C++用内联汇编手写Atomic原子操作CAS(compare-and-swap)
实现参考自 openjdk/hotspot/src/os_cpu/linux_x86/vm/atomic_linux_x86.inline.hpp
long cmpxchg(long exchange_value, volatile long* dest, long compare_value);
上述函数的实现,如果用伪代码来理解:
比较 *dest == compare_value
如果相等 *dest = exchange_value,返回原来的 *dest 的值
如果不相等 返回原 *dest 的值
warning: inline function 'Atomic::cmpxchg' is not defined
//原来头文件是这么写的:
class Atomic {
public:
static inline long cmpxchg(long exchange_value, volatile long* dest, long compare_value);
}
//后来的cpp文件是这么写的:
inline long Atomic::cmpxchg(long exchange_value, volatile long* dest, long compare_value) { //省略具体实现 }
然后,在调用 Atomic::cmpxchg 就有一个警告 warning: inline function 'Atomic::cmpxchg' is not defined
我搜索到的 C++学习——关于内联函数inline function的坑 undefined reference to 有一个相对合理的解释
如果将函数的实现放在头文件,并且标记为 inline 那么每一个包含该头文件的cpp文件都将得到一份关于该函数的定义,并且链接器不会报错。
为什么加 inline?
因为加上 inline 修饰符之后,汇编代码中,就不需要给 Atomic::cmpxchg 函数方法创建单独的栈帧,也不需要参数传递,保存现场或者恢复现场,省掉了不少指令。
且因为该内联函数内代码较少,移除一些不需要的操作之后,会使代码速度更快。
我的代码
C++ 头文件 atomic.hpp 代码:
#ifndef SHARE_VM_RUNTIME_ATOMIC_HPP
#define SHARE_VM_RUNTIME_ATOMIC_HPP
class Atomic {
public:
static inline long cmpxchg(long exchange_value, const long* dest, long compare_value) {
__asm__ volatile ("lock; cmpxchgq %1, (%3)"
:"=a"(exchange_value)
:"r"(exchange_value), "a"(compare_value), "r"(dest)
:"cc", "memory");
return exchange_value;
}
};
#endif //SHARE_VM_RUNTIME_ATOMIC_HPP
C++ 文件 main.cpp 函数代码:
int main() {
long v1 = 10;
long v2 = 20;
long v3 = Atomic::cmpxchg(v2, (long*)&v1, v1);
printf("v1=%ld, v2=%ld, v3=%ld", v1, v2, v3);
return 0;
}
-O2编译优化
当我用 g++ -g src/main.cpp -o main.o 编译后,从汇编得到的机器码来看,上看并没有产生内联的效果:
long v3 = Atomic::cmpxchg(v2, (long*)&v1, v1);
0x0000555555555194 <+43>: mov -0x20(%rbp),%rdx
0x0000555555555198 <+47>: lea -0x20(%rbp),%rcx
0x000055555555519c <+51>: mov -0x18(%rbp),%rax
0x00005555555551a0 <+55>: mov %rcx,%rsi
0x00005555555551a3 <+58>: mov %rax,%rdi
0x00005555555551a6 <+61>: callq 0x5555555551ea <Atomic::cmpxchg(long, long const*, long)>
0x00005555555551ab <+66>: mov %rax,-0x10(%rbp)
编译得到 main.o 文件之后,执行
gdb main.o,在继续执行(gdb) start,(gdb) disass /m就可以看到反汇编代码了。
但是,当我使用 g++ -O2 src/main.cpp -o main.o (-g 选项,我也去掉了)编译后,再看反汇编代码:
0x0000555555555088 <+8>: mov $0x14,%edx
...(省略了一些安全检查的代码)
0x000055555555509d <+29>: mov %rsp,%r8
0x00005555555550a0 <+32>: movq $0xa,(%rsp)
0x00005555555550a8 <+40>: mov $0xa,%eax
0x00005555555550ad <+45>: lock cmpxchg %rdx,(%r8)
0x00005555555550b2 <+50>: mov (%rsp),%rdx
0x00005555555550b6 <+54>: mov %rax,%r8
没有了 callq,也就是说没有了函数调用
gcc内联汇编
参考自 最牛X的GCC 内联汇编,本文挑出个人感觉不太好理解的点提一下。
volidate
如果你熟悉内核源码或者类似漂亮的代码,你一定见过许多声明为 volatile 或者 __volatile__的函数。那么,什么是 volatile 呢?
