MySQL 一些内部原理
1. MySQL 体系结构
如下图:
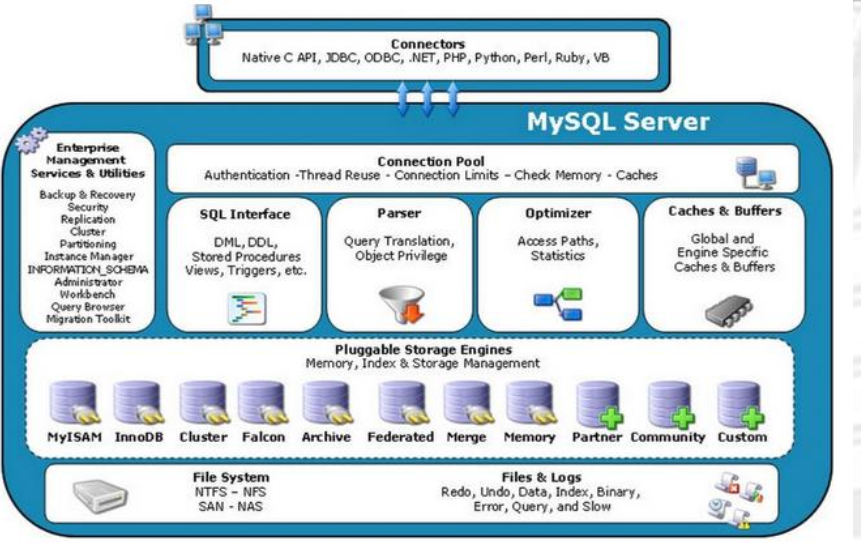
Mysql是由SQL接口,解析器,优化器,缓存,存储引擎组成的(SQL Interface、 Parser、 Optimizer、Caches&Buffers、Pluggable Storage Engines)
-
Connectors指的是不同语言中与SQL的交互
-
Management Serveices & Utilities: 系统管理和控制工具,例如备份恢复、Mysql复制、集群等
-
Connection Pool: 连接池:管理缓冲用户连接、用户名、密码、权限校验、线程处理等需要
-
SQL Interface: SQL接口:接受用户的SQL命令,并且返回用户需要查询的结果。比如select from就是调用SQL Interface
-
Parser: 解析器, SQL命令传递到解析器的时候会被解析器验证和解析。主要功能:
a . 将SQL语句分解成数据结构,并将这个结构传递到后续步骤,以后SQL语句的传递和处理就是基于这个结构的b. 如果在分解构成中遇到错误,那么就说明这个sql语句是不合理的 -
Optimizer: 查询优化器, SQL语句在查询之前会使用查询优化器对查询进行优化
-
Cache和Buffer(高速缓存区): 查询缓存,如果查询缓存有命中的查询结果,查询语句就可以直接去查询缓存中取数据。
通过LRU算法将数据的冷端溢出,未来得及时刷新到磁盘的数据页,叫脏页。
这个缓存机制是由一系列小缓存组成的。比如表缓存,记录缓存, key缓存,权限缓存等 -
Engine :存储引擎。存储引擎是MySql中具体的与文件打交道的子系统。也是Mysql最具有特色的一个地方。
-
MySQL相关底层文件
2. MySQL 文件
构成MySQL整个数据库的是所有的相关文件,这些文件有:
参数文件my.cnf:告诉MySQL实例在启动的时候去哪里找数据库文件,并指定初始化文件参数,包括定义内存缓冲池大小等等
日志文件:用来记录MySQL实例对某些条件作出响应时写入的文件,包括错误日志文件,二进制日志文件,慢查询日志文件,查询日志文件等
Socket文件:当用Unix套接字方式连接时使用的文件
Pid文件:MySQL实例的进程ID文件
MySQL表结构文件:用来存放表结构定义的文件
存储引擎相关文件:每个存储引擎都有自己相关的文件来保存各种数据,包括表数据和索引数据等等
参数文件:当MySQL实例启动时,数据库会先去读一个配置参数文件,用来寻找数据库的各种文件所在位置以及指定的初始化参数
2.1 MySQL 参数文件
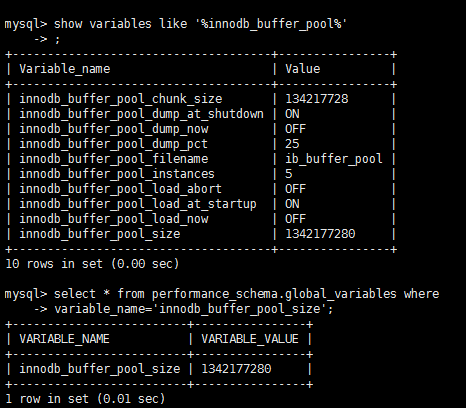
数据库参数其实是一个键值对(key/value),比如innodb_buffer_pool_size=1G。
可以通过show variables命令来查看所有的参数,也可以通过like关键词来过滤特定的
参数,还可以通过performance_schema.global_variables视图(5.7.6版本以后)来查看参数
show variables like '%innodb_buffer_pool%' select * from performance_schema.global_variables where variable_name='innodb_buffer_pool_size';
MySQL数据库中的参数可以分为动态参数和静态参数两种
https://dev.mysql.com/doc/refman/5.7/en/server-system-variables.html #官方文档, 对一些参数的详细解释
2.1.1 动态参数
参数的详细解释 动态参数是指在数据库运行的过程中可以动态修改的参数,可以通过set命令对动态参数进行修改
用法:
mysql> help set
Name: 'SET'
Description:
Syntax:
SET variable_assignment [, variable_assignment] ...
