[开源] .Net ORM FreeSql 1.10.0 稳步向前
写在开头
FreeSql 是 .NET 开源生态下的 ORM 轮子,转眼快两年了,说真的开源不容易(只有经历过才明白)。今天带点干货和湿货给大家,先说下湿货。
认识我的人,知道 CSRedisCore 是我写的另外一个开源组件,这个项目是 2016 年从 ctstone/csredis 项目 clone 到自己工作的项目中,修改源码经过一年多生产考验,于 2017 年发布开源 https://github.com/2881099/csredis
ctstone/csredis 项目于 2014 年停止了更新,到我手里完善的功能如下:
- 连接池
- 哨兵高可用
- 集群
- redis 2.8 以上的版本命令补充,包括 Geo、Stream
- 通讯协议 bug 修复
暂时想到的只有这些,之后可能再补充。FreeSql 文章标题为什么要来说 csredis?
这两年的时间里 95% 精力都用在了 FreeSql 上面, 5400+ 单元测试、支持十几种数据库适配,渣男辜负了 csredis 这个项目。最近一个多月开源圈子的奇葩事接二连三,居然有人跑去 ctstone/csredis 原作者的 issues 告我的状,这个告状的人还是 NOPI 原作者,因为当初他自己不维护 NPOI .NET Core 版本了,社区有好人把 .NET Core 版本测试做好了开源(dotnetcore/NPOI),告状的人很真心厉害,已经成功把 nuget.org/dotnetcore.npoi 整下架了。
他并没有得到满足,之后开始针对整个 NCC 社区成员,包括我。
- 他去了 sqlsugar issues 发表,说要找出 FreeSql 抄袭 sqlsugar 的证据
- 他又去 fur issues 发表声援,说我黑他
- 他还去 csredis 原作者 issues 发布内容,企图告我的状
并不是人人都像你一样,强迫要求下游项目“归档”、“制裁”,试问 mysql 可以要求 mariadb 归档?针对 NCC 组织还是针对我本人?CSRedisCore 并不在 NCC 开源组织下!!!
几天月前我已经开始了新的 redis .NET 开源组件库的编写,完全自主的看你能上哪里告状。有了这么长时间的 csredis 经验,重新写一个能避免很多问题,设计也会更好,后面我会花大部分时间做新项目,这便是今天带来的湿货,敬请期待发布!~!
入戏准备
2018 年 12 月份开发 FreeSql 到现在,2200 颗星,500 Issues,200K 包下载量。说明还是有开发者关注和喜爱,只要有人关注,就不会停更不修 BUG 一说。大家有兴趣可以看看更新记录,看看我们的代码提交量,5400+ 单元测试不说非常多,个人觉得已经超过很多国产项目。
23个月了,FreeSql 还活着,而且生命力顽强见下图:
年底发布 2.0 版本正在收集需求中(欢迎前去 issues 诚意登记),本文将介绍在过去的几个月完成的一些有意义的功能介绍。
FreeSql 是 .Net ORM,能支持 .NetFramework4.0+、.NetCore、Xamarin、XAUI、Blazor、以及还有说不出来的运行平台,因为代码绿色无依赖,支持新平台非常简单。目前单元测试数量:5400+,Nuget下载数量:200K+,源码几乎每天都有提交。值得高兴的是 FreeSql 加入了 ncc 开源社区:https://github.com/dotnetcore/FreeSql,加入组织之后社区责任感更大,需要更努力做好品质,为开源社区出一份力。
QQ群:4336577(已满)、8578575(在线)、52508226(在线)
为什么要重复造轮子?

