Nexus One Build/FRF91) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1 # QQ浏览器 Android版本 MQQBrowser/26 Mozilla/5.0 (Linux; U; Android 2.3.7; zh-cn; MB200 Build/GRJ22; CyanogenMod-7) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1 # Android Opera Mobile Opera/9.80 (Android 2.3.4; Linux; Opera Mobi/build-1107180945; U; en-GB) Presto/2.8.149 Version/11.10 # Android Pad Moto Xoom Mozilla/5.0 (Linux; U; Android 3.0; en-us; Xoom Build/HRI39) AppleWebKit/534.13 (KHTML, like Gecko) Version/4.0 Safari/534.13 # BlackBerry Mozilla/5.0 (BlackBerry; U; BlackBerry 9800; en) AppleWebKit/534.1+ (KHTML, like Gecko) Version/6.0.0.337 Mobile Safari/534.1+ # WebOS HP Touchpad Mozilla/5.0 (hp-tablet; Linux; hpwOS/3.0.0; U; en-US) AppleWebKit/534.6 (KHTML, like Gecko) wOSBrowser/233.70 Safari/534.6 TouchPad/1.0 # Nokia N97 Mozilla/5.0 (SymbianOS/9.4; Series60/5.0 NokiaN97-1/20.0.019; Profile/MIDP-2.1 Configuration/CLDC-1.1) AppleWebKit/525 (KHTML, like Gecko) BrowserNG/7.1.18124 # Windows Phone Mango Mozilla/5.0 (compatible; MSIE 9.0; Windows Phone OS 7.5; Trident/5.0; IEMobile/9.0; HTC; Titan) # UC浏览器 UCWEB7.0.2.37/28/999 # NOKIA5700 NOKIA5700/ UCWEB7.0.2.37/28/999 # UCOpenwave Openwave/ UCWEB7.0.2.37/28/999 # UC Opera Mozilla/4.0 (compatible; MSIE 6.0; ) Opera/UCWEB7.0.2.37/28/999
4、请求体
''' GET请求方式,请求体没有内容。 POST请求方式,请求体是format data。 ps: 1、登录窗口,文件上传等,信息都会被附加到请求体内。 2、登录,输入错误的用户名密码,然后提交就可以看到POST请求体,正确登录后页面通常会跳转,无法捕捉到POST请求体。 '''
5、普通示例
import requests from urllib.parse import urlencode url = 'http://www.baidu.com/s?' + urlencode({'wd': "美女"}) response = requests.get(url) print(response.text)
五 Response
'''
1、响应状态: 200:代表成功 301:代表跳转 404:文件不存在 403:权限 502:服务器错误 2、响应头: Respone header set-cookie:可能有多个,是来告诉浏览器,把cookie保存下来。 3、网页源代码: preview 最主要的部分,包含了请求资源的内容,如网页html、图片和二进制数据等。
'''
六 总结
1、总结爬虫流程: 爬取 ---> 解析 ---> 存储 2、爬虫所需工具: 请求库:requests,selenium 解析库:正则,beautifulsoup,pyquery 存储库:文件,MySQL,Mongodb,Redis 3、爬虫常用框架: scrapy

 浙公网安备 33010602011771号
浙公网安备 33010602011771号