
EXT2文件系统
数据结构和遍历
-
Block#0 是引导块,文件系统不会使用它,它用于容纳从磁盘引导操作系统的引导程序
-
Block#1 是超级块,用于容纳关于整个文件系统的信息
-
Block#2 是块组描述符,EXT2将磁盘块分成几个组,每组有8192个块,每组用一个块组描述符结构体描述
-
Block#8 是块位图,用于表示某种项的位序列,例如磁盘块或索引节点,位图用于分配和回收项。
-
Block#9 是索引节点位图,索引节点用于代表一个文件的数据结构
-
Block#10 是索引(开始)节点块,索引节点大小用于平均分割块大小,所以每个索引节点块都包含整数个索引节点。
-
数据块 是紧跟在索引节点块后面的文件存储块。
-
邮差算法:类似二维数组的存储和访问
遍历算法:
(1)读取超级块。检查幻数s_magic ( OxEF53),验证它确实是EXT2FS。
(2)读取块组描述符块(1+s_first_data_block),以访问组0描述符。从块组描述符的bg_inode_table条目中找到索引节点的起始块编号,并将其称为InodesBeginBlock 。
(3)读取 InodeBeginBlock,获取/的索引节点,即INODE #2。
(4)将路径名标记为组件字符串,假设组件数量为n。
例如,如果路径名=/a/b/c,则组件字符串是“a”"b”“c”,其中n =3。用name[0],name[1],…,name[n-1]来表示组件。(5)
从(3)中的根索引节点开始,在其数据块中搜索name[0]。
为简单起见,我们可以假设某个目录中的条目数量很少,因此一个目录索引节点只有12个直接数据块。
有了这个假设,就可以在12个(非零)直接块中搜索name[0]。目录索引节点的每个数据块都包含以下形式的dir_entry结构体:
[ino rec_len name_len NANE] [ino rec_len name_len NAME]
其中NAME是一系列nlen字符,不含终止NULL。
对于每个数据块,将该块读入内存并使用dir_entry *dp指向加载的数据块。
然后使用name_len将NAME提取为字符串,并与name[0]进行比较。如果它们不匹配,则通过以下代码转到下一个dir_entry:
dp = (dir_entry *) ((char *)dp + dp->rec_len);
继续搜索。如果存在name[0],则可以找到它的dir_entry,从而找到它的索引节点号。(6)
使用索引节点号ino来定位相应的索引节点。回想前面的内容,ino从1开始计数。使用邮差算法计算包含索引节点的磁盘块及其在该块中的偏移量。
blk=(ino - 1) / INODES_PER_BLOCK+ InodesBeginBlock;
offset = (ino - 1)% INODES_PER_BLOCK;
然后在索引节点中读取/a,从中确定它是否是一个目录(DIR)。
如果/a不是目录,则不能有/a/b,因此搜索失败。
如果它是目录,并且有更多需要搜索的组件,那么继续搜索下一个组件name[1]。
现在的问题是:在索引节点中搜索/a的name[1],与第(5)步完全相同。(7)
由于(5)~(6)步将会重复n次,所以最好编写一个搜索函数:
u32 search ( INODE*inodePtr, char *name)
然后只需调用n次search函数
如果搜索循环成功结束,ip必须指向路径名的索引节点。
支持Linux所有文件操作的EXT2文件系统
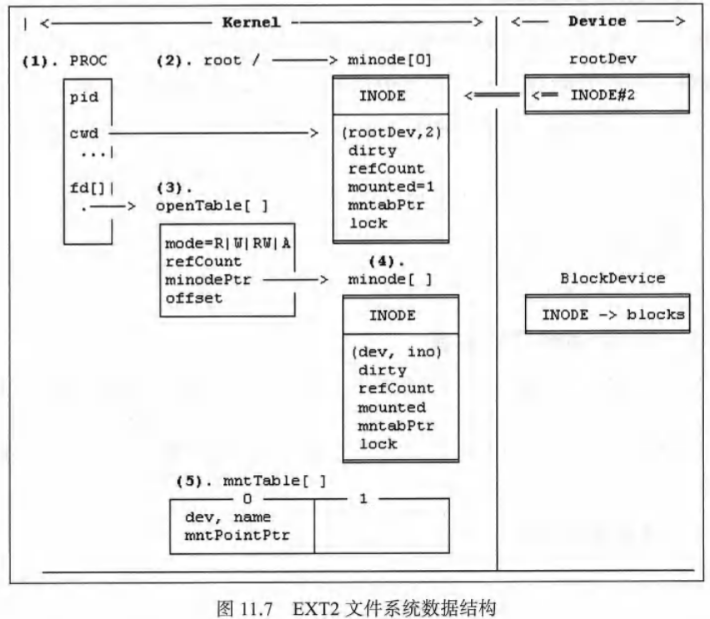
通过虚拟磁盘mount_root构建基本文件系统
- mount_root.c文件。包含mount_root函数。
- 基本文件系统树
- type.h文件。包含ext2文件系统的数据结构类型,还包含打开文件表、挂载表、PROC结构体和文件系统常数。
- global.c文件。包含文件系统的全局变量。
- 实用程序函数util.c文件。包含文件系统常用的实用程序函数。
- get_block/put_block
- iget(dev,ino)
- the input(INDODE *mip)
- getino()/iget()/iput
- 文件内容读/写函数
- 文件系统的挂载、卸载和文件保护
三个级别
- 1级文件系统函数
- mkdir
- create
- rmdir
- link
- unlink