FreeSql 主要优势在于易用性上,基本是开箱即用,在不同数据库之间切换兼容性比较好。作者花了大量的时间精力在这个项目,肯请您花半小时了解下项目,谢谢。
FreeSql 整体的功能特性如下:
- 支持 CodeFirst 对比结构变化迁移;
- 支持 DbFirst 从数据库导入实体类;
- 支持 丰富的表达式函数,自定义解析;
- 支持 批量添加、批量更新、BulkCopy;
- 支持 导航属性,贪婪加载、延时加载、级联保存;
- 支持 读写分离、分表分库,租户设计;
- 支持 MySql/SqlServer/PostgreSQL/Oracle/Sqlite/Firebird/达梦/神通/人大金仓/翰高/MsAccess Ado.net 实现包,以及 Odbc 的专门实现包;
干货来了
1.5.0 -> 1.10.0 更新的重要功能如下:
一、增加 Firebird 数据库实现;
二、增加 人大金仓/神通 数据库的访问支持;
三、增加 GlobalFilter.ApplyIf 创建动态过滤器;
四、增加 ISelect.InsertInto 将查询转换为 INSERT INTO t1 SELECT ... FROM t2 执行插入;
五、增加 IncludeMany(a => a.Childs).ToList(a => new { a.Childs }) 指定集合属性返回;
六、增加 $"{a.Code}_{a.Id}" lambda 解析;
七、增加 lambda 表达式树解析子查询 ToList + string.Join() 产生 类似 group_concat 的效果;
八、增加 SqlExt 常用开窗函数的自定义表达式解析;
九、增加 ISelect/IInsert/IUpdate/IDelete CommandTimeout 方法设置命令超时;
十、完善 WhereDynamicFilter 动态过滤查询;
十一、增加 BeginEdit/EndEdit 批量编辑数据的功能;
十二、增加 父子表(树表)递归查询、删除功能;

FreeSql 使用非常简单,只需要定义一个 IFreeSql 对象即可:
static IFreeSql fsql = new FreeSql.FreeSqlBuilder()
.UseConnectionString(FreeSql.DataType.MySql, connectionString)
.UseAutoSyncStructure(true) //自动同步实体结构到数据库
.Build(); //请务必定义成 Singleton 单例模式
增加 Firebird 数据库实现;
它的体积比前辈Interbase缩小了几十倍,但功能并无阉割。为了体现Firebird短小精悍的特色,开发小组在增加了超级服务器版本之后,又增加了嵌入版本,最新版本为2.0。Firebird的嵌入版有如下特色:
1、数据库文件与Firebird网络版本完全兼容,差别仅在于连接方式不同,可以实现零成本迁移。
2、数据库文件仅受操作系统的限制,且支持将一个数据库分割成不同文件,突破了操作系统最大文件的限制,提高了IO吞吐量。
3、完全支持SQL92标准,支持大部分SQL-99标准功能。
4、丰富的开发工具支持,绝大部分基于Interbase的组件,可以直接使用于Firebird。
5、支持事务、存储过程、触发器等关系数据库的所有特性。
6、可自己编写扩展函数(UDF)。
7、firebird其实并不是纯粹的嵌入式数据库,embed版只是其众多版本中的一个。不过做的也很小,把几个dll加起来才不到5M,但是它支持绝大部份SQL92与SQL99标准
嵌入式,等于无需安装的本地数据库,欢迎体验!~~
增加 人大金仓/神通 数据库的访问支持
天津神舟通用数据技术有限公司(简称“神舟通用公司”),隶属于中国航天科技集团(CASC)。是国内从事数据库、大数据解决方案和数据挖掘分析产品研发的专业公司。公司获得了国家核高基科技重大专项重点支持,是核高基专项的牵头承担单位。自1993年在航天科技集团开展数据库研发以来,神通数据库已历经27年的发展历程。公司核心产品主要包括神通关系型数据库、神通KStore海量数据管理系统、神通商业智能套件等系列产品研发和市场销售。基于产品组合,可形成支持交易处理、MPP数据库集群、数据分析与处理等解决方案,可满足多种应用场景需求。产品通过了国家保密局涉密信息系统、公安部等保四级、军B +级等安全评测和认证。
北京人大金仓信息技术股份有限公司(以下简称“人大金仓”)是具有自主知识产权的国产数据管理软件与服务提供商。人大金仓由中国人民大学一批最早在国内开展数据库教学、科研、开发的专家于1999年发起创立,先后承担了国家“863”、“核高基”等重大专项,研发出了具有国际先进水平的大型通用数据库产品。2018年,人大金仓申报的“数据库管理系统核心技术的创新与金仓数据库产业化”项目荣获2018年度国家科学技术进步二等奖,产学研的融合进一步助力国家信息化建设。
随着华为、中兴事务,国产数据库市场相信是未来是趋势走向,纵观 .net core 整个圈子对国产神舟通用、人大金仓数据库的支持几乎为 0,今天 FreeSql ORM 可以使用 CodeFirst/DbFirst 两种模式进行开发。
并且声称:FreeSql 对各数据库没有亲儿子一说,除了 MsAcces 其他全部是亲儿子,在功能提供方面一碗水端平。

