用尽洪荒之力学习Flask源码
app.run()
werkzeug
@app.route('/')
Context
Local
LocalStack
LocalProxy
Context Create
Stack push
Stack pop
Request
Response
Config
一直想做源码阅读这件事,总感觉难度太高时间太少,可望不可见。最近正好时间充裕,决定试试做一下,并记录一下学习心得。
首先说明一下,本文研究的Flask版本是0.12。
首先做个小示例,在pycharm新建flask项目"flask_source"后,默认创建项目入口"flask_source.py"文件。
运行该文件,在浏览器上访问 http://127.0.0.1:5000/上可以看到“hello,world"内容。这是flask_source.py源码:
#源码样例-1
from flask import Flask
app = Flask(__name__)
@app.route('/')
def hello_world():
return 'Hello World!'
if __name__ == '__main__':
app.run()
本篇博文的目标:阅读flask源码了解flask服务器启动后,用户访问http://127.0.0.1:5000/后浏览“Hello World"这个过程Flask的工作原理及代码框架。
WSGI
WSGI,全称 Web Server Gateway Interface,或者 Python Web Server Gateway Interface ,是基于 Python 定义的 Web 服务器和 Web 应用程序或框架之间的一种简单而通用的接口。WSGI接口的作用是确保HTTP请求能够转化成python应用的一个功能调用,这也就是Gateway的意义所在,网关的作用就是在协议之前进行转换。
WSGI接口中有一个非常明确的标准,每个Python Web应用必须是可调用callable的对象且返回一个iterator,并实现了app(environ, start_response) 的接口,server 会调用 application,并传给它两个参数:environ 包含了请求的所有信息,start_response 是 application 处理完之后需要调用的函数,参数是状态码、响应头部还有错误信息。引用代码示例:
#源码样例-2
# 1. 可调用对象是一个函数
def application(environ, start_response):
response_body = 'The request method was %s' % environ['REQUEST_METHOD']
# HTTP response code and message
status = '200 OK'
# 应答的头部是一个列表,每对键值都必须是一个 tuple。
response_headers = [('Content-Type', 'text/plain'),
('Content-Length', str(len(response_body)))]
# 调用服务器程序提供的 start_response,填入两个参数
start_response(status, response_headers)
# 返回必须是 iterable
return [response_body]
#2. 可调用对象是一个类实例
class AppClass:
"""这里的可调用对象就是 AppClass 的实例,使用方法类似于:
app = AppClass()
for result in app(environ, start_response):
do_somthing(result)
"""
def __init__(self):
pass
def __call__(self, environ, start_response):
status = '200 OK'
response_headers = [('Content-type', 'text/plain')]
self.start(status, response_headers)
yield "Hello world!\n"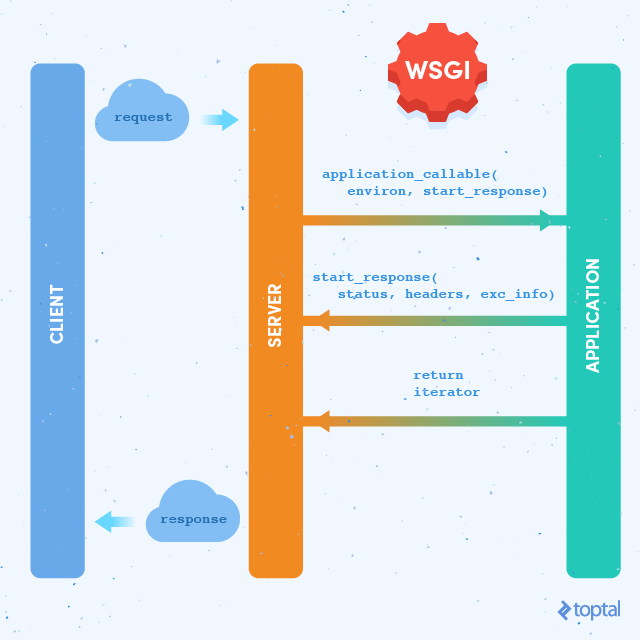
如上图所示,Flask框架包含了与WSGI Server通信部分和Application本身。Flask Server本身也包含了一个简单的WSGI Server(这也是为什么运行flask_source.py可以在浏览器访问的原因)用以开发测试使用。在实际的生产部署中,我们将使用apache、nginx+Gunicorn等方式进行部署,以适应性能要求。
app.run()
下图是服务器启动和处理请求的流程图,本节从分析这个图开始:
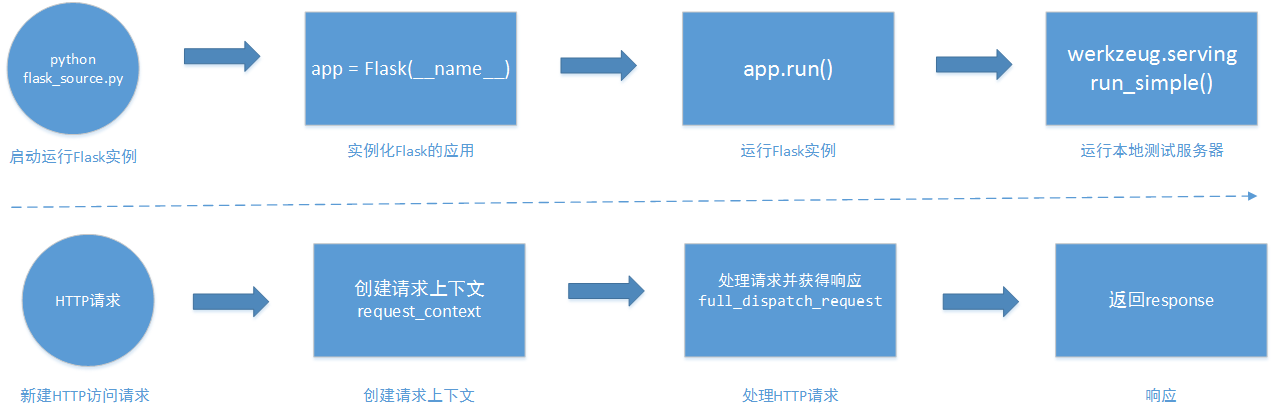
flask的核心组件有两个Jinjia2和werkzeug。
Jinjia2是一个基于python实现的模板引擎,提供对于HTML的页面解释,当然它的功能非常丰富,可以结合过滤器、集成、变量、流程逻辑支持等作出非常简单又很酷炫的的web出来。Flask类实例运行会创造一个Jinjia的环境。
在本文使用的样例中,我们是直接返回"Hello, world"字符串生成响应,因此本文将不详细介绍Jinjia2引擎,但不否认Jinjia2对于Flask非常重要也非常有用,值得重点学习。不过在源码学习中重点看的是werkzeug。