variable_assignment:
user_var_name = expr
| param_name = expr
| local_var_name = expr
| [GLOBAL | SESSION]
system_var_name = expr
| [@@global. | @@session. | @@]
system_var_name = expr
Global和session是指该参数的修改是基于当前会话还是基于整个实例的生命周期
设置为global参数修改,并不影响my.cnf中的变化,当数据库下次重启依然是参数文件中的配置
注: 如果不重启mysql 的情况下动态修改参数,先看看该参数是不是动态参数, 如果是动态参数 则可以用set global 方式修改 , 修改完动态参数文文件,再加入到my.cnf
例如autocommit 是dynamic 动态参数

2.1.2 静态参数
静态参数是指在数据库运行过程中不能修改的参数,必须在配置文件my.cnf中修改并且数据库重启后才能生效
比如datadir参数,如果使用动态参数修改方式,则会报错:
mysql> set global datadir='/usr/local/mysql/data2'; ERROR 1238 (HY000): Variable 'datadir' is a read only variable
2.2 MySQL 日志文件
MySQL日志文件包含以下几种: 错误日志(error log) 二进制日志(binlog) 慢查询日志(slow log) 查询日志(general_log)
2.2.1 错误日志
是对MySQL的启动,运行和关闭过程进行了记录。遇到问题时首先应该查询此文件以便定位问题。
可以通过show variables like ‘log_error’ 命令来定位文件位置
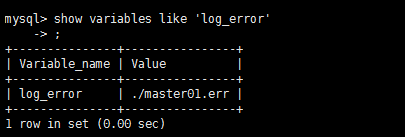
默认情况下错误日志的文件名是该服务器的主机名
2.2.2慢查询日志
可以定位可能存在性能问题的SQL语句,从而进行SQL语句层面的优化。 通过设置long_query_time参数来设置一个阈值,将运行时间超过该值的所有SQL语句都记录到慢查询日志文件中。
show variables like '%long_query%'; show variables like '%slow_query%';
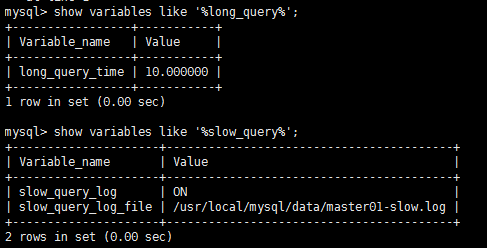
另一个和慢查询日志相关的参数是log_queries_not_using_indexes参数,如果运行的SQL语句没有使用索引,则会把这条SQL语句记录到慢查询日志中
例如
#一个会话窗口,实时查看日志 tail -f /usr/local/mysql/data/master01-slow.log #另一个窗口 执行一个做慢查询模拟
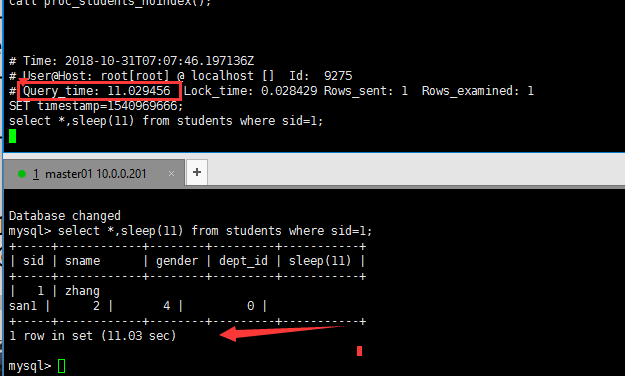
慢查询日志中不光会记录select语句,对数据库修改语句如果符合条件也会记录
执行sql语句的时间 比 long_query_time 大都会被记录
随着MySQL数据库服务器运行时间的增加,会有越来越多的SQL语句记录到慢查询日志中,此时分析该文件显得不那么简单和直观,这个时候可以使用
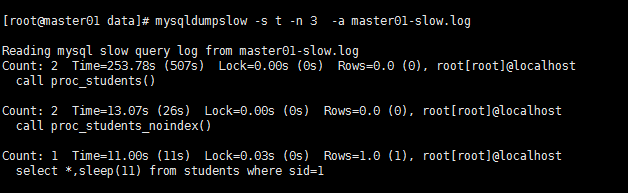
mysqldumpslow命令来协助分析慢查询日志 也可以通过pt 工具来分析,推荐用pt的工具。
例如提取执行时间最长的3条SQL 语句
mysqldumpslow -s t -n 3 -a master01-slow.log
如果慢查询的日志文件查询看着不舒服 想通过sql 方式的来看
哪可以通过动态修改log_output参数将慢查询输出到mysql库下的表中
默认是以文件的输出的方式
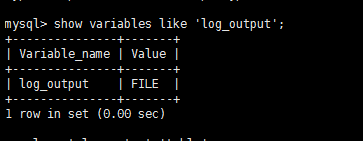
show variables like 'log_output'; 修改为 set global log_output='table'; 查看一下表结构 desc mysql.slow_log;

模拟慢查询 就会输出到mysql.slow_log表中

作用 : 分析常用sql ,看懂sql的具体作用,是否可以优化
2.2.3 查询日志
查询日志记录了所有对MySQL数据库请求的信息。
通过两个参数来启动:
general_log=on general_log_file=/usr/local/mysql/data/general_log