众所周知 EFCore for oracle 问题多,并且现在才刚刚更新到 3.x,在这样的背景下,一个国产数据库更不能指望谁实现好用的 EFCore。目前看来除了 EFCore for sqlserver 我们没把握完全占优势,起码在其他数据库肯定是我们更接地气。
使用 FreeSql 访问人大金仓/神通 数据库,只需要修改代码如下即可:
static IFreeSql fsql = new FreeSql.FreeSqlBuilder()
.UseConnectionString(FreeSql.DataType.ShenTong, connectionString) //修改 DataType 设置切换数据库
.UseAutoSyncStructure(true) //自动同步实体结构到数据库
.Build(); //请务必定义成 Singleton 单例模式
增加 GlobalFilter.ApplyIf 创建动态过滤器;
FreeSql 使用全局过滤器非常简单,我们的过滤器支持多表查询、子查询,只需要设置一次:
public static AsyncLocal<Guid> TenantId { get; set; } = new AsyncLocal<Guid>();
fsql.GlobalFilter
.Apply<ISoftDelete>("name1", a => a.IsDeleted == false)
.ApplyIf<ITenant>("tenant", () => TenantId.Value != Guid.Empty, a => a.TenantId == TenantId.Value);
上面增加了两个过滤器,tenant 第二个参数正是增加的功能,当委托条件成立时才会附加过滤器。
增加 ISelect.InsertInto 将查询转换为 INSERT INTO t1 SELECT ... FROM t2 执行插入;
int affrows = fsql.Select<Topic>()
.Limit(10)
.InsertInto(null, a => new Topic2
{
Title = a.Title
});
INSERT INTO `Topic2`(`Title`, `Clicks`, `CreateTime`)
SELECT a.`Title`, 0, '0001-01-01 00:00:00'
FROM `Topic` a
limit 10
注意:因为 Clicks、CreateTime 没有被选择,所以使用目标实体属性 [Column(InsertValueSql = xx)] 设置的值,或者使用目标实体属性的 c# 默认值。
又一次完善了批量操作数据的功能,之前已经有的功能如下:
- fsql.InsertOrUpdate 相当于 Merge Into/on duplicate key update
| Database | Features | Database | Features | |
|---|---|---|---|---|
| MySql | on duplicate key update | 达梦 | merge into | |
| PostgreSQL | on conflict do update | 人大金仓 | on conflict do update | |
| SqlServer | merge into | 神通 | merge into | |
| Oracle | merge into | MsAccess | 不支持 | |
| Sqlite | replace into | |||
| Firebird | merge into |
- fsql.Insert(数组).ExecuteAffrows() 相当于批量插入
var t2 = fsql.Insert(items).ExecuteAffrows();
//INSERT INTO `Topic`(`Clicks`, `Title`, `CreateTime`)
//VALUES(?Clicks0, ?Title0, ?CreateTime0), (?Clicks1, ?Title1, ?CreateTime1),
//(?Clicks2, ?Title2, ?CreateTime2), (?Clicks3, ?Title3, ?CreateTime3),
//(?Clicks4, ?Title4, ?CreateTime4), (?Clicks5, ?Title5, ?CreateTime5),
//(?Clicks6, ?Title6, ?CreateTime6), (?Clicks7, ?Title7, ?CreateTime7),
//(?Clicks8, ?Title8, ?CreateTime8), (?Clicks9, ?Title9, ?CreateTime9)
当插入大批量数据时,内部采用分割分批执行的逻辑进行。分割规则:
| 数量 | 参数量 | |
|---|---|---|
| MySql | 5000 | 3000 |
| PostgreSQL | 5000 | 3000 |
| SqlServer | 1000 | 2100 |
| Oracle | 500 | 999 |
| Sqlite | 5000 | 999 |
-