如果我们的汇编语句必须在我们放置它的地方执行(例如,不能为了优化而被移出循环语句),将关键词 volatile 放置在 asm 后面、() 的前面。以防止它被移动、删除或者其他操作,我们将其声明为
asm volatile ( ... : ... : ... : ...);
修饰寄存器列表
一些指令会破坏一些硬件寄存器内容。我们不得不在修饰寄存器中列出这些寄存器,即 asm 括号内第三个 “:” 之后的域。这可以通知 gcc 我们将会自己使用和修改这些寄存器,这样 gcc 就不会假设存入这些寄存器的值是有效的。我们不用在这个列表里列出输入、输出寄存器。因为 gcc 知道 “asm” 使用了它们(因为它们被显式地指定为约束了)。如果指令隐式或显式地使用了任何其他寄存器,(并且寄存器没有出现在输出或者输出约束列表里),那么就需要在修饰寄存器列表中指定这些寄存器。
如果我们的指令可以修改条件码寄存器(cc),我们必须将 "cc" 添加进修饰寄存器列表。
状态寄存器又名条件码寄存器,就是我们熟知的 EFLAGS
如果我们的指令以不可预测的方式修改了内存,那么需要将 "memory" 添加进修饰寄存器列表。这可以使 GCC 不会在汇编指令间保持缓存于寄存器的内存值。
如果被影响的内存不在汇编的输入或输出列表中,我们也必须添加 "volatile" 关键词。
lock cmpxchg
gcc/g++ 编译器通常识别 AT&T 风格的汇编语言,通常写在汇编程序模板中,即 asm 括号内第一个 “:” 之前的域,了解更多可以学习 【翻译】在Linux平台上使用Intel和AT&T汇编语言以及GCC内联汇编
如果程序是在多处理器上运行,就为 cmpxchg 指令加上 lock 前缀(lock cmpxchg)。
GDB观察与堆栈图
在 lock cmpxchg %rdx,(%r8) 执行之前:
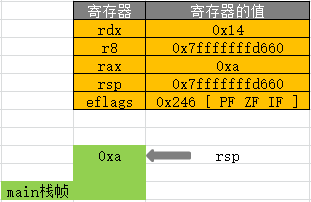
long v2 = 20; => mov $0x14,%edx 十六进制立即数 0x14 转移到 edx 寄存器中,即 edx 保存着 v2 的值
(... : ... :"r"(exchange_value), "a"(compare_value), "r"(dest) : ...)
v1 的值等于 compare_value 的值 0xa,被赋值给了 eax 寄存器,对应汇编语句mov $0xa,%eax
v2 的值等于 exchange_value 的值 0x14,就保存在 edx 寄存器中
dest 类型是指针,保存着内存首地址 0x7fffffffd660,被保存在 r8 寄存器,对应汇编语句mov %rsp,%r8
movq $0xa,(%rsp)则是为 *dest 赋值 0xa
执行之后,内存发生变化:

cmpxchg %source,(%dest)
cmpxchg 命令隐含使用 EAX 寄存器。拿 目标寄存器/目标内存 的值和 EAX 寄存器的值做比较:
- 如果相等,就把 源寄存器 的值传送到 目标寄存器/目标内存。
- 如果不相等,就把 目标寄存器/目标内存 的值传送到 EAX 寄存器。
当 Atomic::cmpxchg 作为单独函数时
将 main.cpp 中代码中传入的 compare_value 值修改为 0
long v1 = 10;
long v2 = 20;
long v3 = Atomic::cmpxchg(v2, (long*)&v1, 0);
当我们不用 -O2 优化进行编译,得到的 Atomic::cmpxchg 函数的反汇编代码:
0x00005555555551ef <+4>: push %rbp
0x00005555555551f0 <+5>: mov %rsp,%rbp
0x00005555555551f3 <+8>: mov %rdi,-0x8(%rbp) // 寄存器 rdi 保存的值 0x14 传送到局部变量 exchange_value
0x00005555555551f7 <+12>: mov %rsi,-0x10(%rbp) // 寄存器 rsi 保存的指针值 0x7fffffffd660 传送到局部变量 dest
0x00005555555551fb <+16>: mov %rdx,-0x18(%rbp) // 寄存器 rdx 保存的指针值 0 传送到局部变量 compare_value
0x00005555555551ff <+20>: mov -0x8(%rbp),%rdx // "r"(exchange_value) 被编译为把局部变量 exchange_value 传递到 rdx
0x0000555555555203 <+24>: mov -0x18(%rbp),%rax // "a"(compare_value) 被编译为把局部变量 compare_value 传递到 rax
0x0000555555555207 <+28>: mov -0x10(%rbp),%rcx // "r"(dest) 被编译为把局部变量 dset 传送到 rcx
=> 0x000055555555520b <+32>: lock cmpxchg %rdx,(%rcx)
0x0000555555555210 <+37>: mov %rax,-0x8(%rbp) // "=a"(exchange_value) 表示把 rax 中的传送到局部变量 exchange_value
0x0000555555555214 <+41>: mov -0x8(%rbp),%rax // 把局部变量 exchange_value 的值作为函数返回值传送到 rax (这是一个惯例)
0x0000555555555218 <+45>: pop %rbp
0x0000555555555219 <+46>: ret
这段函数反汇编代码,显然能够更好地解释 GCC 内联汇编代码中,为什么要有输出部分 & 输入部分?
显然,这是为了方便我们向寄存器内传递 C++ 代码中的变量,或者从寄存器中传出 C++ 代码需要的运算结果!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
2021-08-11 集群中某一个节点logback日志文件写入不成功排查历程