werkzeug
werkzeug是基于python实现的WSGI的工具组件库,提供对HTTP请求和响应的支持,包括HTTP对象封装、缓存、cookie以及文件上传等等,并且werkzeug提供了强大的URL路由功能。具体应用到Flask中:
- Flask使用werkzeug库中的Request类和Response类来处理HTTP请求和响应
- Flask应用使用werkzeug库中的Map类和Rule类来处理URL的模式匹配,每一个URL模式对应一个Rule实例,这些Rule实例最终会作为参数传递给Map类构造包含所有URL模式的一个“地图”。
- Flask使用SharedDataMiddleware来对静态内容的访问支持,也即是static目录下的资源可以被外部,
Flask的示例运行时将与werkzeug进行大量交互:
#源码样例-3
def run(self, host=None, port=None, debug=None, **options):
from werkzeug.serving import run_simple
if host is None:
host = '127.0.0.1'
if port is None:
server_name = self.config['SERVER_NAME']
if server_name and ':' in server_name:
port = int(server_name.rsplit(':', 1)[1])
else:
port = 5000
if debug is not None:
self.debug = bool(debug)
options.setdefault('use_reloader', self.debug)
options.setdefault('use_debugger', self.debug)
try:
run_simple(host, port, self, **options)
finally:
# reset the first request information if the development server
# reset normally. This makes it possible to restart the server
# without reloader and that stuff from an interactive shell.
self._got_first_request = False排除设置host、port、debug模式这些参数操作以外,我们重点关注第一句函数from werkzeug.serving import run_simple。
基于wekzeug,可以迅速启动一个WSGI应用,官方文档 上有详细的说明,感兴趣的同学可以自行研究。我们继续分析Flask如何与wekzeug调用。
Flask调用run_simple共传入5个参数,分别是host=127.0.0.1, port=5001,self=app,use_reloader=False,use_debugger=False。按照上述代码默认启动的话,在run_simple函数中,我们执行了以下的代码:
#源码样例-4
def inner():
try:
fd = int(os.environ['WERKZEUG_SERVER_FD'])
except (LookupError, ValueError):
fd = None
srv = make_server(hostname, port, application, threaded,
processes, request_handler,
passthrough_errors, ssl_context,
fd=fd)
if fd is None:
log_startup(srv.socket)
srv.serve_forever()上述的代码主要的工作是启动WSGI server并监听指定的端口。
WSGI server启动之后,如果收到新的请求,它的监听在serving.py的run_wsgi中,执行的代码如下:
#源码样例-5
def execute(app):
application_iter = app(environ, start_response)
try:
for data in application_iter:
write(data)
if not headers_sent:
write(b'')
finally:
if hasattr(application_iter, 'close'):
application_iter.close()
application_iter = None还记得上面介绍WSGI的内容时候强调的python web实现时需要实现的一个WSGI标准接口,特别是源码样例-2中的第二个参考样例实现,Flask的实现与之类似,当服务器(gunicorn/uwsgi…)接收到HTTP请求时,它通过werkzeug再execute函数中通过application_iter = app(environ, start_response)调用了Flask应用实例app(在run_simple中传进去的),实际上调用的是Flask类的__call__方法,因此Flask处理HTTP请求的流程将从__call__开始,代码如下:
#源码样例-6
def __call__(self, environ, start_response):
"""Shortcut for :attr:`wsgi_app`."""