fsql.Insert(数组).ExecuteSqlBulkCopy、ExecutePgCopy、ExecuteMySqlBulkCopy
-
fsql.Update<T>().SetSource(数组).ExecuteAffrows() 相当于批量更新
增加 IncludeMany(a => a.Childs).ToList(a => new { a.Childs }) 指定集合属性返回;
这个功能实在太重要了,在此之前 IncludeMany 和 ToList(指定字段) 八字不合,用起来有些麻烦。现在终于解决了!!~~
var t111 = fsql.Select<Topic>()
.IncludeMany(a => a.TopicType.Photos)
.Where(a => a.Id <= 100)
.ToList(a => new
{
a.Id,
a.TopicType.Photos,
Photos2 = a.TopicType.Photos
});
增加 $"{a.Code}_{a.Id}" lambda 解析;
在之前查询数据的时候,$"" 这种语法糖神器居然不能使用在 lambda 表达式中,实属遗憾。现在终于可以了,如下:
var item = fsql.GetRepository<Topic>().Insert(new Topic { Clicks = 101, Title = "我是中国人101", CreateTime = DateTime.Parse("2020-7-5") });
var sql = fsql.Select<Topic>().WhereDynamic(item).ToSql(a => new
{
str = $"x{a.Id + 1}z-{a.CreateTime.ToString("yyyyMM")}{a.Title}{a.Title}"
});
Assert.Equal($@"SELECT concat('x',ifnull((a.`Id` + 1), ''),'z-',ifnull(date_format(a.`CreateTime`,'%Y%m'), ''),'',ifnull(a.`Title`, ''),'',ifnull(a.`Title`, ''),'') as1
FROM `tb_topic` a
WHERE (a.`Id` = {item.Id})", sql);
再次说明:都是亲儿子,并且都有对应的单元测试,兄台大可放心用在不同的数据库中
增加 lambda 表达式树解析子查询 ToList + string.Join() 产生 类似 group_concat 的效果;
v1.8.0+ string.Join + ToList 实现将子查询的多行结果,拼接为一个字符串,如:"1,2,3,4"
fsql.Select<Topic>().ToList(a => new {
id = a.Id,
concat = string.Join(",", fsql.Select<StringJoin01>().ToList(b => b.Id))
});
//SELECT a.`Id`, (SELECT group_concat(b.`Id` separator ',')
// FROM `StringJoin01` b)
//FROM `Topic` a
该语法,在不同数据库都作了相应的 SQL 翻译。
增加 SqlExt 常用的自定义表达式树解析;
SqlExt.cs 定义了一些常用的表达式树解析,如下:
fsql.Select<T1, T2>()
.InnerJoin((a, b) => b.Id == a.Id)
.ToList((a, b) => new
{
Id = a.Id,
EdiId = b.Id,
over1 = SqlExt.Rank().Over().OrderBy(a.Id).OrderByDescending(b.EdiId).ToValue(),
case1 = SqlExt.Case()
.When(a.Id == 1, 10)
.When(a.Id == 2, 11)
.When(a.Id == 3, 12)
.When(a.Id == 4, 13)
.When(a.Id == 5, SqlExt.Case().When(b.Id == 1, 10000).Else(999).End())
.End(), //这里因为复杂才这样,一般使用三元表达式即可:a.Id == 1 ? 10 : 11
groupct1 = SqlExt.GroupConcat(a.Id).Distinct().OrderBy(b.EdiId).Separator("_").ToValue()
});
本功能利用 FreeSql 自定义解析实现常用表达式树解析,欢迎 PR 补充
增加 ISelect/IInsert/IUpdate/IDelete CommandTimeout 方法设置命令超时;
现在每条 crud 都可以设置命令执行的超时值,如下:
fsql.Insert<items).CommandTimeout(60).ExecuteAffrows();
fsql.Delete<T>().Where(...).CommandTimeout(60).ExecuteAffrows();
fsql.Update<T>()
.Set(a => a.Clicks + 1)
.Where(...)
