java8之Stream流处理
简介
Stream 流处理,首先要澄清的是 java8 中的 Stream 与 I/O 流 InputStream 和 OutputStream 是完全不同的概念。
Stream 机制是针对集合迭代器的增强。流允许你用声明式的方式处理数据集合(通过查询语句来表达,而不是临时编写一个实现)。
本文后半部分将拿 Stream 中查询语句与我们熟悉的 SQL 查询语句做一些类别,方便大家的理解和记忆。
创建对象流
创建对象流的三种方式:
- 由集合对象创建流。对支持流处理的对象调用 stream()。支持流处理的对象包括
Collection集合及其子类
List<Integer> list = Arrays.asList(1,2,3);
Stream<Integer> stream = list.stream();
- 由数组创建流。通过静态方法 Arrays.stream() 将数组转化为流(Stream)
IntStream stream = Arrays.stream(new int[]{3, 2, 1});
通过静态方法 Stream.of() ,但是底层其实还是调用 Arrays.stream()
Stream<Integer> stream = Stream.of(1, 2, 3);
注意:
还有两种比较特殊的流
- 空流:Stream.empty()
- 无限流:Stream.generate() 和 Stream.iterate()。可以配合 limit() 使用可以限制一下数量
// 接受一个 Supplier 作为参数
Stream.generate(Math::random).limit(10).forEach(System.out::println);
// 初始值是 0,新值是前一个元素值 + 2
Stream.iterate(0, n -> n + 2).limit(10).forEach(System.out::println);
流处理的特性
- 不存储数据
- 不会改变数据源
- 不可以重复使用
为了体现流的特性,我准备了一组对应的测试用例:
public class StreamFeaturesTest {
/**
* 流的简单例子
*/
@Test
public void test1() {
List<Integer> list = Stream.of(1, 2, 5, 9, 7, 3).filter(val-> val> 2).sorted().collect(Collectors.toList());
for (Integer item : list) {
System.out.println(item);
}
}
/**
* 流不会改变数据源
*/
@Test
public void test2() {
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
list.add(1);
Assert.assertEquals(3, list.stream().distinct().count());
Assert.assertEquals(4, list.size());
}
/**
* 流不可以重复使用
*/
@Test(expected = IllegalStateException.class)
public void test3() {
Stream<Integer> integerStream = Stream.of(1, 2, 3);
Stream<Integer> newStream = integerStream.filter(val -> val > 2);
integerStream.skip(1);
}
}
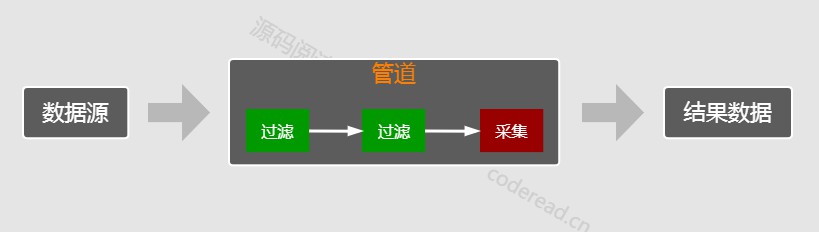
首先,test1() 向我们展示了流的一般用法,由下图可见,源数据流经管道,最后输出结果数据。
然后,我们先看 test3(),源数组产生的流对象 integerStream 在调用 filter() 之后,数据立即流向了 newStream。
正因为流“不保存数据”的特性,所以重复利用 integerStream 再次调用 skip(1) 方法,会抛出一个 IllegalStateException 的异常:
java.lang.IllegalStateException: stream has already been operated upon or closed
所以说流不存储数据,且流不可以重复使用。最后,我们来看 test2(),尽管我们对 list 对象生成的流 list.stream() 做了去重操作 distinct() ,但是并不影响源数据对象 list。
流处理的操作类型
Stream 的所有操作连起来组合成了管道,管道有两种操作:
第一种,中间操作(intermediate)。调用中间操作方法返回的是一个新的流对象。
第二种,终值操作(terminal)。在调用该方法后,将执行之前所有的中间操作,并返回结果。
流处理的执行顺序
为了更好地演示效果,我们首先要了解一下 Stream.peek() 方法, 这个方法和 Stream.forEach() 使用方法类似,都接受 Consumer 作为参数。
| 流操作方法 | 流操作类型 |
|---|---|
| peek() | 中间操作 |
| forEach() | 终值操作 |
| 所以,我们可以用 peek 来证明流的执行顺序。 | |
| 我们定义一个 Apple 对象: |
public class Apple {
private int id; // 编号
private String color; // 颜色
private int weight; // 重量
private String birthplace; // 产地
public Apple(int id, String color, int weight, String birthplace) {
this.id = id;
this.color = color;
this.weight = weight;
this.birthplace = birthplace;
}
// getter/setter 省略
}
然后创建多个苹果放到 appleStore 中
public class StreamTest {
private static final List<Apple> appleStore = Arrays.asList(
new Apple(1, "red", 500, "湖南"),
new Apple(2, "red", 100, "天津"),
new Apple(3, "green", 300, "湖南"),
new Apple(4, "green", 200, "天津"),
new Apple(5, "green", 100, "湖南")
);
public static void main(String[] args) {
appleStore.stream().filter(apple -> apple.getWeight() > 100)
.peek(apple -> System.out.println("通过第1层筛选 " + apple))
.filter(apple -> "green".equals(apple.getColor()))
.peek(apple -> System.out.println("通过第2层筛选 " + apple))
.filter(apple -> "湖南".equals(apple.getBirthplace()))
.peek(apple -> System.out.println("通过第3层筛选 " + apple))
.collect(Collectors.toList());
}
}
测试结果如下:
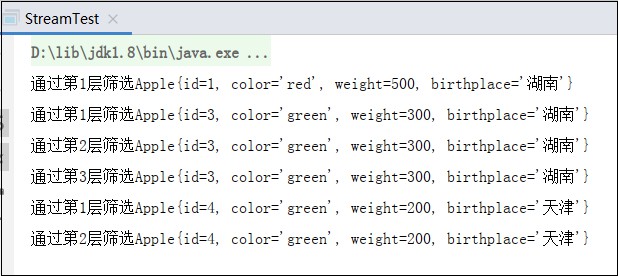
以上测试例子的执行顺序示意图:
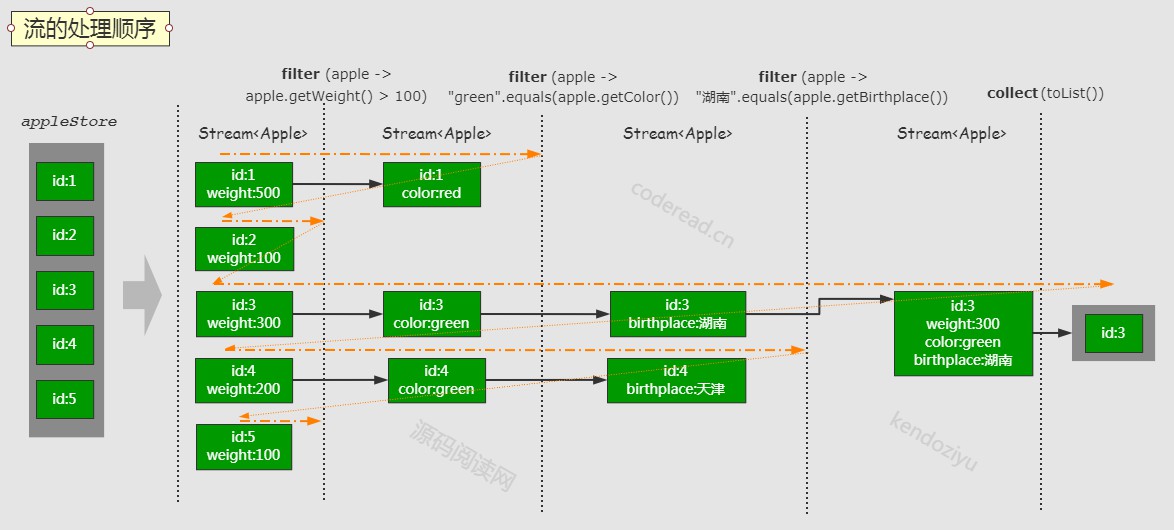
总之,执行顺序会走一个“之”字形。
注意:
如果我们注释掉 .collect(Collectors.toList()), 我们会发现一行语句也不会打印出来。
这刚好证明了:
通过连续执行多个操作倒便就组成了 Stream 中的执行管道(pipeline)。需要注意的是这些管道被添加后并不会真正执行,只有等到调用终值操作之后才会执行。
用流收集数据与 SQL 统计函数