return self.wsgi_app(environ, start_response)我们来看一下wsgi_app这个函数做了什么工作:
#源码样例-7
def wsgi_app(self, environ, start_response):
ctx = self.request_context(environ)
ctx.push()
error = None
try:
try:
response = self.full_dispatch_request()
except Exception as e:
error = e
response = self.handle_exception(e)
return response(environ, start_response)
finally:
if self.should_ignore_error(error):
error = None
ctx.auto_pop(error)在Flask的源码注释中,开发者显著地标明"The actual WSGI application.",这个函数的工作流程包括:
ctx = self.request_context(environ)创建请求上下文,并把它推送到栈中,在“上下文”章节我们会介绍其数据结构。response = self.full_dispatch_request()处理请求,通过flask的路由寻找对应的视图函数进行处理,会在下一章介绍这个函数- 通过try…except封装处理步骤2的处理函数,如果有问题,抛出500错误。
ctx.auto_pop(error)当前请求退栈。
@app.route('/')
Flask路由的作用是用户的HTTP请求对应的URL能找到相应的函数进行处理。
@app.route('/')通过装饰器的方式为对应的视图函数指定URL,可以一对多,即一个函数对应多个URL。
Flask路由的实现时基于werkzeug的URL Routing功能,因此在分析Flask的源码之前,首先学习一下werkzeug是如何处理路由的。
werkzeug有两类数据结构:Map和Rule:
- Map,主要作用是提供ImmutableDict来存储URL的Rule实体。
- Rule,代表着URL与endpoint一对一匹配的模式规则。
举例说明如下,假设在werkzeug中设置了如下的路由,当用户访问http://myblog.com/,werkzeug会启用别名为blog/index的函数来处理用户请求。
#源码样例-8
from werkzeug.routing import Map, Rule, NotFound, RequestRedirect
url_map = Map([
Rule('/', endpoint='blog/index'),
Rule('/<int:year>/', endpoint='blog/archive'),
Rule('/<int:year>/<int:month>/', endpoint='blog/archive'),
Rule('/<int:year>/<int:month>/<int:day>/', endpoint='blog/archive'),
Rule('/<int:year>/<int:month>/<int:day>/<slug>',
endpoint='blog/show_post'),
Rule('/about', endpoint='blog/about_me'),
Rule('/feeds/', endpoint='blog/feeds'),
Rule('/feeds/<feed_name>.rss', endpoint='blog/show_feed')
])
def application(environ, start_response):
urls = url_map.bind_to_environ(environ)
try:
endpoint, args = urls.match()
except HTTPException, e:
return e(environ, start_response)
start_response('200 OK', [('Content-Type', 'text/plain')])
return ['Rule points to %r with arguments %r' % (endpoint, args)]更多关于werkzeug路由的细节可以看官方文档。
在上面的示例中,werkzeug完成了url与endpoint的匹配,endpoint与视图函数的匹配将由Flask来完成,Flask通过装饰器的方式来包装app.route,实际工作函数是add_url_rule,其工作流程如下:
- 处理endpoint和构建methods,methods默认是GET和OPTIONS,即默认处理的HTTP请求是GET/OPTIONS方式;
self.url_map.add(rule)更新url_map,本质是更新werkzeug的url_mapself.view_functions[endpoint] = view_func更新view_functions,更新endpoint和视图函数的匹配,两者必须一一匹配,否则报错AssertionError。
#源码样例-9
def add_url_rule(self, rule, endpoint=None, view_func=None, **options):
if endpoint is None:
endpoint = _endpoint_from_view_func(view_func)
options['endpoint'] = endpoint
methods = options.pop('methods', None)
if methods is None:
methods = getattr(view_func, 'methods', None) or ('GET',)
if isinstance(methods, string_types):
raise TypeError('Allowed methods have to be iterables of strings, '
'for example: @app.route(…, methods=["POST"])')
methods = set(item.upper() for item in methods)
required_methods = set(getattr(view_func, 'required_methods', ()))
provide_automatic_options = getattr(view_func,
'provide_automatic_options', None)
if provide_automatic_options is None:
if 'OPTIONS' not in methods:
provide_automatic_options = True
required_methods.add('OPTIONS')
else:
provide_automatic_options = False
methods |= required_methods
rule = self.url_rule_class(rule, methods=methods, **options)
rule.provide_automatic_options = provide_automatic_options
self.url_map.add(rule)
if view_func is not None:
old_func = self.view_functions.get(endpoint)
if old_func is not None and old_func != view_func:
raise AssertionError('View function mapping is overwriting an '
'existing endpoint function: %s' % endpoint)
self.view_functions[endpoint] = view_func设置好了Flask的路由之后,接下来再看看在上一章节中当用户请求进来后是如何匹配请求和视图函数的。
用户请求进来后,Flask类的wsgi_app函数进行处理,其调用了full_dispatch_request函数进行处理:
#源码样例-10
def full_dispatch_request(self):
self.try_trigger_before_first_request_functions()
try:
request_started.send(self)
rv = self.preprocess_request()
if rv is None:
rv = self.dispatch_request()
except Exception as e:
rv = self.handle_user_exception(e)
return self.finalize_request(rv)讲一下这个处理的逻辑:
self.try_trigger_before_first_request_functions()触发第一次请求之前需要处理的函数,只会执行一次。self.preprocess_request()触发用户设置的在请求处理之前需要执行的函数,这个可以通过@app.before_request来设置,使用的样例可以看我之前写的博文中的示例-11rv = self.dispatch_request()核心的处理函数,包括了路由的匹配,下面会展开来讲rv = self.handle_user_exception(e)处理异常return self.finalize_request(rv),将返回的结果转换成Response对象并返回。
接下来我们看dispatch_request函数:
#源码样例-11
def dispatch_request(self):
req = _request_ctx_stack.top.request
if req.routing_exception is not None:
self.raise_routing_exception(req)
rule = req.url_rule
if getattr(rule, 'provide_automatic_options', False) \
and req.method == 'OPTIONS':
return self.make_default_options_response()
return self.view_functions[rule.endpoint](**req.view_args)处理的逻辑如下:
req = _request_ctx_stack.top.request获得请求对象,并检查有效性。- 对于请求的方法进行判断,如果HTTP请求时OPTIONS类型且用户未设置provide_automatic_options=False,则进入默认的OPTIONS请求回应,否则请求endpoint匹配的函数执行,并返回内容。
在上述的处理逻辑中,Flask从请求上下文中获得匹配的rule,这是如何实现的呢,请看下一节“上下文”。
Context
纯粹的上下文Context理解可以参见知乎的这篇文章,可以认为上下文就是程序的工作环境。
Flask的上下文较多,用途也不一致,具体包括:
| 对象 | 上下文类型 | 说明 |
|---|---|---|
| current_app | AppContext | 当前的应用对象 |
| g | AppContext | 处理请求时用作临时存储的对象,当前请求结束时被销毁 |
| request | RequestContext | 请求对象,封装了HTTP请求的额内容 |
| session | RequestContext | 用于存储请求之间需要共享的数据 |
引用博文Flask 的 Context 机制:
App Context 代表了“应用级别的上下文”,比如配置文件中的数据库连接信息;Request Context 代表了“请求级别的上下文”,比如当前访问的 URL。这两种上下文对象的类定义在 flask.ctx 中,它们的用法是推入 flask.globals 中创建的 _app_ctx_stack 和 _request_ctx_stack 这两个单例 Local Stack 中。因为 Local Stack 的状态是线程隔离的,而 Web 应用中每个线程(或 Greenlet)同时只处理一个请求,所以 App Context 对象和 Request Context 对象也是请求间隔离的。
在深入分析上下文源码之前,需要特别介绍一下Local、LocalProxy和LocalStack。这是由werkzeug的locals模块提供的数据结构:
Local
#源码样例-12
class Local(object):
__slots__ = ('__storage__', '__ident_func__')
def __init__(self):
object.__setattr__(self, '__storage__', {})
object.__setattr__(self, '__ident_func__', get_ident)
def __getattr__(self, name):
try:
return self.__storage__[self.__ident_func__()][name]
except KeyError:
raise AttributeError(name)
def __setattr__(self, name, value):
ident = self.__ident_func__()
storage = self.__storage__
try:
storage[ident][name] = value
except KeyError:
storage[ident] = {name: value}Local维护了两个对象:1.stroage,字典;2.idente_func, 调用的是thread的get_indent方法,从_thread内置模块导入,得到的线程号。
注意,这里的__stroage__的数据组织形式是:__storage__ ={ident1:{name1:value1},ident2:{name2:value2},ident3:{name3:value3}}所以取值时候__getattr__通过self.__storage__[self.__ident_func__()][name]获得。
这种设计确保了Local类实现了类似 threading.local 的效果——多线程或者多协程情况下全局变量的相互隔离。
LocalStack
一种基于栈的数据结构,其本质是维护了一个Locals对象的代码示例如下:
#源码样例-13
class LocalStack(object):
def __init__(self):
self._local = Local()
def push(self, obj):
rv = getattr(self._local, 'stack', None)
if rv is None:
self._local.stack = rv = []
rv.append(obj)
return rv
def pop(self):
stack = getattr(self._local, 'stack', None)
if stack is None:
return None
elif len(stack) == 1:
release_local(self._local)
return stack[-1]
else:
return stack.pop()
@property
def top(self):
"""The topmost item on the stack. If the stack is empty,
`None` is returned.
"""
try:
return self._local.stack[-1]
except (AttributeError, IndexError):
return None
>>> ls = LocalStack()
>>> ls.push(42)
>>> ls.top
42
>>> ls.push(23)
>>> ls.top
23
>>> ls.pop()
23
>>> ls.top
42LocalProxy
典型的代理模式实现,在构造时接受一个callable参数,这个参数被调用后返回对象是一个Thread Local的对象,对一个LocalProxy对象的所有操作,包括属性访问、方法调用都会转发到Callable参数返回的对象上。LocalProxy 的一个使用场景是 LocalStack 的 call 方法。比如 my_local_stack 是一个 LocalStack 实例,那么 my_local_stack() 能返回一个 LocalProxy 对象,这个对象始终指向 my_local_stack 的栈顶元素。如果栈顶元素不存在,访问这个 LocalProxy 的时候会抛出 RuntimeError。
LocalProxy的初始函数:
#源码样例-14
def __init__(self, local, name=None):
object.__setattr__(self, '_LocalProxy__local', local)
object.__setattr__(self, '__name__', name)LocalProxy与LocalStack可以完美地结合起来,首先我们注意LocalStack的__call__方法:
#源码样例-15
def __call__(self):
def _lookup():
rv = self.top