开启了这个文件 会记录 mysql 会话请求连接中 会实时记录所操作 的 ddl ,dml 语句 ,会导致这个文件变得,不一会就会变得很大, 影响存储。 开启这个查询日志一般都是用于排除一些异常才会开启。
2.2.4 二进制日志文件
二进制日志binary log记录了对MySQL数据库执行更改的所有操作,但不包括select和show这类操作。其主要作用为: 恢复:例如在一个数据库全备文件恢复后,用户可以通过二进制日志进行增量恢复 复制:通过执行二进制日志使远程的一台MySQL数据库与本数据库进行数据同步 审计:用户可以通过二进制日志中的信息来进行审计,判断是否有对数据库进行注入攻击
通过配置参数log-bin[=name]可以启动二进制日志,如果不指定name,则默认二进制日志文件名为主机名,后缀名为二进制日志的序列号
比如在服务器上的mysql-bin.000015为一个二进制日志文件,mysql-bin.index文件为二进制的索引文件,用来存储过往产生的二进制日志序号 
影响二进制日志文件的其他参数:
Max_binlog_size:指定了单个二进制日志文件的最大值,如果超过该值,则产生新的二进制日志文件,后缀名+1,并记录到.index文件中,默认是1G
binlog_cache_size:对InnoDB来说,所有未提交的事务的二进制日志都会先写入到缓存中,只有当事务提交时将缓存中的二进制日志写入到日志文件中。而缓存的大小由binlog_cache_size决定,默认是32K。当一个线程开启一个事务时,会自动分配32K的大小的binlog缓存空间,当事务的记录大于32K大小的时候,则会把缓存中的日志写入到临时文件中,可以通过查询binlog_cache_disk_use参数查看写入到临时文件的次数

在默认情况下由于缓存的存在,所以每个事务并不是在发起的时候就写入到二进制日志中,所以当数据库在事务执行过程中宕机,则会有部分二进制日志未写入到文件的情况,参数sync_binlog=[N]用来控制此行为。 N参数表示每写多少次缓存就同步数据到磁盘,如果设置为1,则表示将缓存的内容同步写入到磁盘中
sync_binlog默认取值为1 在5.7.x
5.6 版本好像是0
binlog_do_db和binlog_ignore_db表示需要写入和忽略哪些库的二进制日志的写入,默认是空,表示所有数据库的二进制日志都要写入
Log_slave_update参数用来将从master上取得并执行的二进制日志写入到自己的二进制日志文件中去,通常在需要搭建master=>slave=>slave (一主多从,多主多从)架构的复制时,需要设置该参数
Binlog_format参数决定了二进制日志文件的内容格式,其取值可以是statement,row或者是mixed
2.3 MySQL 套接字文件
套接字文件:在unix系统下本地连接MySQL可以采用unix域套接字方式,这种方式需要一个套接字(socket)文件,其位置和名称由参数socket控制,一般在/tmp目录下,名为mysql.sock
show variables like 'socket';
对mysql.sock来说,其作用是程序与mysqlserver处于同一台机器, 发起本地连接时可用。
例如你无须定义连接host的具体IP地址,只要为空或localhost就可以。 在此种情况下,即使你改变mysql的外部port也是一样可能正常连接
2.4 MySQL进程文件
Pid文件:当MySQL实例启动时,会将自己的进程ID写入到一个文件中,该文件由参数pid_file控制,默认是在数据库目录下,文件名为主机名.pid
show variables like 'pid_file';
2.5 MySQL 表结构文件
表结构定义文件:MySQL无论表采用哪种存储引擎,都会产生一个以frm为后缀名的文件,这个文件记录了该表的表结构定义
frm还用来存放视图定义,该文件是文本文件,可以直接使用cat命令来查看视图定义
只有视图的的frm 可以直接查看该结构的文件
2.6 MySQL存储引擎文件
InnoDB存储引擎文件包括以下几种:
表空间文件:
分为共享表空间文件(ibdata1)和独立表空间
由innodb_data_file_path参数控制,所有基于InnoDB存储引擎的表的数据都会记录到该共享表空间中
而如果设置了innodb_file_per_table参数,则每个innodb表都会产生一个独立的表空间,独立表空间的命令规则为表名.ibd,通过这种方式,用户不用将所有数据都存放在默认表空间中。
需要说明的是独立表空间文件仅存储该表的数据、索引等信息,其余信息还是存放在共享表空间中,
例如undo_log ,buffer,Innodb表的元数据都放在ibdata1 里面 等等