- symlink
- readlink
- 2级文件系统函数
- open
- Iseek
- close
- read
- write
- opendir
- readdir
- 3级文件系统函数
- 挂载算法
- 卸载算法
- 交叉挂载点
- 文件保护
- 实际uid和有效uid
- 文件锁定
时间戳转换为任意可读的日期格式
unix时间戳的数据类型,是32位(4字节)的无符号数,可以表示的大致时间范围是1970-2038
为了避免"时间回归"bug,有的地方已经开始用64位(8字节)的无符号数,来表示系统时间
<time.h>
time_t
通过sizeof,在本人电脑上是8字节,long是4字节,long long 是8字节。
获取unix时间戳
time_t time(time_t *seconds)time_t curtime; curtime = time(NULL); or time(curtime) printf("%ld\n",curtime);
char *ctime(const time_t *timer)
该函数返回一个字符串,包含了可读格式的日期和时间信息。
注意传入参数是指针。
格式固定,英文输出,星期,月份,日期,时:分:秒,年份
字符串结尾自带 '\n' ,不够灵活
struct tm *localtime(const time_t *timer)
传入指针,返回结构体指针struct tm { int tm_sec; /* 秒,范围从 0 到 59 */ int tm_min; /* 分,范围从 0 到 59 */ int tm_hour; /* 小时,范围从 0 到 23 */ int tm_mday; /* 一月中的第几天,范围从 1 到 31 */ int tm_mon; /* 月份,范围从 0 到 11 */ int tm_year; /* 自 1900 起的年数 */ int tm_wday; /* 一周中的第几天,范围从 0 到 6 */ int tm_yday; /* 一年中的第几天,范围从 0 到 365 */ int tm_isdst; /* 夏令时 */ };虽然可以自行输出结构体里的成员,达到灵活输出日期的效果,但是time.h还有个格式化输出神器。
size_t strftime(char *str, size_t maxsize, const char *format, const struct tm *timeptr)
format如下:它们是区分大小写的
%a 星期几的简写
%A 星期几的全称
%b 月分的简写
%B 月份的全称
%c 标准的日期的时间串
%C 年份的后两位数字
%d 十进制表示的每月的第几天
%D 月/天/年
%e 在两字符域中,十进制表示的每月的第几天
%F 年-月-日
%g 年份的后两位数字,使用基于周的年
%G 年分,使用基于周的年
%h 简写的月份名
%H 24小时制的小时
%I 12小时制的小时
%j 十进制表示的每年的第几天
%m 十进制表示的月份
%M 十时制表示的分钟数
%n 新行符
%p 本地的AM或PM的等价显示
%r 12小时的时间
%R 显示小时和分钟:hh:mm
%S 十进制的秒数
%t 水平制表符
%T 显示时分秒:hh:mm:ss
%u 每周的第几天,星期一为第一天 (值从0到6,星期一为0)
%U 第年的第几周,把星期日做为第一天(值从0到53)
%V 每年的第几周,使用基于周的年
%w 十进制表示的星期几(值从0到6,星期天为0)
%W 每年的第几周,把星期一做为第一天(值从0到53)
%x 标准的日期串
%X 标准的时间串
%y 不带世纪的十进制年份(值从0到99)
%Y 带世纪部分的十进制年份
%z,%Z 时区名称,如果不能得到时区名称则返回空字符。
%% 百分号void format_time(time_t arg){ char buf[64]; struct tm *ptm = localtime(&arg); strftime(buf,64,"%F %T",ptm); printf("%s\n",buf); } 想要灵活输出,修改format即可 "%F %R" 2021-10-17 17:15 "%F %T" 2021-10-17 17:15:10 "%Y年%m月%e日 %H:%M:%S" 2021年10月17日 17:15:10

 浙公网安备 33010602011771号
浙公网安备 33010602011771号