.CommandTimeout(60).ExecuteAffrows();
fsql.Select<T>().Where(...).CommandTimeout(60).ToList();
完善 WhereDynamicFilter 动态过滤查询
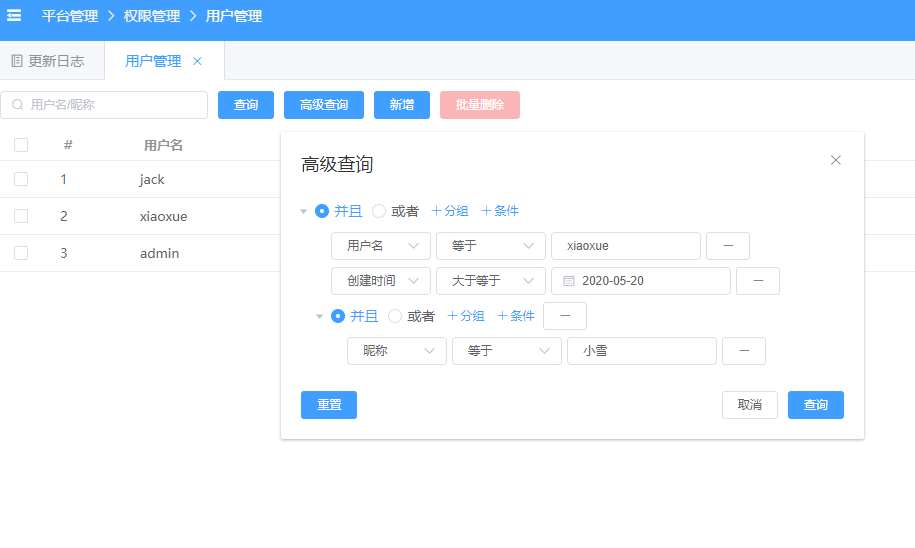
是否见过这样的高级查询功能,WhereDynamicFilter 在后端可以轻松完成这件事情,前端根据 UI 组装好对应的 json 字符串传给后端就行,如下:
DynamicFilterInfo dyfilter = JsonConvert.DeserializeObject<DynamicFilterInfo>(@"
{
""Logic"" : ""Or"",
""Filters"" :
[
{
""Field"" : ""Code"", ""Operator"" : ""NotContains"", ""Value"" : ""val1"",
""Filters"" : [{ ""Field"" : ""Name"", ""Operator"" : ""NotStartsWith"", ""Value"" : ""val2"" }]
},
{
""Field"" : ""Parent.Code"", ""Operator"" : ""Equals"", ""Value"" : ""val11"",
""Filters"" : [{ ""Field"" : ""Parent.Name"", ""Operator"" : ""Contains"", ""Value"" : ""val22"" }]
}
]
}");
fsql.Select<VM_District_Parent>().WhereDynamicFilter(dyfilter).ToList();
//SELECT a.""Code"", a.""Name"", a.""ParentCode"", a__Parent.""Code"" as4, a__Parent.""Name"" as5, a__Parent.""ParentCode"" as6
//FROM ""D_District"" a
//LEFT JOIN ""D_District"" a__Parent ON a__Parent.""Code"" = a.""ParentCode""
//WHERE (not((a.""Code"") LIKE '%val1%') AND not((a.""Name"") LIKE 'val2%') OR a__Parent.""Code"" = 'val11' AND (a__Parent.""Name"") LIKE '%val22%')
ISelect.WhereDynamicFilter 方法实现动态过滤条件(与前端交互),支持的操作符:
- Contains/StartsWith/EndsWith/NotContains/NotStartsWith/NotEndsWith:包含/不包含,like '%xx%',或者 like 'xx%',或者 like '%xx'
- Equal/NotEqual:等于/不等于
- GreaterThan/GreaterThanOrEqual:大于/大于等于
- LessThan/LessThanOrEqual:小于/小于等于
- Range:范围查询
- DateRange:日期范围,有特殊处理 value[1] + 1
- Any/NotAny:是否符合 value 中任何一项(直白的说是 SQL IN)
增加 BeginEdit/EndEdit 批量编辑数据的功能;
场景:winform 加载表数据后,一顿添加、修改、删除操作之后,点击【保存】
[Fact]
public void BeginEdit()
{
fsql.Delete<BeginEdit01>().Where("1=1").ExecuteAffrows();
var repo = fsql.GetRepository<BeginEdit01>();
var cts = new[] {
new BeginEdit01 { Name = "分类1" },
new BeginEdit01 { Name = "分类1_1" },
new BeginEdit01 { Name = "分类1_2" },
new BeginEdit01 { Name = "分类1_3" },
new BeginEdit01 { Name = "分类2" },
new BeginEdit01 { Name = "分类2_1" },
new BeginEdit01 { Name = "分类2_2" }
}.ToList();
repo.Insert(cts);
repo.BeginEdit(cts); //开始对 cts 进行编辑
cts.Add(new BeginEdit01 { Name = "分类2_3" });
cts[0].Name = "123123";
cts.RemoveAt(1);
Assert.Equal(3, repo.EndEdit());
}
class BeginEdit01
{
public Guid Id { get; set; }
public string Name { get; set; }
}
上面的代码 EndEdit 方法执行的时候产生 3 条 SQL 如下:
INSERT INTO "BeginEdit01"("Id", "Name") VALUES('5f26bf07-6ac3-cbe8-00da-7dd74818c3a6', '分类2_3')
UPDATE "BeginEdit01" SET "Name" = '123123'
WHERE ("Id" = '5f26bf00-6ac3-cbe8-00da-7dd01be76e26')
DELETE FROM "BeginEdit01" WHERE ("Id" = '5f26bf00-6ac3-cbe8-00da-7dd11bcf54dc')