InnoDB存储引擎文件包括以下几种:
重做日志文件:默认情况下,在InnoDB存储引擎的数据目录下会有两个名ib_logfile0和ib_logfile1的文件,叫重做日志文件,记录列对于InnoDB存储引擎的事务日志,当数据库实例重启时,InnoDB存储引擎会使用重做日志恢复到重启前的时刻,以此来保证数据的完整性
重做日志和二进制日志的区别在于:
二进制日志会记录所有MySQL数据库有关的日志记录,而重做日志仅记录有关InnoDB存储引擎本身的事务日志
二进制日志的内容是每个事务的具体操作内容,而重做日志文件记录的是关于每个数据页的更改情况

3 InnoDB 体系结构

4 Mysql 后台线程
mysql> use performance_schema mysql> select name,count(*) from threads group by name; +----------------------------------------+----------+ | name | count(*) | +----------------------------------------+----------+ | thread/innodb/buf_dump_thread | 1 | | thread/innodb/dict_stats_thread | 1 | | thread/innodb/io_ibuf_thread | 1 | | thread/innodb/io_log_thread | 1 | | thread/innodb/io_read_thread | 4 | | thread/innodb/io_write_thread | 4 | | thread/innodb/page_cleaner_thread | 1 | | thread/innodb/srv_error_monitor_thread | 1 | | thread/innodb/srv_lock_timeout_thread | 1 | | thread/innodb/srv_master_thread | 1 | | thread/innodb/srv_monitor_thread | 1 | | thread/innodb/srv_purge_thread | 1 | | thread/innodb/srv_worker_thread | 3 | | thread/sql/compress_gtid_table | 1 | | thread/sql/main | 1 | | thread/sql/one_connection | 1 | | thread/sql/signal_handler | 1 | | thread/sql/thread_timer_notifier | 1 | +----------------------------------------+----------+
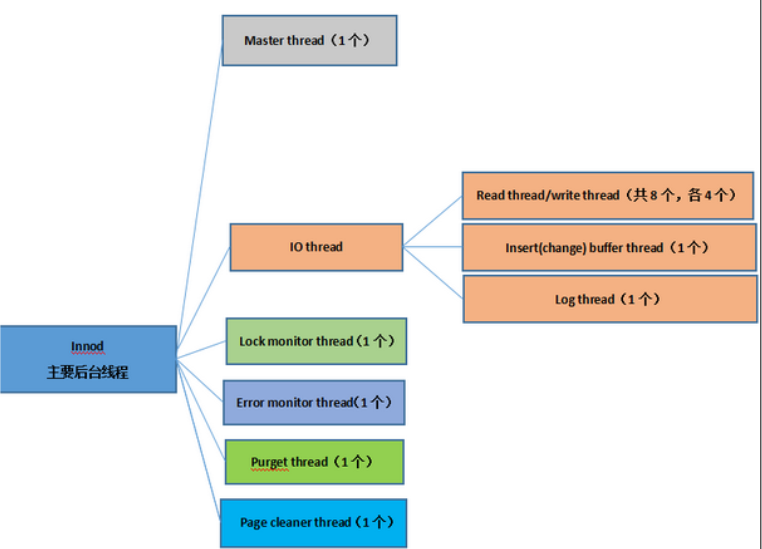
Master主线程
1、 Master thread线程的优先级最高,内部主要是4个循环loop组成:主循环、后台循环、刷新循环、暂停循环。
2、在master thread线程里,每1秒或每10秒会触发1oop(循环体)工作,loop为主循环,大多数情况下都运行在这个循环体。 loop通过sleep()来实现定时的操作,所以操作时间不精准。负载高的情况下可能会有延迟;
3、dirty page:当事务(Transaction)需要修改某条记录(row)时,InnoDB需要将该数据所在的page从disk读到buffer pool中,事务提交后,InnoDB修改page中的记录(row)。这时buffer pool中的page就已经和disk中的不一样了,我们称buffer pool中的被修改过的page为dirty page。 Dirty page等待flush到disk上。
4、insert buffer merge:
innodb使用insert buffer” 欺骗”数据库:对于为非唯一索引,辅助索引的修改操作并非实时更新索引的叶子页,而是把若干对同一页面的更新缓存起来做合并(merge)为一次性更新操作,转化随机IO为顺序IO,这样可以避免随机IO带来性能损耗,提高数据库的写性能。
(1)Insert Buffer是Innodb处理非唯一索引更新操作时的一个优化。最早的Insert Buffer,仅仅实现Insert操作的Buffer,这也是Insert Buffer名称的由来。在后续版本中,Innodb多次对Insert Buffer进行增强,到Innodb 5.5版本,Insert Buffer除了支持Insert,还新增了包括Update/Delete/Purge等操作的buffer功能,Insert Buffer也随之更名为Change Buffer。