if rv is None:
raise RuntimeError('object unbound')
return rv
return LocalProxy(_lookup)假设创建一个LocalStack实例:
#源码样例-16
_response_local = LocalStack()
response = _response_local()然后,response就成了一个LocalProxy对象,能操作LocalStack的栈顶元素,该对象有两个元素:_LocalProxy__local(等于_lookup函数)和__name__(等于None)。
这种设计简直碉堡了!!!!
回到Flask的上下文处理流程,这里引用Flask的核心机制!关于请求处理流程和上下文的一张图进行说明:

Context Create
#源码样例-17
def _lookup_req_object(name):
top = _request_ctx_stack.top
if top is None:
raise RuntimeError(_request_ctx_err_msg)
return getattr(top, name)
def _lookup_app_object(name):
top = _app_ctx_stack.top
if top is None:
raise RuntimeError(_app_ctx_err_msg)
return getattr(top, name)
def _find_app():
top = _app_ctx_stack.top
if top is None:
raise RuntimeError(_app_ctx_err_msg)
return top.app
# context locals
_request_ctx_stack = LocalStack()
_app_ctx_stack = LocalStack()
current_app = LocalProxy(_find_app)
request = LocalProxy(partial(_lookup_req_object, 'request'))
session = LocalProxy(partial(_lookup_req_object, 'session'))
g = LocalProxy(partial(_lookup_app_object, 'g'))从源码可以了解到以下内容:
*. Flask维护的request全局变量_request_ctx_stack 和app全局变量_app_ctx_stack 均为LocalStack结构,这两个全局变量均是Thread local的栈结构
*. request、session每次都是调用_request_ctx_stack栈头部的数据来获取和保存里面的请求上下文信息。
为什么需要LocalProxy对象,而不是直接引用LocalStack的值?引用flask 源码解析:上下文的介绍:
这是因为 flask 希望在测试或者开发的时候,允许多 app 、多 request 的情况。而 LocalProxy 也是因为这个才引入进来的!我们拿 current_app = LocalProxy(_find_app) 来举例子。每次使用 current_app 的时候,他都会调用 _find_app 函数,然后对得到的变量进行操作。如果直接使用 current_app = _find_app() 有什么区别呢?区别就在于,我们导入进来之后,current_app 就不会再变化了。如果有多 app 的情况,就会出现错误。
原文示例代码:
#源码样例-18
from flask import current_app
app = create_app()
admin_app = create_admin_app()
def do_something():
with app.app_context():
work_on(current_app)
with admin_app.app_context():
work_on(current_app)我的理解是:Flask考虑了一些极端的情况出现,例如两个Flask APP通过WSGI的中间件组成一个应用,两个APP同时运行的情况,因此需要动态的更新当前的应用上下文,而_app_ctx_stack每次都指向栈的头元素,并且更新头元素(如果存在删除再创建)来确保当前运行的上下文(包括请求上下文和应用上下文)的准确。
Stack push
在本文第二章节介绍Flask运行流程的内容时,我们介绍了wsig_app函数,这个函数是处理用户的HTTP请求的,其中有两句ctx = self.request_context(environ)和ctx.push()两句。
本质上实例了一个RequestContext,通过WSGI server传过来的environ来构建一个请求的上下文。源码:
#源码样例-19
class RequestContext(object):
def __init__(self, app, environ, request=None):
self.app = app
if request is None:
request = app.request_class(environ)
self.request = request
self.url_adapter = app.create_url_adapter(self.request)
self.flashes = None
self.session = None
self.preserved = False
self._preserved_exc = None
self._after_request_functions = []
self.match_request()
def push(self):
top = _request_ctx_stack.top
if top is not None and top.preserved:
top.pop(top._preserved_exc)
app_ctx = _app_ctx_stack.top
if app_ctx is None or app_ctx.app != self.app:
app_ctx = self.app.app_context()
app_ctx.push()
self._implicit_app_ctx_stack.append(app_ctx)
else:
self._implicit_app_ctx_stack.append(None)
if hasattr(sys, 'exc_clear'):
sys.exc_clear()
_request_ctx_stack.push(self)
self.session = self.app.open_session(self.request)
if self.session is None:
self.session = self.app.make_null_session()Flask的上下文入栈的操作在RequestContext类的push函数:
- 清空_request_ctx_stack栈;
- 确保当前的Flask实例推入_app_ctx_stack栈;
- 根据WSGI服务器传入的environ构建了request(在__init__函数完成),将该request推入_request_ctx_stack栈;
- 创建session对象。
Stack pop
wsig_app函数在完成上一小节上下文入栈之后进行请求分发,进行路由匹配寻找视图函数处理请求,并生成响应,此时用户可以在应用程序中import上下文对象作为全局变量进行访问:
from flask import request,session,request,g请求完成后,同样在源码样例-7wsgi_app函数中可以看到上下文出栈的操作ctx.auto_pop(error),auto_pop函数只弹出请求上下文,应用上下文仍然存在以应对下次的HTTP请求。至此,上下文的管理和操作机制介绍完毕。
Request
接下来继续学习Flask的请求对象。Flask是基于WSGI服务器werkzeug传来的environ参数来构建请求对象的,检查发现environ传入的是一个字典,在本文的经典访问样例(返回“Hello, World")中,传入的environ包含的信息包括
"wsgi.multiprocess":"False"
"SERVER_SOFTWARE":"Werkzeug/0.11.15"
"SCRIPT_NAME":""
"REQUEST_METHOD":"GET"
"PATH_INFO":"/favicon.ico"
"SERVER_PROTOCOL":"HTTP/1.1"
"QUERY_STRING":""
"werkzeug.server.shutdown":"<function shutdown_server at 0x0000000003F4FAC8>"