Collector 被指定和四个函数一起工作,并实现累加 entries 到一个可变的结果容器,并可选择执行该结果的最终变换。 这四个函数就是:
| 接口函数 | 作用 | 返回值 |
|---|---|---|
| supplier() | 创建并返回一个新的可变结果容器 | Supplier |
| accumulator() | 把输入值加入到可变结果容器 | BiConsumer |
| combiner() | 将两个结果容器组合成一个 | BinaryOperator |
| finisher() | 转换中间结果为终值结果 | Function |
| Collectors 则是重要的工具类,提供给我一些 Collector 实现。 | ||
| Stream 接口中 collect() 就是使用 Collector 做参数的。 | ||
其中,collect(Supplier<R> supplier, BiConsumer<R, ? super T> accumulator, BiConsumer<R, R> combiner) 无非就是比 Collector 少一个 finisher,本质上是一样的! |
遍历在传统的 javaEE 项目中数据源比较单一而且集中,像这类的需求都我们可能通过关系数据库中进行获取计算。
现在的互联网项目数据源成多样化有:关系数据库、NoSQL、Redis、mongodb、ElasticSearch、Cloud Server 等。这时就需我们从各数据源中汇聚数据并进行统计。
Stream + Lambda的组合就是为了让 Java 语句更像查询语句,取代繁杂的 for 循环。
我们设计一下建表语句
CREATE TABLE `applestore` (
`id` INT NOT NULL AUTO_INCREMENT COMMENT '编号',
`color` VARCHAR (50) COMMENT '颜色',
`weight` INT COMMENT '重量',
`birthplace` VARCHAR (50) COMMENT '产地',
PRIMARY KEY (`id`)
) COMMENT = '水果商店';
另外还有数据初始化语句
INSERT INTO applestore VALUES (1, "red", 500,"湖南");
INSERT INTO applestore VALUES (2, "red", 100,"湖南");
INSERT INTO applestore VALUES (3, "green", 300, "湖南");
INSERT INTO applestore VALUES (4, "green", 200, "天津");
INSERT INTO applestore VALUES (5, "green", 100, "湖南");
测试用例:
public class StreamStatisticsTest {
List<Apple> appleStore;
@Before
public void initData() {
appleStore = Arrays.asList(
new Apple(1, "red", 500, "湖南"),
new Apple(2, "red", 100, "天津"),
new Apple(3, "green", 300, "湖南"),
new Apple(4, "green", 200, "天津"),
new Apple(5, "green", 100, "湖南")
);
}
@Test
public void test1() {
Integer weight1 = appleStore.stream().collect(Collectors.summingInt(apple -> apple.getWeight()));
System.out.println(weight1);
Integer weight2 = appleStore.stream().collect(Collectors.summingInt(Apple::getWeight));
System.out.println(weight2);
}
}
求和
- Collectors.summingInt()
- Collectors.summingLong()
- Collectors.summingDouble()