(2)insert buffer merge分为主动给merge和被动merge。
(2.1)master thread线程里的insert buffer merge是主动merge,原理是:
a、若过去1秒内发生的IO小于系统IO能力的5%,则主动进行一次insert buffer merge(merge的页面数为系统IO能力的5%且读取page采用async io模式)。
b、每10秒,必须触发一次insert buffer merge(merge的页面数仍旧为系统IO能力的5%)
(2.2)被动Merge,则主要是指在用户线程执行的过程中,由于种种原因,需要将insert buffer的修改merge到page之中。被动Merge由用户线程完成,因此用户能够感知到merge操作带来的性能影响。
例如:
a、 Insert操作,导致页面空间不足,需要分裂。由于insert buffer只能针对单页面,不能buffer page split,因此引起页面的被动Merge;
b、 insert操作,由于其他各种原因,insert buffer优化返回失败,需要真正读取page时,也需要进行被动Merge;
c、在进行insert buffer操作时,发现insert buffer已经太大,需要压缩insert buffer。
5、 check point:
(1)checkpoint干的事情:将缓冲池中的脏页刷新到磁盘
(2)checkpoint解决的问题:
a、缩短数据库的恢复时间(数据库宕机时,不需要重做所有的日志,因checkpoint之前的页都已经刷新回磁盘啦)
b、缓冲池不够用时,将脏页刷新到磁盘(缓冲池不够用时,根
据LRU算法算出最近最少使用的页,若此页为脏页,需要强制执行checkpoint将脏也刷回磁盘)
c、重做日志不可用时,刷新脏页(采用循环使用的,并不是无限增大。当重用时,此时的重做日志还需要使用,就必须强制执行checkpoint将脏页刷回磁盘)
IO thread
在innodb存储引擎中大量使用AIO来处理IO请求,这样可以极大提高数据库的性能,而IO thread的工作就是负责这些IO请求的回调处理(call back);
lock monitor thread
error monitor thread
purge thread
1、 事务被提交后,其所使用的undo log可能将不再需要,因此需要purge thread来回收已经使用并分配的undo页;
2、从mysql5.5开始,purge操作不再做主线程的一部分,而作为独立线程。
3、开启这个功能:innodb_purge_threads=1。调整innodb_purge_batch_size来优化purge操作,batch size指一次处理多少undo log pages, 调大这个参数可以加块undo log清理(类似oracle的undo_retention)。
从mysql5.6开始,innodb_purge_threads调整范围从0–1到0–32,支持多线程purge,innodb-purgebatch-size会被多线程purge共享
page cleaner thread
page cleaner thread是在innodb1.2.x中引用的,作用是将之前版本中脏页的刷新操作都放入到单独的线程中来完成,其目的是为了减轻master thread的工作及对于用户查询线程的阻塞,进一步提高innodb存储引擎的性能。
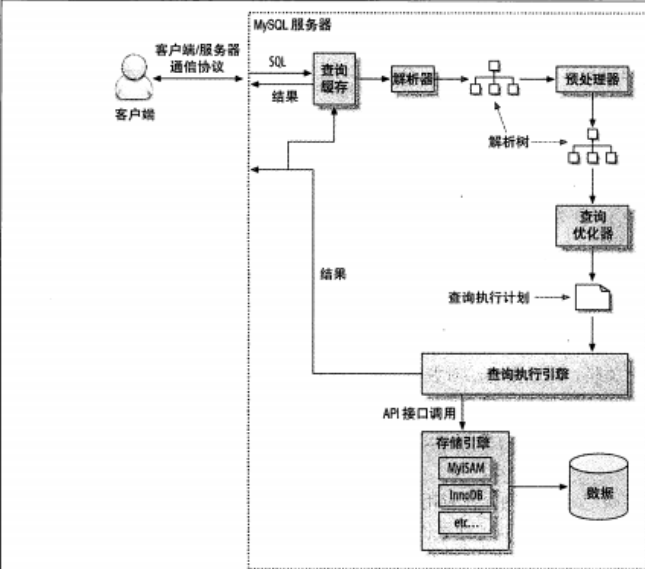
5 MySQL语句执行过程
mysql执行一个查询的过程,执行的步骤包括:
-
客户端发送一条查询给服务器;
-
服务器先检查查询缓存,如果命中了缓存,则立刻返回存储在缓存中的结果。否则进入下一阶段。
-
服务器段进行SQL解析、预处理,在优化器生成对应的执行计划;
-
mysql根据优化器生成的执行计划,调用存储引擎的API来执行查询。
-
将结果返回给客户端。
简单的来说:
SQL权限的检查 –>SQL语法语意分析 –> 查询缓存 –> 服务器SQL解析 –> 执行
5.1 查询状态
对于mysql连接,任何时刻都有一个状态,该状态表示了mysql当前正在做什么。
使用show full processlist命令查看当前状态。在一个查询生命周期中,状态会变化很多次,下面是这些状态的解释:
sleep:线程正在等待客户端发送新的请求;query:线程正在执行查询或者正在将结果发送给客户端;