"CONTENT_LENGTH":""
"HTTP_USER_AGENT":"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:55.0) Gecko/20100101 Firefox/55.0"
"HTTP_CONNECTION":"keep-alive"
"SERVER_NAME":"127.0.0.1"
"REMOTE_PORT":"12788"
"wsgi.url_scheme":"http"
"SERVER_PORT":"5000"
"wsgi.input":"<socket._fileobject object at 0x0000000003E18408>"
"HTTP_HOST":"127.0.0.1:5000"
"wsgi.multithread":"False"
"HTTP_ACCEPT":"text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8"
"wsgi.version":"(1, 0)"
"wsgi.run_once":"False"
"wsgi.errors":"<open file '<stderr>', mode 'w' at 0x0000000001DD2150>"
"REMOTE_ADDR":"127.0.0.1"
"HTTP_ACCEPT_LANGUAGE":"zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3"
"CONTENT_TYPE":""
"HTTP_ACCEPT_ENCODING":"gzip, deflate"Flask需要将WSGI server传进来的上述的字典改造成request对象,它是通过调用werkzeug.wrappers.Request类来进行构建。Request没有构造方法,且Request继承了多个类,在
#源码样例-20
class Request(BaseRequest, AcceptMixin, ETagRequestMixin,
UserAgentMixin, AuthorizationMixin,
CommonRequestDescriptorsMixin):
"""Full featured request object implementing the following mixins:
- :class:`AcceptMixin` for accept header parsing
- :class:`ETagRequestMixin` for etag and cache control handling
- :class:`UserAgentMixin` for user agent introspection
- :class:`AuthorizationMixin` for http auth handling
- :class:`CommonRequestDescriptorsMixin` for common headers
"""这里有多重继承,有多个类负责处理request的不同内容,python的多重继承按照从下往上,从左往右的入栈出栈顺序进行继承,且看构造方法的参数匹配。在Request的匹配中只有BaseRequest具有构造函数,其他类只有功能函数,这种设计模式很特别,但是跟传统的设计模式不太一样,传统的设计模式要求是多用组合少用继承多用拓展少用修改,这种利用多重继承来达到类功能组合的设计模式称为Python的mixin模式,感觉的同学可以看看Python mixin模式,接下来重点关注BaseRequest。
底层的Request功能均由werkzeug来实现,这边不再一一赘述。
Response
在本文的源码样例-1中,访问URL地址“http://127.0.0.1” 后,查看返回的response,除了正文文本"Hello, world"外,我们还可以得到一些额外的信息,通过Chrome调试工具可以看到:
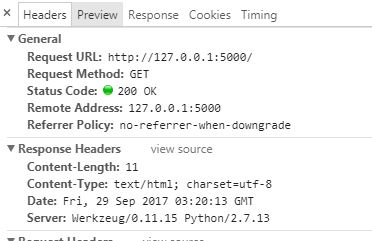
以上的信息都是通过flask服务器返回,因此,在视图函数返回“Hello,World”的响应后,Flask对响应做了进一步的包装。本章节分析一下Flask如何封装响应信息。
在本文的源码样例-10中用户的请求由full_dispatch_request函数进行处理,其调用了视图函数index()返回得到rv='Hello, World',接下来调用了finalize_request函数进行封装,得到其源码如下:
#源码样例-21
def finalize_request(self, rv, from_error_handler=False):
response = self.make_response(rv)
try:
response = self.process_response(response)
request_finished.send(self, response=response)
except Exception:
if not from_error_handler:
raise
self.logger.exception('Request finalizing failed with an '
'error while handling an error')
return response
def make_response(self, rv):
status_or_headers = headers = None
if isinstance(rv, tuple):
rv, status_or_headers, headers = rv + (None,) * (3 - len(rv))
if rv is None:
raise ValueError('View function did not return a response')
if isinstance(status_or_headers, (dict, list)):
headers, status_or_headers = status_or_headers, None
if not isinstance(rv, self.response_class):
if isinstance(rv, (text_type, bytes, bytearray)):
rv = self.response_class(rv, headers=headers,
status=status_or_headers)
headers = status_or_headers = None
else:
rv = self.response_class.force_type(rv, request.environ)
if status_or_headers is not None:
if isinstance(status_or_headers, string_types):
rv.status = status_or_headers
else:
rv.status_code = status_or_headers
if headers:
rv.headers.extend(headers)
return rv
def process_response(self, response):
ctx = _request_ctx_stack.top
bp = ctx.request.blueprint
funcs = ctx._after_request_functions
if bp is not None and bp in self.after_request_funcs:
funcs = chain(funcs, reversed(self.after_request_funcs[bp]))
if None in self.after_request_funcs:
funcs = chain(funcs, reversed(self.after_request_funcs[None]))
for handler in funcs:
response = handler(response)
if not self.session_interface.is_null_session(ctx.session):
self.save_session(ctx.session, response)
return response返回信息的封装顺序如下:
response = self.make_response(rv):根据视图函数返回值生成response对象。response = self.process_response(response):在response发送给WSGI服务器钱对于repsonse进行后续处理,并执行当前请求的后续hooks函数。request_finished.send(self, response=response)向特定的订阅者发送响应信息。关于Flask的信号机制可以学习一下这篇博文,这里不再展开详细说明。
