Netty的ByteBuf API(2)
继上一章 Netty之ByteBuf 之后,我们继续来谈 ByteBuf 的 API
清理操作
discardReadBytes 操作
因为 TCP 底层可能粘包,几百个整包消息被 TCP 粘包后作为一个整包发送。这样,通过 discardReadBytes 操作可以重用之前已经解码过的缓冲区,从而防止接收缓冲区因为容量不足导致的扩张。
需要指出的是,调用 discardReadBytes 会发生字节数组的内存复制,所以频繁调用将会导致性能下降,因此在调用它之前要确认你确实需要这样做,例如牺牲性能来换取更多的可用内存。
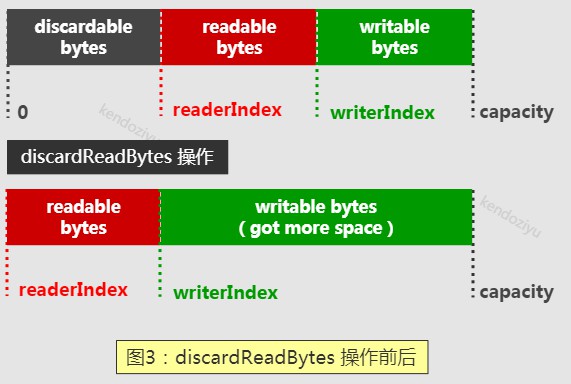
如图所示,capacity 保持不变,reaerIndex = 0,writerIndex -= readerIndex,红色部分的数据发生拷贝。
clear 操作
clear 操作主要用来操作位置指针,并不会清空缓冲区内容本身。
mark 操作
mark 操作针对之前的操作进行回滚
- markReaderIndex() : markedReaderIndex = readerIndex
- resetReaderIndex() : readerIndex = markedReaderIndex
- markWriterIndex() : markedWriterIndex = writerIndex
- resetWriterIndex() : writerIndex = markedReaderIndex
查找操作
查找操作的返回值特点:找到了符合条件的,返回索引,否则返回-1
查找操作的参数特点 :可以指定起始坐标和查找长度,但是起始坐标+查找长度不能超过可读字节数。
- 第一类:从当前 ByteBuf 定位中首次出现 value 的位置
indexOf(fromIndex:int, toIndex:int, value:byte) // 起始索引 fromIndex,终点 toIndex
bytesBefore(value:byte) // 起始索引 readerIndex,终点 writerIndex
bytesBefore(length:int, value:byte) // 起始索引 readerIndex,终点 readerIndex+length <= writerIndex
bytesBefore(index:int, length:int, value:byte) // 起始索引 index,终点 index+length <= writerIndex
- 第二类:指明一个函数参数 ByteBufProcessor
forEachByte(processor:ByteBufProcessor) // 起始索引 readerIndex,终点 writerIndex
forEachByte(index:int, length:int, processor:ByteBufProcessor) // 起始索引 index,终点 index+length
forEachByteDesc(processor:ByteBufProcessor) // 起始索引 writerIndex-1,直到 readerIndex
forEachByteDesc(index:int, length:int, processor:ByteBufProcessor) // 起始索引 index,直到 index+length
ByteBufProcessor
- 可以查找非某字节 以
FIND_NOT_为前缀 - 寻找空字节 FIND_NUL : NUL (0x00)
- 寻找回车 FIND_CR : CR ('\r')
- 寻找换行符 FIND_LF : LF ('\n')
- 寻找回车或者换行符 FIND_CRLF : CR ('\r') or LF ('\n')
- 寻找空格 FIND_ASCII_SPACE : (' ')
- 寻找行内空白 FIND_LINEAR_WHITESPACE : (' ') or ('\t')
- 寻找分号 FIND_SEMI_COLON : (';')
- 寻找逗号 FIND_COMMA : (',')
Derived buffers
类似于数据库的视图,ByteBuf 提供了多个接口用于创建某个 ByteBuf 的视图或者复制 ByteBuf,具体方法如下:
创建共享缓冲区的视图
duplicate():ByteBuf
- 共享缓冲区:复制后的缓冲区与操作的 ByteBuf 共享缓冲区内容
- 独立索引:复制后的新 ByteBuf 对象维护自己独立的读写索引,复制操作本身不修改原 ByteBuf 读写索引。
创建独立的副本
copy():ByteBuf
copy(int index, int length):ByteBuf
- 独立缓冲区:复制后的缓冲区,独立于操作的 ByteBuf 缓冲区,包含操作的 ByteBuf 中的全部或者局部的内容
- 独立索引:新 ByteBuf 对象的读写索引与之前的独立
创建子缓冲区
创建缓冲区可读字节的切片
slice():ByteBuf // 起始位置从 readerIndex 到 writerIndex
slice(int index, int length) // 起始位置从 index 到 index + length
- 共享缓冲区:返回后的 ByteBuf 与 原 ByteBuf 内容共享
- 独立索引:读写索引独立维护。初始化时,readerIndex=0,writerIndex 等于可读字节数,或者等于参数 length
转换成标准 ByteBuffer
nioBuffer():ByteBuffer
nioBuffer(int index, int length):ByteBuffer
两者共享同一个缓冲区内容引用。对 ByteBuffer 的读写操作不会改变 ByteBuf 的读写索引。
需要注意的是,返回后的 ByteBuffer 无法感知原 ByteBuf 的动态拓展操作。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号