
mysql的索引结构
为甚要设计索引?
如何设计索引?
设计索引时使用什么数据结构?
mysql是如何实现的?
数据库里的数据都保存在磁盘里。
文件
1.关键值:key
2.文件名称
3.偏移量 offset
索引的文件存储形式与引擎有关:
mysql中的存储引擎:myisam,innodb,memory
memory用的是hash索引
myisam,innodb 用的是b+tree索引
大部分说的存储引擎都是innodb。
在mysql中输入 “show index from 表名” 就可以查看引擎
数据都是放在磁盘中,读数据的时候是从磁盘读到内存当中的。
磁盘的读写速度比内存小很多很多。
因此把磁盘数据加载到内存读。
把经常访问的数据可以从磁盘读出来放在内存中。
局部性原理:
程序和数据的访问都有聚集成群的倾向,
在一段时间内,仅仅使用其中一小部分(称空间局部性)
或者最近访问过的程序代码和数据,很快又被访问的可能性很大(称时间局部性)
磁盘预读(预读的长度一般为页page的整数倍):
页是存储器的逻辑块
操作系统往往将主存和磁盘分成连续的大小相等的块,每个存储块称为一页(页大小通常为4k),
主存和磁盘以页为大小交换数据。
磁盘预读每次读4k的倍数,一次加载一个磁盘块16k
即便是查一个数据a,加载的也是一个块,而不是只加载a。
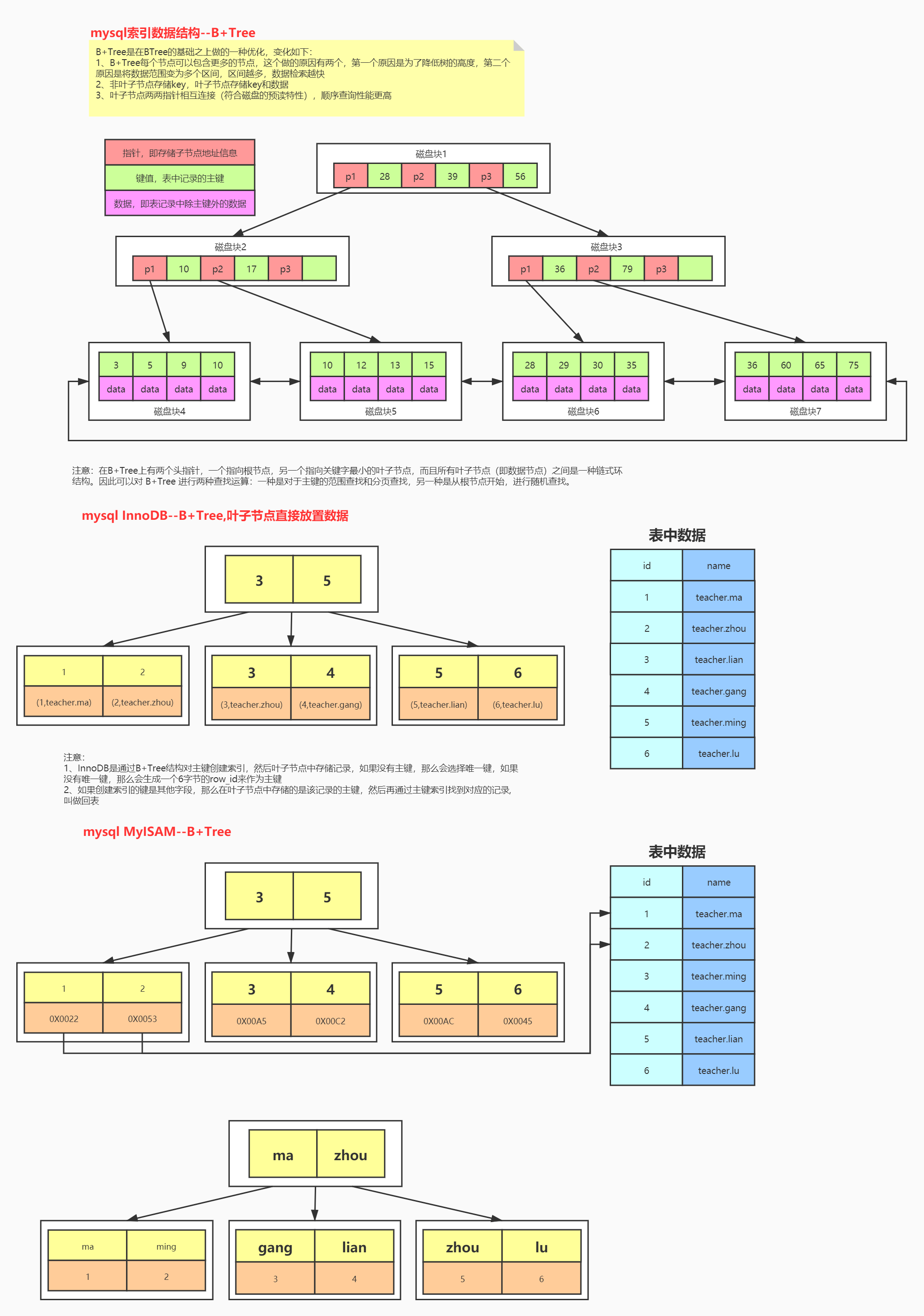