make_response该函数可以根据不同的输入得到不同的输出,即参数rv的类型是多样化的,包括:
- str/unicode,如
源码样例-1所示直接返回str后,将其设置为body主题后,调用response_class生成其他响应信息,例如状态码、headers信息。 - tuple 通过构建status_or_headers和headers来进行解析。在
源码样例-1可以修改为返回return make_response(('hello,world!', 202, None)),得到返回码也就是202,即可以在视图函数中定义返回状态码和返回头信息。 - WSGI方法:这个用法没有找到示例,不常见。
- response类实例。视图函数可以直接通过调用make_response接口,该接口可以提供给用户在视图函数中设计自定制的响应,可以参见我之前写的博文lask自带的常用组件介绍, 相较于tuple类型,response能更加丰富和方便地订制响应。
process_response处理了两个逻辑:
- 将用户定义的
after_this_request方法进行执行,同时检查了是否在blueprint中定义了after_request和after_app_request,如果存在,将其放在执行序列; - 保存sesseion。
上述的源码是flask对于response包装的第一层外壳,去除这个壳子可以看到,flask实际上调用了Response类对于传入的参数进行包装,其源码如样例22:
#源码样例-22
class Response(ResponseBase):
"""The response object that is used by default in Flask. Works like the
response object from Werkzeug but is set to have an HTML mimetype by
default. Quite often you don't have to create this object yourself because
:meth:`~flask.Flask.make_response` will take care of that for you.
If you want to replace the response object used you can subclass this and
set :attr:`~flask.Flask.response_class` to your subclass.
"""
default_mimetype = 'text/html'嗯,基本上 没啥内容,就是继承了werkzeug.wrappers:Response,注意上面的类注释,作者明确建议使用flask自带的make_response接口来定义response对象,而不是重新实现它。werkzeug实现Response的代码参见教程 这里就不再展开分析了。
Config
Flask配置导入对于其他项目的配置导入有很好的借鉴意义,所以我这里还是作为一个单独的章节进行源码学习。Flask常用的四种方式进行项目参数的配置,如样例-22所示:
#源码样例-23
#Type1: 直接配置参数
app.config['SECRET_KEY'] = 'YOUCANNOTGUESSME'
#Type2: 从环境变量中获得配置文件名并导入配置参数
export MyAppConfig=/path/to/settings.cfg #linux
set MyAppConfig=d:\settings.cfg#不能立即生效,不建议windows下通过这种方式获得环境变量。
app.config.from_envvar('MyAppConfig')
#Type3: 从对象中获得配置
class Config(object):
DEBUG = False
TESTING = False
DATABASE_URI = 'sqlite://:memory:'
class ProductionConfig(Config):
DATABASE_URI = 'mysql://user@localhost/foo'
app.config.from_object(ProductionConfig)
print app.config.get('DATABASE_URI')
#Type4: 从文件中获得配置参数
# default_config.py
HOST = 'localhost'
PORT = 5000
DEBUG = True
# flask中使用
app.config.from_pyfile('default_config.py')Flask已经默认自带的配置包括:
['JSON_AS_ASCII', 'USE_X_SENDFILE', 'SESSION_COOKIE_PATH', 'SESSION_COOKIE_DOMAIN', 'SESSION_COOKIE_NAME', 'SESSION_REFRESH_EACH_REQUEST', 'LOGGER_HANDLER_POLICY', 'LOGGER_NAME', 'DEBUG', 'SECRET_KEY', 'EXPLAIN_TEMPLATE_LOADING', 'MAX_CONTENT_LENGTH', 'APPLICATION_ROOT', 'SERVER_NAME', 'PREFERRED_URL_SCHEME', 'JSONIFY_PRETTYPRINT_REGULAR', 'TESTING', 'PERMANENT_SESSION_LIFETIME', 'PROPAGATE_EXCEPTIONS', 'TEMPLATES_AUTO_RELOAD', 'TRAP_BAD_REQUEST_ERRORS', 'JSON_SORT_KEYS', 'JSONIFY_MIMETYPE', 'SESSION_COOKIE_HTTPONLY', 'SEND_FILE_MAX_AGE_DEFAULT', 'PRESERVE_CONTEXT_ON_EXCEPTION', 'SESSION_COOKIE_SECURE', 'TRAP_HTTP_EXCEPTIONS']
其中关于debug这个参数要特别的进行说明,当我们设置为app.config["DEBUG"]=True时候,flask服务启动后进入调试模式,在调试模式下服务器的内部错误会展示到web前台,举例说明:
#源码样例-24
app.config["DEBUG"]=True
@app.route('/')
def hello_world():
a=3/0
return 'Hello World!'打开页面我们会看到
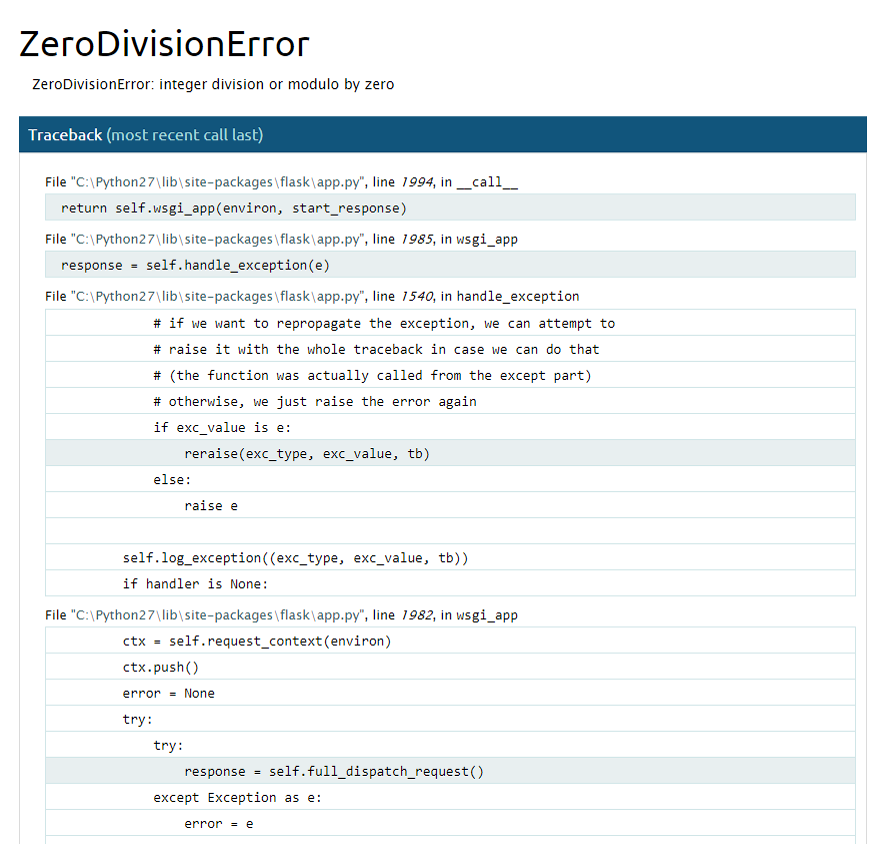
除了显示错误信息以外,Flask还支持从web中提供console进行调试(需要输入pin码),破解pin码很简单,这意味着用户可以对部署服务器执行任意的代码,所以如果Flask发布到生产环境,必须确保DEBUG=False。
嗯,有空再写一篇关于Flask的安全篇。另外,关于如何配置Flask参数让网站更加安全,可以参考这篇博文,写的很好。
接下来继续研究Flask源码中关于配置的部分。可以发现config是app的一个属性,而app是Flask类的一个示例,并且可以通过app.config["DEBUG"]=True来设置属性,可以大胆猜测config应该是一个字典类型的类属性变量,这一点在源码中验证了:
#源码样例-25
#: The configuration dictionary as :class:`Config`. This behaves
#: exactly like a regular dictionary but supports additional methods
#: to load a config from files.
self.config = self.make_config(instance_relative_config)我们进一步看看make_config函数的定义:
#源码样例-26
def make_config(self, instance_relative=False):
"""Used to create the config attribute by the Flask constructor.
The `instance_relative` parameter is passed in from the constructor
of Flask (there named `instance_relative_config`) and indicates if
the config should be relative to the instance path or the root path
of the application.