提醒:该操作只对变量 cts 有效,不是针对全表对比更新。
增加 父子表(树表)递归查询、删除功能;
无限级分类(父子)是一种比较常用的表设计,每种设计方式突出优势的同时也带来缺陷,如:
- 方法1:表设计中只有 parent_id 字段,困扰:查询麻烦(本文可解决);
- 方法2:表设计中冗余子级id便于查询,困扰:添加/更新/删除的时候需要重新计算;
- 方法3:表设计中存储左右值编码,困扰:同上;
方法1设计最简单,我们正是解决它设计简单,使用复杂的问题。
首先,按照导航属性的定义,定义好父子属性:
public class Area
{
[Column(IsPrimary = true)]
public string Code { get; set; }
public string Name { get; set; }
public virtual string ParentCode { get; set; }
[Navigate(nameof(ParentCode))]
public Area Parent { get; set; }
[Navigate(nameof(ParentCode))]
public List<Area> Childs { get; set; }
}
定义 Parent 属性,在表达式中可以这样:
fsql.Select<Area>().Where(a => a.Parent.Parent.Parent.Name == "中国").First();
定义 Childs 属性,在表达式中可以这样(子查询):
fsql.Select<Area>().Where(a => a.Childs.AsSelect().Any(c => c.Name == "北京")).First();
定义 Childs 属性,还可以使用【级联保存】、【贪婪加载】 等等操作。
利用级联保存,添加测试数据如下:
fsql.Delete<Area>().Where("1=1").ExecuteAffrows();
var repo = fsql.GetRepository<Area>();
repo.DbContextOptions.EnableAddOrUpdateNavigateList = true;
repo.DbContextOptions.NoneParameter = true;
repo.Insert(new Area
{
Code = "100000",
Name = "中国",
Childs = new List<Area>(new[] {
new Area
{
Code = "110000",
Name = "北京",
Childs = new List<Area>(new[] {
new Area{ Code="110100", Name = "北京市" },
new Area{ Code="110101", Name = "东城区" },
})
}
})
});
功能1:ToTreeList
配置好父子属性之后,就可以这样用了:
var t1 = fsql.Select<Area>().ToTreeList();
Assert.Single(t1);
Assert.Equal("100000", t1[0].Code);
Assert.Single(t1[0].Childs);
Assert.Equal("110000", t1[0].Childs[0].Code);
Assert.Equal(2, t1[0].Childs[0].Childs.Count);
Assert.Equal("110100", t1[0].Childs[0].Childs[0].Code);
Assert.Equal("110101", t1[0].Childs[0].Childs[1].Code);
查询数据本来是平面的,ToTreeList 方法将返回的平面数据在内存中加工为树型 List 返回。
功能2:AsTreeCte 递归删除
很常见的无限级分类表功能,删除树节点时,把子节点也处理一下。
fsql.Select<Area>()
.Where(a => a.Name == "中国")
.AsTreeCte()
.ToDelete()
.ExecuteAffrows(); //删除 中国 下的所有记录
如果软删除:
fsql.Select<Area>()
.Where(a => a.Name == "中国")
.AsTreeCte()
.ToUpdate()
.Set(a => a.IsDeleted, true)
.ExecuteAffrows(); //软删除 中国 下的所有记录
功能3:AsTreeCte 递归查询
若不做数据冗余的无限级分类表设计,递归查询少不了,AsTreeCte 正是解决递归查询的封装,方法参数说明:
| 参数 | 描述 |
|---|---|
| (可选) pathSelector | 路径内容选择,可以设置查询返回:中国 -> 北京 -> 东城区 |
| (可选) up | false(默认):由父级向子级的递归查询,true:由子级向父级的递归查询 |
| (可选) pathSeparator | 设置 pathSelector 的连接符,默认:-> |
| (可选) level | 设置递归层级 |
通过测试的数据库:MySql8.0、SqlServer、PostgreSQL、Oracle、Sqlite、达梦、人大金仓
姿势一:AsTreeCte() + ToTreeList
var t2 = fsql.Select<Area>()
.Where(a => a.Name == "中国")
.AsTreeCte() //查询 中国 下的所有记录
.OrderBy(a => a.Code)
.ToTreeList(); //非必须,也可以使用 ToList(见姿势二)
Assert.Single(t2);
Assert.Equal("100000", t2[0].Code);
Assert.Single(t2[0].Childs);