索引是帮助mysql高效获取数据的数据结构。
索引存储在文件系统中。
索引文件结构:hash,二叉树,b tree, b+tree
为什么mysql中选择b+ tree??
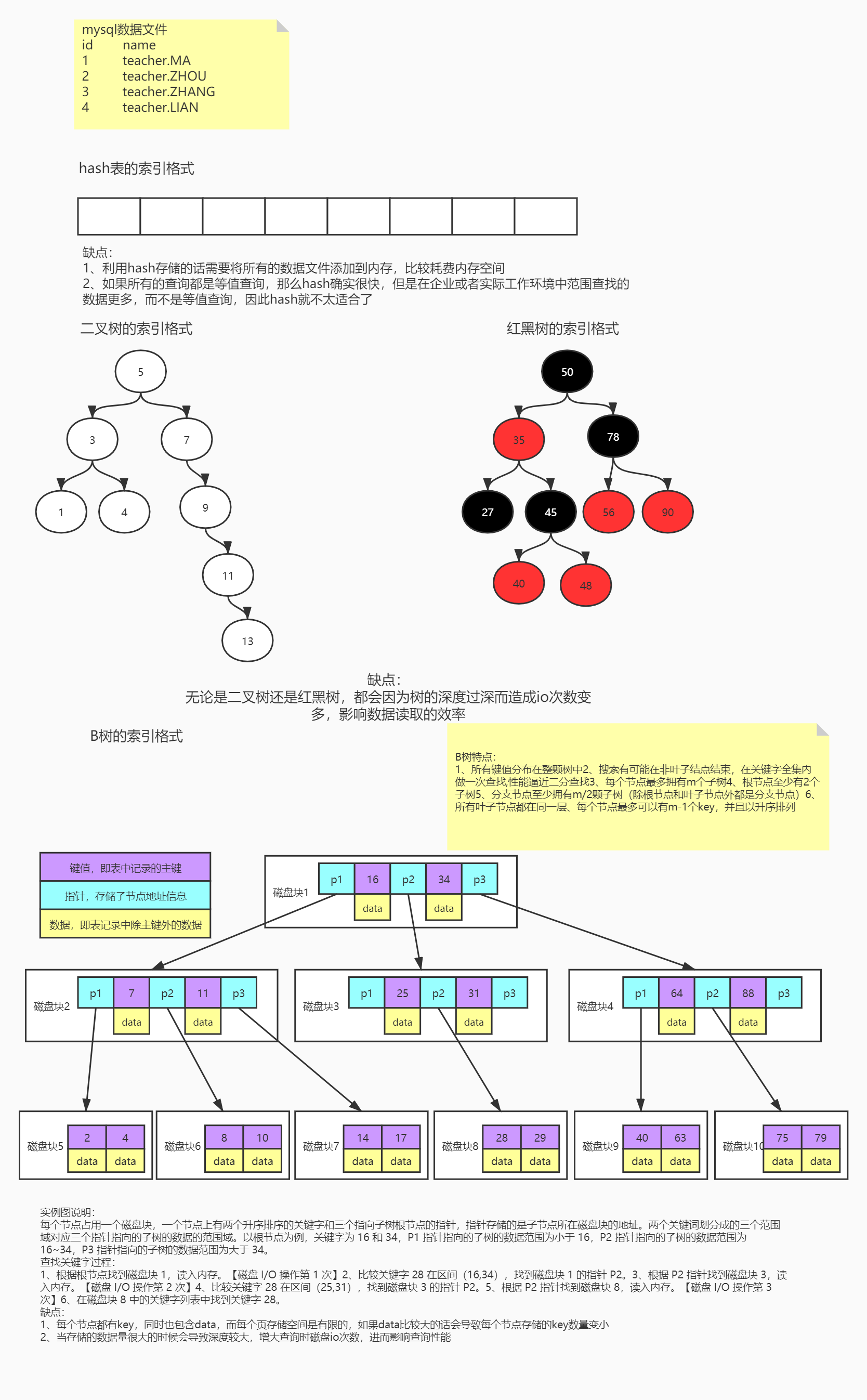
二叉树,BST, AVL, 红黑树,这些树的节点里存的都是一个值。
但是我们索引的时候是从磁盘读数据的,每次返回的是一个数据块
而不是取一个值。
像innodb,myisam每次都是取16k的数据,这样就会取出来很多个节点,
节点越多,树越深,造成io次数变多。
提升IO的效率只有2个途径:
减少IO的次数
减少IO的量(大小)
所以公司一般不让用select * 查询
mysql里面有一个服务层,每次交互的时候需,
要服务层从存储引擎里把数据拉出来,
在服务层筛选完毕之后,再返回给客户端
所以如果用select * 查询就会增大IO量
B树和B+tree 节点里放的不是一个值而是值的集合:
degree 叫做阶,表示单个节点里可以放置多少个数据元素。
degree = 4 的时候,每个节点可以放3个节点。
一个节点可以放置degree - 1 的数据
假设查id是28这条数据,这些数据都是在磁盘里的,
假设磁盘块1是16k(innodb默认读16k),从磁盘块1开始找,到磁盘块8,