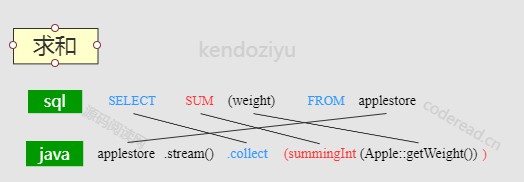
通过引用 import static java.util.stream.Collectors.summingInt; 就可以直接调用 summingInt()
Apple::getWeight() 可以写为 apple -> apple.getWeight(),求和函数的参数是结果转换函数 Function
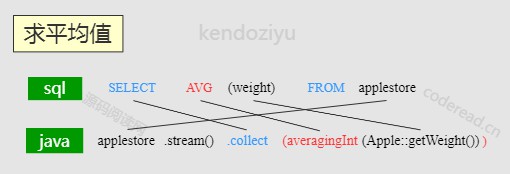
求平均值
- Collectors.averagingInt()
- Collectors.averagingKLong()
- Collectors.averagingDouble()
归约
- Collectors.reducing()
@Test
public void reduce() {
Integer sum = appleStore.stream().collect(reducing(0, Apple::getWeight, (a, b) -> a + b));
System.out.println(sum);
}
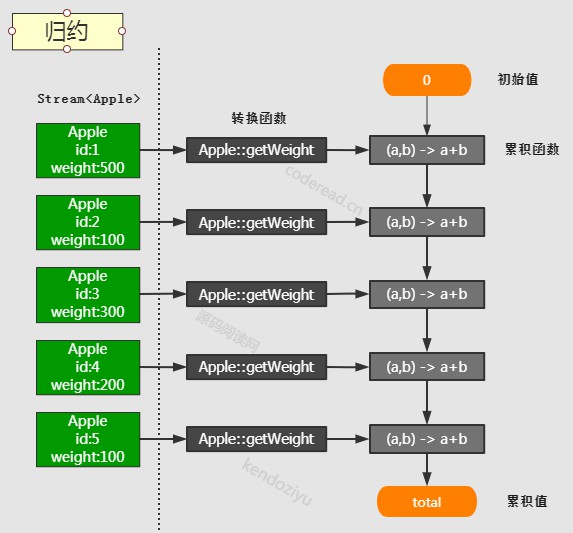
- 归约就是为了遍历数据容器,将每个元素对象转换为特定的值,通过累积函数,得到一个最终值。
- 转换函数,函数输入参数的对象类型是跟 Stream<T> 中的 T 一样的对象类型,输出的对象类型的是和初始值一样的对象类型
- 累积函数,就是把转换函数的结果与上一次累积的结果进行一次合并,如果是第一次累积,那么取初始值来计算
累积函数还可以作用于两个 Stream<T> 合并时的累积,这个可以结合 groupingBy 来理解 - 初始值的对象类型,和每一次累积函数输出值的对象类型是相同的,这样才能一直进行累积函数的运算。
- 归约不仅仅可以支持加法,还可以支持比如乘法以及其他更高级的累积公式。
计数只是归约的一种特殊形式
- Collectors.counting(): 初始值为 0,转换函数 f(x)=1(x 就是 Stream<T> 的 T 类型),累积函数就是“做加法”
分组
- Collectors.groupingBy()
分组就和 SQL 中的 GROUP BY 十分类似,所以 groupingBy() 的所有参数中有一个参数是 Collector接口,这样就能够和 求和/求平均值/归约 一起使用。
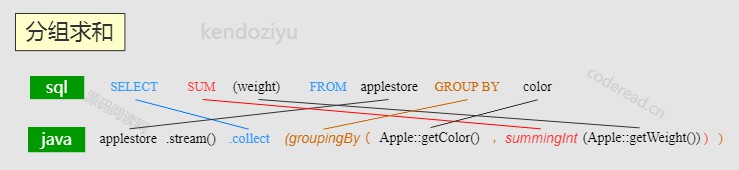
- 传入参数的接口是 Function 接口,实现这个接口可以是实现从 A 类型到 B 类型的转换
- 其中有一个方法可以传入参数
Supplier mapFactory,这个可以通过自定义 Map工厂,来创建自定义的分组 Map
分区只是分组的一种特殊形式
- Collectors.partitioningBy() 传入参数的是 Predicate 接口,
- 分区相当于把流中的数据,分组分成了“正反两个阵营”
数值流
我们之前在求和时用到的例子,appleStore.stream().collect(summingInt(Apple::getWeight)),我就被 IDEA 提醒:
appleStore.stream().collect(summingInt(Apple::getWeight))
The 'collect(summingInt())' can be replaced with 'mapToInt().sum()'
这就告诉我们可以先转化为数值流,然后再用 IntStream 做求和。Java8引入了三个原始类型特化流接口:IntStream,LongStream,DoubleStream,分别将流中的元素特化为 int,long,double。
普通对象流和原始类型特化流之间可以相互转化
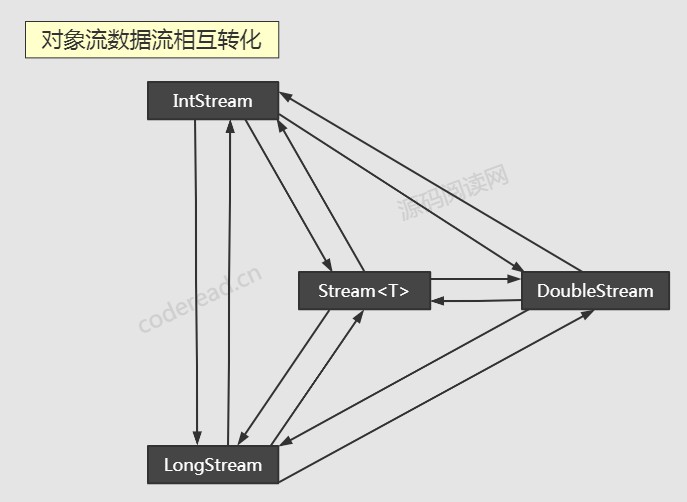
- 其中 IntStream 和 LongStream 可以调用 asDoubleStream 变为 DoubleStream,但是这是单向的转化方法。
- IntStream#boxed() 可以得到 Stream<Integer> ,这个也是一个单向方法,支持数值流转换回对象流,LongStream 和 DoubleStream 也有类似的方法。
