Netty的ByteBuf API
ByteBuf 功能说明
上一篇文章 NIO入门之缓冲区Buffer 已经介绍了 Java 1.4 引入的 java.nio.Buffer。
从功能角度而言,ByteBuffer 完全可以满足 NIO 编程的需要,但是由于 NIO 编程的复杂性,ByteBuffer 也有其局限性,它的主要缺点如下:
- ByteBuffer 长度固定,一旦分配完成,它的容量不能动态拓展和收缩,当需要编码的 POJO 对象大于 ByteBuffer 的容量时,会发生索引越界异常。
ByteBuffer buffer = ByteBuffer.allocate(1024); // 指定分配固定长度的容量
- ByteBuffer 只有一个标识位置的指针 position,读写的时候需要手动调用 flip() 和 rewind(),使用必须小心谨慎地处理这些 API,否则很容易导致程序处理失败;
buffer.clear();
socketChannel.read(buffer); // 读取前后都要选用合适的 NIO 的 API
buffer.flip();
- ByteBuffer 的 API 功能有限,一些高级和实用的特性它不支持,需要使用者自己编程实现。
为了弥补这些不足,Netty 提供了自己的 ByteBuffer 实现——ByteBuf。
特性1:引入双标识位置
java.nio.Buffer 只有一个位置指针 position 来处理读写操作,因此每次需要读写的时候,都需要额外地调用 flip() 和 clear() 方法,否则将可能出现 BufferUnderflowException 或者 BufferOverflowException 异常。
io.netty.buffer.ByteBuf 通过两个位置指针来协助缓冲区的读写操作:
- 读操作使用 readerIndex
- 写操作使用 writerIndex
API:io.netty.buffer.ByteBuf
- int writableBytes()
获取当前的可写字节数 - int readableBytes()
获取当前的可读字节数
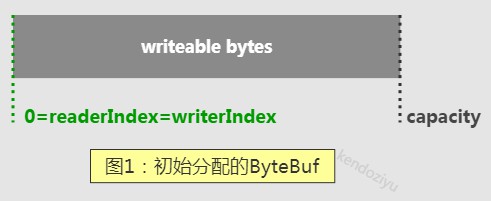
刚刚初始化的 ByteBuf 或者调用 clear 之后的 ByteBuf 读写指针都是停留在 0 的位置。
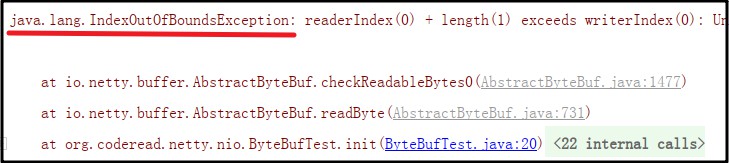
当前没有可读的字节,如果强行读取会抛出java.lang.IndexOutOfBoundsException:
- readerIndex 和 writerIndex 之间的数据时可读取的,对应 java.nio.Buffer 的 position 和 limit 之间的数据。
- writerIndex 和 capacity 之间的空间是可写的,等价于 Buffer limit 和 capacity 之间的可用空间。

特性2:自动扩容
ByteBuf 对 write 操作进行了封装,由 ByteBuf 的 write 操作负责进行剩余空间的校验。
如果可用缓冲区不足,ByteBuf 会自动进行动态拓展。
ByteBuf 的功能性 API
顺序读操作(read)
读取基本数据类型
Java 有 8 种基本数据类型分别是 boolean, byte, short, char, int, long, float, double。
Netty 的顺序读操作自然也少不了这些类型,
readByte():byte
readBoolean():boolean
readShort():short
readChar():char
readInt():int
readLong():long
readFloat():float
readDouble():double
从readIndex开始获取24位整型值,readIndex增加3(注意:该类型并非 Java 的基本类型,大多数场景下用不到):
readMedium():int
除此以外,但是对于 byte, short, medium, int 还多出了四种无符号型
readUnsignedByte():byte
readUnsignedShort():int
readUnsignedMedium():int
readUnsignedInt():int
针对整形(short, medium, int, long)和浮点型(float, double), 还有小端模式 API:
readShortLE(): short
readUnsignedShortLE(): int
readMediumLE(): int
readUnsignedMediumLE(): int
readIntLE(): int
readUnsignedIntLE(): int
