并发编程(十):ConcurrentHashMap
1.为什么使用ConcurrentHashMap
并发模式下使用HashMap的put会产生环形链,导致死循环
HashTable和Collections.synchronizedMap(map)则使用synchronized保证线程安全,效率很低
ConcurrentHashMap分段锁技术能够有效提升并发访问率,将数据分为一段一段(segment)的,每段数据使用一个锁,一段数据被占用,不影响其他数据的访问
2.ConcurrentHashMap结构
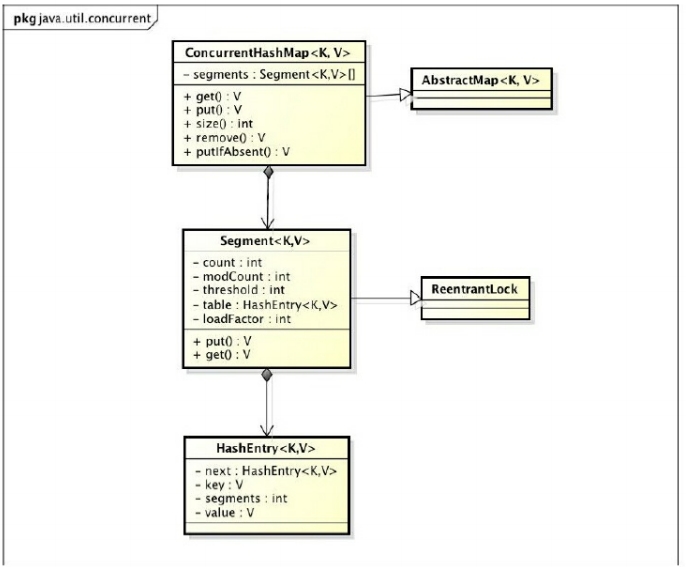
类图:
结构图:
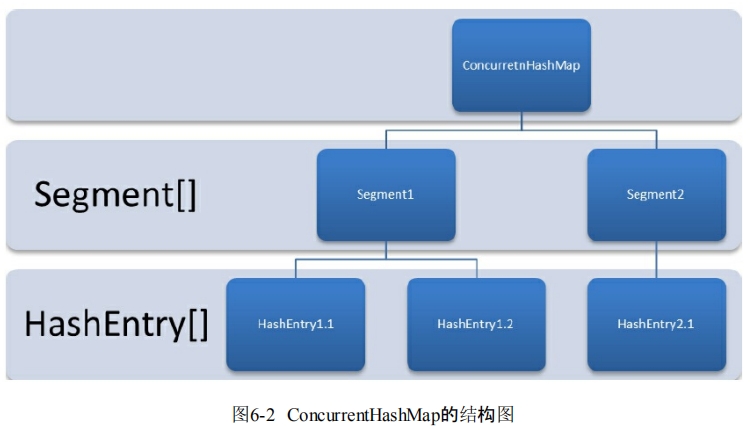
一个ConcurrentHashMap由一个Segment数组和多个HashEntry数组构成:
- Segment是一个可重入锁(ReentrantLock)
- HashEntry用于存储键值对数据,是一个链表结构元素,一个Segment中包含了一个HashEntry数组,对该数组数据修改时,需要获取对应的Segment锁
3.ConcurrentHashMap的初始化
3.1 初始化segments数组
//concurrencyLevel默认16
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
//ssize从1向左移位的次数
int sshift = 0;
//sigment数组长度
int ssize = 1;
while (ssize < concurrencyLevel) {
//ssize左移一位sshift+1
++sshift;
//ssize左移一位
ssize <<= 1;
}
//偏移量
segmentShift = 32 - sshift;
//散列运算掩码
segmentMask = ssize - 1;
//创建segment数组
this.segments = Segment.newArray(ssize);
为了能用按位与的散列算法定位segments数组索引,必须计算出一个2的N次方的作为数组长度(不小于concurrencyLevel的最小2的N次方)
默认concurrencyLevel=16,ssize=16,sshift=4,segmentShift=28,segmentMask=15
concurrencyLevel最大可为65535(16位)
3.2 初始化segmentShift和segmentMask
segmentShift段偏移量和segmentMask散列运算掩码需要在散列运算时使用
(掩码的二进制各个位的值都是1)
3.3 初始化每个segment
//initialCapacity初始化容量
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
//初始化容量/segment数量=每个segment平均容量
int c = initialCapacity / ssize;
//C比平均容量偏大
if (c * ssize < initialCapacity) ++c;
//cap为segment里HashEntry的长度
int cap = 1;
while (cap < c)
//大于c(平均容量)的最小2的n次值
cap <<= 1;
for (int i = 0; i < this.segments.length; ++i)
//loadFactor负载因子
this.segments[i] = new Segment<K,V>(cap, loadFactor);
initialCapacity是ConcurrentHashMap的初始化容量,loadfactor是每个segment的负载因子
cap为segment里HashEntry的长度,Segment的容量threshold=(int)cap*loadFactor
默认情况下initialCapacity=16,loadFactor=0.75,cap=1,threshold=0
4.定位Segment
先通过散列算法定位到Segment,然后再通过Wang/Jenkins hash的变种算法再一次进行Hash,目的是为了减少散列冲突,使得元素能够均匀分布,提高存取效率
ConcurrentHashMap通过以下散列算法定位segment:
final Segment<K,V> segmentFor(int hash) {
//hash值仅用高位,防止和寻找元素时的hash冲突
return segments[(hash >>> segmentShift) & segmentMask];
}
hash代码如下:
private static int hash(int h) {
h += (h << 15) ^ 0xffffcd7d;
h ^= (h >>> 10);
h += (h << 3);
h ^= (h >>> 6);
h += (h << 2) + (h << 14);
return h ^ (h >>> 16);
}
5.ConcurrentHashMap的操作
5.1 get操作
public V get(Object key) {
//hashcode一次hash,再进行一次hash
int hash = hash(key.hashCode());
//运算散列值定位segment(高位),和元素(所有位)
return segmentFor(hash).get(key, hash);
}
get过程中不需要加锁,因为get方法中共享变量都是定义成volatile类型的
定位Segment使用的是元素的hashcode通过再散列后得到的值的高位,而定位HashEntry直接使用的是再散列后的值,防止散列值相同:
hash >>> segmentShift & segmentMask; // 定位Segment所使用的hash算法(分散)
int index = hash & (tab.length - 1); // 定位HashEntry所使用的hash算法(不分散)
5.2 put操作
put操作需要加锁,首先定位到segment,然后在segment里进行插入操作
插入操作有两个步骤:判断是否需要扩容,定位元素位置并保存(HashEntry中)
- 判断是否扩容:在插入元素前判断是否超过threshold(HashMap是在插入元素后判断)
- 如何扩容:不会对整个ConcurrentHashMap进行扩容,只会对某个segment进行扩容
5.3 size操作
必须统计所有segment的size大小后求和,segment里的count虽然是volatile变量,但是累加操作也是线程不安全的,因为读取一个数据之后可能count会被其他线程修改;
最安全的方法:计算size时锁住所有put(),clean()和remove()方法,效率很低;
CurrentHashMap的做法:尝试两次不加锁统计各个segment大小,如果两次都发生了修改(通过modCount修改+1统计),则使用加锁方式

 浙公网安备 33010602011771号
浙公网安备 33010602011771号