locked:在mysql服务器层,该线程正在等待表锁。
analyzing and statistics:线程正在收集存储引擎的统计信息,并生成查询的执行计划;
copying to tmp table:线程在执行查询,并且将其结果集复制到一个临时表中,这种状态一般要么是做group by操作,要么是文件排序操作,或者union操作。如果这个状态后面还有on disk标记,那表示mysql正在将一个内存临时表放到磁盘上。
sorting Result:线程正在对结果集进行排序。
sending data:线程可能在多个状态间传送数据,或者在生成结果集,或者在想客户端返回数据。
5.2 查询缓存
在解析一个查询语句之前,如果查询缓存是打开的,那么mysql会优先检查这个查询是否命中查询缓存中的数据。这个检查是通过一个对大小写敏感的哈希查找实现的。这个检查是通过一个对大小写敏感的哈希查找实现的。
如果当前的查询恰好命中了查询缓存,那么在返回查询结果之前mysql会检查一次用户权限。这仍然是无须解析查询SQL语句的,因为在查询缓存中已经存放了当前查询需要访问的表信息。如果权限没有问题,mysql会跳过所有其他阶段,直接从缓存中拿到结果并返回给客户端。没权限这种情况下,查询不会被解析,不用生成执行计划,不会被执行。
5.3 查询优化处理
查询的生命周期的下一步是将一个SQL转换成一个执行计划,mysql在依照这个执行计划和存储引擎进行交互。这包含多个子阶段:解析SQL、预处理、优化SQL执行计划。这个过程中任何错误都可能终止查询
语法解析器和预处理:首先mysql通过关键字将SQL语句进行解析,并生成一颗对应的“解析树”。 mysql
解析器将使用mysql语法规则验证和解析查询;预处理器则根据一些mysql规则进一步检查解析树是否合法。
查询优化器:当语法树被认为是合法的了,并且由优化器将其转化成执行计划。 一条查询SQL语句可以有很多种执行方式,最后都返回相同的结果。优化器的作用就是找到这其中最好的执行计划。
执行计划:mysql不会生成查询字节码来执行查询,mysql生成查询的一棵指令树,然后通过存储引擎执行完成这棵指令树并返回结果。最终的执行计划包含了重构查询的全部信息。
5.4 查询执行引擎
在解析和优化阶段,mysql将生成查询对应的执行计划,mysql的查询执行引擎则根据这个执行计划来完成整个查询。这里执行计划是一个数据结构,而不是和很多其他的关系型数据库那样对应的字节码 mysql简单的根据执行计划给出的指令逐步执行。在根据执行计划逐步执行的过程中,有大量的操作需要通过调用存储引擎实现的接口来完成。为了执行查询,mysql只需要重复执行计划中的各个操作,直到完成所有的数据查询。
5.5 返回结果给客户端
查询执行的最后一个阶段是将结果返回给客户端。即使查询不需要返回结果给客户端,mysql仍然会返回这个查询的一些信息,如该查询影响到的行数。如果查询可以被缓存,那么mysql在这个阶段也会将结果放到查询缓存中。
mysql将结果集返回客户端是一个增量、逐步返回的过程。这样有两个好处:
-
服务器端无须存储太多的结果,也就不会因为返回太多结果而消耗太多的内存;
-
这样处理也让mysql客户端第一时间获得返回的结果。
结果集中的每一行都会以一个满足mysql客户端/服务器通信协议的包发送,再通过tcp协议进行传输,在tcp传输的过程中,可能对mysql的封包进行缓存然后批量传输。
6 MySQL查询优化器
MySQL采用了基于开销的优化器,以确定处理查询的最解方式,也就是说执行查询之前,都会先选择一条自以为最优的方案,然后执行这个方案来获取结果。 在很多情况下, MySQL能够计算最佳的可能查询计划,但在某些情况下, MySQL没有关于数据的足够信息,或者是提供太多的相关数据信息,估测就不那么友好了
MySQL优化器中,一个主要的目标是只要可能就是用索引,而且使用条件最严格的索引来尽可能多、尽可能快地排除那些不符合索引条件的数据行,说白了就是选择怎样使用索引,当然优化器还受其他的影响。
6.1 影响优化器的使用有哪些
-
强制索引
通过FORCE INDEX(索引1[,索引2])或者使用USE INDEX(索引1[,索引2]),来指定使用哪个索引,也可以指定多个索引,让
优化器从中挑选。 -
忽略索引
可以使用IGNORE INDEX(索引1[,索引2])来忽略一些索引,这样优化器,就不会考虑使用这些所有,减少优化器优化时间。 -
STRAGHT_JOIN
这个会优化器使用数据表的顺序
一般情况下,MySQL优化器会自行决定按照哪种顺序扫描数据表才能最快地检索出数据,但是我们可以通过STRAGHT_JOIN强制优化器按特定的顺序使用数据表,毕竟优化器做的判断不一定都是最优的。