// 以下均形单影只,没有 unsigned
readLongLE(): long
readFloatLE(): float
readDoubleLE(): double
关于大端小端,百度百科讲得还挺好的:大小端模式,但是需要补充几点:
- 大端模式是和我们的阅读习惯一致的。
- JVM 默认采取的是大端模式编码,即 Java 的客户端/服务端之间收发信息,都按大端模式来处理。
读取到目标 ? 中
然后就是 readBytes 方法将当前 ByteBuf 的数据读取到目标?中,?的主要的参数类型有 ByteBuf, byte[], ByteBuffer, OutputStream, GatheringByteChannel, FileChannel。
这相当于从当前 ByteBuf 创建一个?类型的数据副本。
创建子区域(切片)
readSlice(length: int) :ByteBuf
- 返回当前 ByteBuf 新创建的子区域,子区域与原 ByteBuf 共享缓冲区,但是独立维护自己的 readerIndex 和 writerIndex
- 新创建的子区域 readerIndex 为 0, writerIndex 为 length
- 如果读取的长度 length 大于当前操作的 ByteBuf 的可写字节数,将抛出 IndexOutOfBoundsException,操作失败
顺序写操作(write)
写入 Java 基本数据类型
写入的时候,就没有读取时那么多“花里胡哨”的 unsigned 了,返回值清一色 ByteBuf,就是为了能够 byteBuf.writeBoolean(true).writeInt(0).writeFloat(1.0f) 这样链式调用。
writeBoolean(value : boolean): ByteBuf
writeByte(value: byte): ByteBuf
writeChar(value: char): ByteBuf
writeShort(value: short): ByteBuf
writeInt(value: int): ByteBuf
writeMedium(value: int): ByteBuf // 这个不是 Java 基本类型,算个特例
writeLong(value: long): ByteBuf
writeFloat(value: float): ByteBuf
writeDouble(value: double): ByteBuf
除了 boolean,byte,char,其他的还有小端模式 API
writeShortLE(value: short): ByteBuf
writeIntLE(value: int): ByteBuf
writeMediumLE(value: int): ByteBuf // 这个不是 Java 基本类型,算个特例
writeLongLE(value: long): ByteBuf
writeFloatLE(value: float): ByteBuf
writeDoubleLE(value: double): ByteBuf
将 ? 写入当前 ByteBuf
- writeBytes 方法将 ? 类型(包含 ByteBuf, ByteBuffer)中的可读字节写入到当前 ByteBuf
- writeBytes 方法将 ? 类型(包含 byte[])中的所有字节写入到当前 ByteBuf
- writeBytes 方法将 ? 类型(包含 InputStream,ScatteringByteChannel,FileChannel)中的所有内容写入到当前 ByteBuf
内容填充 NUL(0x00)
writeZero(length: int): ByteBuf
- 将当前的缓冲区内容填充为 NUL(0x00),起始位置为 writerIndex,填充的长度为 length
- 填充成功之后 writerIndex += length
- 如果 length 大于当前 ByteBuf 的可写字节数(
writableBytes():int的返回值),会尝试调用ensureWritable(int)进行扩容。扩容失败,抛出 IndexOutOfBoundsException 异常。
随机读写(set 和 get)
除了顺序读写之外,ByteBuf 还支持随机读写,它与顺序读写的最大差别在于可以随意指定读写的索引位置。
无论是 get 还是 set 操作,ByteBuf 都会对齐索引和长度等进行合法性校验,与顺序读写一致。
但是,set 操作和 write 操作不同的是它不支持动态扩展缓冲区,所以使用者必须保证当前的缓冲区可写的字节数大于需要写入的字节长度,否则会抛出数据或者缓冲区越界异常。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号