生成一个数值流
- IntStream.range(int startInclusive, int endExclusive)
- IntStream.rangeClosed(int startInclusive, int endInclusive)
- range 和 rangeClosed 的区别在于数值流是否包含 end 这个值。range 代表的区间是 [start, end) , rangeClosed 代表的区间是 [start, end]
- LongStream 也有 range 和 rangeClosed 方法,但是 DoubleStream 没有!
flatMap
- Stream.flatMap 就是流中的每个对象,转换产生一个对象流。
- Stream.flatMapToInt 指定流中的每个对象,转换产生一个 IntStream 数值流;类似的,还有 flatMapToLong,flatMapToDouble
- IntStream.flatMap 数值流中的每个对象,转换产生一个数值流
flatMap 可以代替一些嵌套循环来开展业务:
比如我们要求勾股数(即 aa+bb=c*c 的一组数中的 a,b,c),且我们要求 a 和 b 的范围是 [1,100],我们在 Java8之前会这样写:
@Test
public void testJava() {
List<int[]> resultList = new ArrayList<>();
for (int a = 1; a <= 100; a++) {
for (int b = a; b <= 100; b++) {
double c = Math.sqrt(a * a + b * b);
if (c % 1 == 0) {
resultList.add(new int[]{a, b, (int) c});
}
}
}
int size = resultList.size();
for (int i = 0; i < size && i < 5; i++) {
int[] a = resultList.get(i);
System.out.println(a[0] + " " + a[1] + " " + a[2]);
}
}
Java8之后,我们可以用上 flatMap:
@Test
public void flatMap() {
Stream<int[]> stream = IntStream.rangeClosed(1, 100)
.boxed()
.flatMap(a -> IntStream.rangeClosed(a, 100)
.filter(b -> Math.sqrt(a * a + b * b) % 1 == 0)
.mapToObj(b -> new int[]{a, b, (int) Math.sqrt(a * a + b * b)})
);
stream.limit(5).forEach(a -> System.out.println(a[0] + " " + a[1] + " " + a[2]));
}
创建一个从 1 到 100 的数值范围来创建 a 的值。对每个给定的 a 值,创建一个三元数流。
flatMap 方法在做映射的同时,还会把所有生成的三元数流扁平化成一个流。
总结
- Stream 主要包括对象流和数值流两大类
- Stream.of() , Arrays.stream() , Collection#stream() , Stream.generate() , Stream.iterate() 方法创建对象流
- IntStream.range() 和 IntStream.rangeClosed() 可以创建数值流,对象流和数值流可以相互转换
- Collector 收集器接口,可以实现归约,统计函数(求和,求平均值,最大值,最小值),分组等功能
- 流的执行,需要调用终值操作。流中每个元素执行到不能继续执行下去,才会转到另一个元素执行。而不是分阶段迭代数据容器中的所有元素!
- flatMap 可以给流中的每个元素生成一个对应的流,并且扁平化为一个流

 浙公网安备 33010602011771号
浙公网安备 33010602011771号