使用原则是:
让限制最强的选取操作最先执行。 STRAIGHT_JOIN可以放在SELECT后面,也可以放在FROM子句中。
注:STRAIGHT_JOIN只适用于inner join,并不使用与left join,right join。
6.2 查询优化器所做的事情
-
常量转化
它能够对sql语句中的常量进行转化,比如下面的表达式: WHERE col1 = col2 AND col2 = ‘x’; 依据传递性:如果A=B and B=C,那么就能得出A=C。所以上面的表达式mysql查询优化器能进行如下的优化:WHERE col1 = ‘x’ AND col2 = ‘x’ -
无效代码的排除
查询优化器会对一些无用的条件进行过滤,比如说 WHERE 0=0 AND column1=’y’ 因为第一个条件是始终为true的,所以可以移除该条件,变为:WHERE column1=’y’再见如下表达式:WHERE (0=1 AND s1=5) OR s1=7因为前一个括号内的表达式始终为false,因此可以移除该表达式,变为:WHERE s1=7
一些情况下甚至可 以将整个WHERE子句去掉,见下面的表达式:WHERE (0=1 AND s1=5)我们可以看到, WHERE子句始终为FALASE,那么WHERE条件是不可能发生的。当然我们也可以讲,WHERE条件被优化掉了 -
常量计算
如下表达式:WHERE col1 = 1 + 2转化为:WHERE col1 = 3 Mysql会对常量表达进行计算,然后将结果生成条件 -
存取类型
当我们评估一个条件表达式,MySQL判断该表达式的存取类型。下面是一些存取类型,按照从最优到最差的顺序进行排列:
system系统表,并且是常量表
const 常量表
eq_ref unique/primary索引,并且使用的是’=’进行存取
ref 索引使用’=’进行存取
ref_or_null 索引使用’=’进行存取,并且有可能为NULL
range 索引使用BETWEEN、 IN、 >=、 LIKE等进行存取
ALL 表全扫描
优化器根据存取类型选择合适的驱动表达式。考虑如下的查询语句:以下是引用片段:
SELECT * FROM Table1 WHERE indexed_column=5 AND unindexed_column=6
因为indexed_column拥有更好的存取类型,所以更有可能使用该表达式做为驱动表达式。考虑到这个查询语句有两种可能的执行方法:
1) 不好的执行路径:读取表的每一行(称为“全表扫描” ),对于读取到的每一行,检查相应的值是否满足indexed_column以及 unindexed_column对应的条件。
2) 好的执行路径:通过键值indexed_column=5查找B树,对于符合该条件的每一行,判断是否满足unindexed_column对应的条件。
一般情况下,索引查找比全表扫描需要更少的存取路径,尤其当表数据量很大,并且索引的类型是UNIQUE的时候。因此称它为好的执行路径,使用 indexed_column列作为驱动表达式。
-
范围存取类型
一些表达式可以使用索引,但是属于索引的范围查找。这些表达式通常对应的操作符是:>、 >=、 <、 <=、IN、 LIKE、 BETWEEN。
对优化器而言,如下表达式:
column1 IN (1,2,3)
该表达式与下面的表达式是等价的:
column1 = 1 OR column1 = 2 OR column1 = 3
并且 MySQL也是认为它们是等价的,所以没必要手动将IN改成OR,或者把OR改成IN。
优化器将会对下面的表达式使用索引范围查找:column1 LIKE ‘x%’,但对下面的表达式就不会使用到索引了:column1 LIKE ‘%x’,这是因为当首字符是通配符的时候, 没办法使用到索引进行范围查找。
对优化器而言,如下表达式:
column1 BETWEEN 5 AND 7
该表达式与下面的表达式是等价的:
column1 >= 5 AND column1 <= 7同样,
MySQL也认为它们是等价的。 -
索引存取类型
考虑如下的查询语句:SELECT column1 FROM Table1;如果column1是索引列, 优化器更有可能选择索引全扫描,而不是采用表全扫描。这是因为该索引覆盖了我们所需要查询的列。
再考虑如下的查询语句:
SELECT column1,column2 FROM Table1; 如果索引的定义如下,那么就可以使用索引全扫描:
CREATE INDEX … ON Table1(column1,column2);