Assert.Equal("110000", t2[0].Childs[0].Code);
Assert.Equal(2, t2[0].Childs[0].Childs.Count);
Assert.Equal("110100", t2[0].Childs[0].Childs[0].Code);
Assert.Equal("110101", t2[0].Childs[0].Childs[1].Code);
// WITH "as_tree_cte"
// as
// (
// SELECT 0 as cte_level, a."Code", a."Name", a."ParentCode"
// FROM "Area" a
// WHERE (a."Name" = '中国')
// union all
// SELECT wct1.cte_level + 1 as cte_level, wct2."Code", wct2."Name", wct2."ParentCode"
// FROM "as_tree_cte" wct1
// INNER JOIN "Area" wct2 ON wct2."ParentCode" = wct1."Code"
// )
// SELECT a."Code", a."Name", a."ParentCode"
// FROM "as_tree_cte" a
// ORDER BY a."Code"
姿势二:AsTreeCte() + ToList
var t3 = fsql.Select<Area>()
.Where(a => a.Name == "中国")
.AsTreeCte()
.OrderBy(a => a.Code)
.ToList();
Assert.Equal(4, t3.Count);
Assert.Equal("100000", t3[0].Code);
Assert.Equal("110000", t3[1].Code);
Assert.Equal("110100", t3[2].Code);
Assert.Equal("110101", t3[3].Code);
//执行的 SQL 与姿势一相同
姿势三:AsTreeCte(pathSelector) + ToList
设置 pathSelector 参数后,如何返回隐藏字段?
var t4 = fsql.Select<Area>()
.Where(a => a.Name == "中国")
.AsTreeCte(a => a.Name + "[" + a.Code + "]")
.OrderBy(a => a.Code)
.ToList(a => new {
item = a,
level = Convert.ToInt32("a.cte_level"),
path = "a.cte_path"
});
Assert.Equal(4, t4.Count);
Assert.Equal("100000", t4[0].item.Code);
Assert.Equal("110000", t4[1].item.Code);
Assert.Equal("110100", t4[2].item.Code);
Assert.Equal("110101", t4[3].item.Code);
Assert.Equal("中国[100000]", t4[0].path);
Assert.Equal("中国[100000] -> 北京[110000]", t4[1].path);
Assert.Equal("中国[100000] -> 北京[110000] -> 北京市[110100]", t4[2].path);
Assert.Equal("中国[100000] -> 北京[110000] -> 东城区[110101]", t4[3].path);
// WITH "as_tree_cte"
// as
// (
// SELECT 0 as cte_level, a."Name" || '[' || a."Code" || ']' as cte_path, a."Code", a."Name", a."ParentCode"
// FROM "Area" a
// WHERE (a."Name" = '中国')
// union all
// SELECT wct1.cte_level + 1 as cte_level, wct1.cte_path || ' -> ' || wct2."Name" || '[' || wct2."Code" || ']' as cte_path, wct2."Code", wct2."Name", wct2."ParentCode"
// FROM "as_tree_cte" wct1
// INNER JOIN "Area" wct2 ON wct2."ParentCode" = wct1."Code"
// )
// SELECT a."Code" as1, a."Name" as2, a."ParentCode" as5, a.cte_level as6, a.cte_path as7
// FROM "as_tree_cte" a
// ORDER BY a."Code"
更多姿势...请根据代码注释进行尝试
写在最后
给 .NET 开源社区贡献一点力时,希望作者的努力能打动到你,请求正在使用的、善良的您能动一动小手指,把文章转发一下,让更多人知道 .NET 有这样一个好用的 ORM 存在。谢谢了!!
FreeSql 使用最宽松的开源协议 MIT https://github.com/dotnetcore/FreeSql,完全可以商用,文档齐全。QQ群:4336577(已满)、8578575(在线)、52508226(在线)
如果你有好的 ORM 实现想法,欢迎给作者留言讨论,谢谢观看!
2.0 版本意见正在登记中:https://github.com/dotnetcore/FreeSql/issues/469

 浙公网安备 33010602011771号
浙公网安备 33010602011771号