.. versionadded:: 0.8
"""
root_path = self.root_path
if instance_relative:
root_path = self.instance_path
return self.config_class(root_path, self.default_config)
config_class = Config其中有两个路径要选择其中一个作为配置导入的默认路径,这个用法在上面推荐的博文中用到过,感兴趣的看看,make_config真正功能是返回config_class的函数,而这个函数直接指向Config类,也就是说make_config返回的是Config类的实例。似乎这里面有一些设计模式在里面,后续再研究一下。记下来是Config类的定义:
#源码样例-27
class Config(dict):
def __init__(self, root_path, defaults=None):
dict.__init__(self, defaults or {})
self.root_path = root_path
root_path代表的是项目配置文件所在的目录。defaults是Flask默认的参数,用的是immutabledict数据结构,是dict的子类,其中default中定义为:
#源码样例-28
#: Default configuration parameters.
default_config = ImmutableDict({
'DEBUG': get_debug_flag(default=False),
'TESTING': False,
'PROPAGATE_EXCEPTIONS': None,
'PRESERVE_CONTEXT_ON_EXCEPTION': None,
'SECRET_KEY': None,
'PERMANENT_SESSION_LIFETIME': timedelta(days=31),
'USE_X_SENDFILE': False,
'LOGGER_NAME': None,
'LOGGER_HANDLER_POLICY': 'always',
'SERVER_NAME': None,
'APPLICATION_ROOT': None,
'SESSION_COOKIE_NAME': 'session',
'SESSION_COOKIE_DOMAIN': None,
'SESSION_COOKIE_PATH': None,
'SESSION_COOKIE_HTTPONLY': True,
'SESSION_COOKIE_SECURE': False,
'SESSION_REFRESH_EACH_REQUEST': True,
'MAX_CONTENT_LENGTH': None,
'SEND_FILE_MAX_AGE_DEFAULT': timedelta(hours=12),
'TRAP_BAD_REQUEST_ERRORS': False,
'TRAP_HTTP_EXCEPTIONS': False,
'EXPLAIN_TEMPLATE_LOADING': False,
'PREFERRED_URL_SCHEME': 'http',
'JSON_AS_ASCII': True,
'JSON_SORT_KEYS': True,
'JSONIFY_PRETTYPRINT_REGULAR': True,
'JSONIFY_MIMETYPE': 'application/json',
'TEMPLATES_AUTO_RELOAD': None,
})我们再看看Config的三个导入函数from_envvar,from_pyfile, from_object。from_envvar相当于在from_pyfile外面包了一层壳子,从环境变量中获得,其函数注释中也提到了这一点。而from_pyfile最终也是调用from_object。所以我们的重点是看from_object这个函数的细节。
from_pyfile源码中有一句特别难懂,如下。config_file是读取的文件头,file_name是文件名称。
exec (compile(config_file.read(), filename, 'exec'), d.__dict__)dict__是python的内置属性,包含了该对象(python万事万物都是对象)的属性变量。类的实例对象的__dict__只包括类实例后的变量,而类对象本身的__dict__还包括包括一些类内置属性和类变量clsvar以及构造方法__init。
再理解exec函数,exec语句用来执行存储在代码对象、字符串、文件中的Python语句,eval语句用来计算存储在代码对象或字符串中的有效的Python表达式,而compile语句则提供了字节编码的预编译。:
exec(object[, globals[, locals]]) #内置函数
其中参数obejctobj对象可以是字符串(如单一语句、语句块),文件对象,也可以是已经由compile预编译过的代码对象,本文就是最后一种。参数globals是全局命名空间,用来指定执行语句时可以访问的全局命名空间;参数locals是局部命名空间,用来指定执行语句时可以访问的局部作用域的命名空间。按照这个解释,上述的语句其实是转化成了这个语法:
#源码样例-29
import types
var2=types.ModuleType("test")
exec("A='bb'",var2.__dict__)把配置文件中定义的参数写入到了定义为config Module类型的变量d的内置属性__dict__中。
再看看complie函数compile( str, file, type ),
compile语句是从type类型(包括’eval’: 配合eval使用,’single’: 配合单一语句的exec使用,’exec’: 配合多语句的exec使用)中将str里面的语句创建成代码对象。file是代码存放的地方,通常为”。compile语句的目的是提供一次性的字节码编译,就不用在以后的每次调用中重新进行编译了。
from_object源码中将输入的参数进行类型判断,如果是object类型的,则说明是通过from_pyfile中传过来的,只要遍历from_pyfile传输过来的d比变量的内置属性__dict__即可。如果输入的string类型,意味着这个是要从默认的config.py文件中导入,用户需要输入app.config.from_object("config")进行明确,这时候根据config直接导入config.py配置。
具体的源码细节如下:
#源码样例-30
def from_envvar(self, variable_name, silent=False):
rv = os.environ.get(variable_name)
if not rv:
if silent:
return False
raise RuntimeError('The environment variable %r is not set '
'and as such configuration could not be '
'loaded. Set this variable and make it '
'point to a configuration file' %
variable_name)
return self.from_pyfile(rv, silent=silent)
def from_pyfile(self, filename, silent=False):
filename = os.path.join(self.root_path, filename)
d = types.ModuleType('config')
d.__file__ = filename
try:
with open(filename) as config_file:
exec (compile(config_file.read(), filename, 'exec'), d.__dict__)
except IOError as e:
if silent and e.errno in (errno.ENOENT, errno.EISDIR):
return False
e.strerror = 'Unable to load configuration file (%s)' % e.strerror
raise
self.from_object(d)
return True
def from_object(self, obj):
"""Updates the values from the given object. An object can be of one
of the following two types:
- a string: in this case the object with that name will be imported
- an actual object reference: that object is used directly
Objects are usually either modules or classes. :meth:`from_object`
loads only the uppercase attributes of the module/class. A ``dict``
object will not work with :meth:`from_object` because the keys of a
``dict`` are not attributes of the ``dict`` class.
Example of module-based configuration::
app.config.from_object('yourapplication.default_config')
from yourapplication import default_config
app.config.from_object(default_config)
You should not use this function to load the actual configuration but
rather configuration defaults. The actual config should be loaded
with :meth:`from_pyfile` and ideally from a location not within the
package because the package might be installed system wide.
See :ref:`config-dev-prod` for an example of class-based configuration
using :meth:`from_object`.
:param obj: an import name or object
"""
if isinstance(obj, string_types):
obj = import_string(obj)
for key in dir(obj):
if key.isupper():
self[key] = getattr(obj, key)根据源码分析,from_envvar和from_pyfile两个函数的输入配置文件必须是可以执行的py文件,py文件中变量名必须是大写,只有这样配置变量参数才能顺利的导入到Flask中。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号