也就是说,所有需要查询的列必须在索引中出现。但是如下的查询就只能走全表扫描了: select col3 from Table1;由于col3没有建立索引所以只能走全表扫描。 -
转换
MySQL对简单的表达式支持转换。比如下面的语法:
WHERE -5 = column1转换为: WHERE column1 = -5 尽管如此,对于有数学运算存在的情况不会进行转换。
比如下面的语法:
WHERE 5 = -column1不会转换为:WHERE column1 = -5,所以尽量减少列上的运算,而将运算放到常量上 -
AND
带AND的查询的格式为: AND ,考虑如下的查询语句:
WHERE column1=’x’ AND column2=’y’
优化的步骤:
1) 如果两个列都没有索引,那么使用全表扫描。
2) 否则,如果其中一个列拥有更好的存取类型(比如,一个具有索引,另外一个没有索引;再或者,一个是唯一索引,另外一个是非唯一索引),那么使用该列作为驱动表达式
-
OR
带OR的查询格式为: OR ,考虑如下的查询语句:WHERE column1=’x’ OR column2=’y’
优化器做出的选择是采用全表扫描。当然,在一些特定的情况,可以使用索引合并,这里不做阐述。如果两个条件里面设计的列是同一列,那么又是另外一种情况,考虑如下的查询语句:WHERE column1=’x’ OR column1=’y’在这种情况下,该查询语句采用索引范围查找 -
UNION
所有带UNION的查询语句都是单独优化的,考虑如下的查询语句:以下是引用片段:
SELECT * FROM Table1 WHERE column1='x' UNION ALL SELECT * FROM Table1 WHER column2='y'
-
order by
一般而言,ORDER BY的作用是使结果集按照一定的顺序排序,如果可以不经过此操作就能产生顺序的结果,可以跳过ORDER BY操作。考虑如下的查询 语句:
SELECT column1 FROM Table1 ORDER BY ‘x’;优化器将去除该ORDER BY子句,因为此处的ORDER BY 子句没有意义。再考虑另外的一个查询语句:SELECT column1 FROM Table1 ORDER BY column1;在这种情况下,如果column1类上存在索引,优化器将使用该索引进行全扫描,这样产生的结果集是有序的,从而不需要进行ORDER BY操作。
再考虑另外的一个查询语句:SELECT column1 FROM Table1 ORDER BY column1+1; 假设column1上存在索引,我 们也许会觉得优化器会对column1索引进行全扫描,并且不进行ORDER BY操作。实际上,情况并不是这样,优化器是使用column1列上的索引进行全扫表,仅仅是因为索引全扫描的效率高于表全扫描。对于索引全扫描的结果集 仍然进行ORDER BY排序操作
-
GROUP BY
这里列出对GROUP BY子句以及相关集函数进行优化的方法:
1) 如果存在索引,GROUP BY将使用索引。
2) 如果没有索引,优化器将需要进行排序,一般情况下会使用HASH表的方法
3) 如果情况类似于“GROUP BY x ORDER BY x”,优化器将会发现ORDER BY子句是没有必要的,因为GROUP BY产生的结果集是按照x进行排序的
4) 尽量将HAVING子句中的条件提升中WHERE子句中。
5) 对于MyISAM表,“SELECT COUNT(*) FROM Table1;”
直接返回结果,而不需要进行表全扫描。但是对于InnoDB表,则不适合该规则。补充一点,如果column1的定义是NOT NULL的,那么语句“SELECT COUNT(column1) FROM Table1;” 等价于“SELECT COUNT(*) FROM Table1;” 。
6) 考虑MAX()以及MIN()的优化情况。考虑下面的查询语句:以下是引用片段:
SELECT MAX(column1) FROM Table1 WHERE column1<’a’; 如果column1列上存在索引,优化器使用’a’进行索引定位,然后返回前一条记录。
7) 考虑如下的查询语句:
SELECT DISTINCT column1 FROM Table1;在特定的情况下,语句可以转化为:
SELECT column1 FROM Table1 GROUP BY column1;转换的前提条件是:column1上存 在索引, FROM上只有一个单表,没有WHERE条件并且没有LIMIT条件

 浙公网安备 33010602011771号
浙公网安备 33010602011771号