一共是磁盘块1+磁盘块3+磁盘块8,内存一共加载了3个16k的磁盘块
从头到尾读了48k数据
在B tree中每个磁盘块的大小跟data 相关,上图中
一个磁盘块里有2个data,假如1行数据是1k,那么一个数据块就存16条
一个磁盘块16k换算成字节是16000,图1中“指针”+“键值”假如算一组的话,
假设一组10个字节,那么一个磁盘块可以存1600组。
在第三层的叶子层上,一条数据占1k,那么叶子层还是只有16条数据。
之前的b tree 3层一共存的数据量是16*16*16,
现在b + tree存的数据量是1600*1600*16
B+ tree是把所有的data都放在了最下面的叶子上,节点上不再放data,
这样就节省了节点上的存储空间
b+tree有2种查找方式:从根节点开始查找; 也可以通过双向链表从最小叶子节点开始找。
myisam和Innodb的数据结构都是b+tree,从上图中可以看到区别是:
Innodb最后的叶子节点存放的是完整数据,这种数据和索引存放在一起的叫做聚簇索引
myisam最后的叶子节点放的是地址,通过地址再查找数据,数据和索引分开存放的叫非聚簇索引
一般创建数据库都是主键自增的,这种适用于单机数据库。
如果是分布式就不能用主键自增,需要用雪花算法设置主键。
key值包括:主键,唯一键,row_id

 浙公网安备 33010602011771号
浙公网安备 33010602011771号