[开源] .Net orm FreeSql 1.5.0 最新版本(番号:好久不见)
废话开头
这篇文章是我有史以来编辑最长时间的,历时 4小时!!!原本我可以利用这 4小时编写一堆胶水代码,真心希望善良的您点个赞,谢谢了!!
很久很久没有写文章了,上一次还是在元旦发布 1.0 版本的时候,今年版本规划是每月底发布小版本(年底发布 2.0),全年的开源工作主要是收集用户需求增加功能,完善测试,修复 bug。FreeSql 1.0 -> 1.5 相隔半年有哪些新功能?只能说每个功能都能让我兴奋,并且能感受到使用者也一样兴奋(妄想症)。

迫不及待的人会问,这更新速度也太快了吧,升级会不会有问题?
- 不了解版本的更新日志,直接升级不是好的习惯,建议关注我们的更新日志(github 上有专门的文档);
- 我们的版本开发原则:在尽量保证兼容的情况下,增加新功能,砍掉少量不合理的功能;
- 我们的单元测试数量:4000+,这是我们引以自豪,发布版本的保障;
入戏准备
FreeSql 是 .Net ORM,能支持 .NetFramework4.0+、.NetCore、Xamarin、XAUI、Blazor、以及还有说不出来的运行平台,因为代码绿色无依赖,支持新平台非常简单。目前单元测试数量:4000+,Nuget下载数量:123K+,源码几乎每天都有提交。值得高兴的是 FreeSql 加入了 ncc 开源社区:https://github.com/dotnetcore/FreeSql,加入组织之后社区责任感更大,需要更努力做好品质,为开源社区出一份力。
QQ群:4336577(已满)、8578575(在线)、52508226(在线)
为什么要重复造轮子?

FreeSql 主要优势在于易用性上,基本是开箱即用,在不同数据库之间切换兼容性比较好。作者花了大量的时间精力在这个项目,肯请您花半小时了解下项目,谢谢。
FreeSql 整体的功能特性如下:
- 支持 CodeFirst 对比结构变化迁移;
- 支持 DbFirst 从数据库导入实体类;
- 支持 丰富的表达式函数,自定义解析;
- 支持 批量添加、批量更新、BulkCopy;
- 支持 导航属性,贪婪加载、延时加载、级联保存;
- 支持 读写分离、分表分库,租户设计;
- 支持 MySql/SqlServer/PostgreSQL/Oracle/Sqlite/达梦/翰高/MsAccess;
1.0 -> 1.5 更新的重要功能如下:
一、UnitOfWorkManager 工作单元管理器,可实现 Spring 事务设计;
二、IFreeSql.InsertOrUpdate 实现批量保存,执行时根据数据库自动适配执行 merge into 或者 on duplicate key update;
三、ISelect.WhereDynamicFilter 方法实现动态过滤条件(与前端交互);
四、自动适配表达式解析 yyyyMMdd 常用 c# 日期格式化;
五、IUpdate.SetSourceIgnore 方法实现忽略属性值为 null 的字段;
六、FreeSql.Provider.Dameng 基于 DmProvider Ado.net 访问达梦数据库;
七、自动识别 EFCore 常用的实体特性,FreeSql.DbContext 拥有和 EFCore 高相似度的语法,并且支持 90% 相似的 FluentApi;
八、ISelect.ToTreeList 扩展方法查询数据,把配置父子导航属性的实体加工为树型 List;
九、BulkCopy 相关方法提升大批量数据插入性能;
十、Sqlite :memrory: 内存模式;

FreeSql 使用非常简单,只需要定义一个 IFreeSql 对象即可:
static IFreeSql fsql = new FreeSql.FreeSqlBuilder()
.UseConnectionString(FreeSql.DataType.MySql, connectionString)
.UseAutoSyncStructure(true) //自动同步实体结构到数据库
.Build(); //请务必定义成 Singleton 单例模式
UnitOfWorkManager 工作单元管理器
public class SongService
{
BaseRepository<Song> _repo;
public SongService(BaseRepository<Song> repo)
{
_repo = repo;
}
[Transactional]
public virtual void Test1()
{
_repo.Insert(new Song { Title = "卡农1" }); //事务1
this.Test2();
}
[Transactional(Propagation = Propagation.Nested)] //嵌套事务,新的(不使用 Test1 的事务)
public virtual void Test2()
{
_repo.Insert(new Song { Title = "卡农2" });
}
}
BaseRepository 是 FreeSql.BaseRepository 包实现的通用仓储类,实际项目中可以继承它再使用。
Propagation 的模式参考了 Spring 事务,在以下几种模式:
- Requierd:如果当前没有事务,就新建一个事务,如果已存在一个事务中,加入到这个事务中,默认的选择。
- Supports:支持当前事务,如果没有当前事务,就以非事务方法执行。
- Mandatory:使用当前事务,如果没有当前事务,就抛出异常。
- NotSupported:以非事务方式执行操作,如果当前存在事务,就把当前事务挂起。
- Never:以非事务方式执行操作,如果当前事务存在则抛出异常。
- Nested:以嵌套事务方式执行。(上面的例子使用的这个)
UnitOfWorkManager 正是干这件事的。避免了每次对数据操作都要现获得 Session 实例来启动事务/提交/回滚事务还有繁琐的Try/Catch操作。这些也是 AOP(面向切面编程)机制很好的应用。一方面使开发业务逻辑更清晰、专业分工更加容易进行。另一方面就是应用 AOP 隔离降低了程序的耦合性使我们可以在不同的应用中将各个切面结合起来使用大大提高了代码重用度。
使用前准备第一步:配置 Startup.cs 注入
//Startup.cs
public void ConfigureServices(IServiceCollection services)
{
services.AddSingleton<IFreeSql>(fsql);
services.AddScoped<UnitOfWorkManager>();
services.AddFreeRepository(null, typeof(Startup).Assembly);
}
| UnitOfWorkManager 成员 | 说明 |
|---|---|
| IUnitOfWork Current | 返回当前的工作单元 |
| void Binding(repository) | 将仓储的事务交给它管理 |
| IUnitOfWork Begin(propagation, isolationLevel) | 创建工作单元 |
使用前准备第二步:定义事务特性
[AttributeUsage(AttributeTargets.Method)]
public class TransactionalAttribute : Attribute
{
/// <summary>
/// 事务传播方式
/// </summary>
public Propagation Propagation { get; set; } = Propagation.Requierd;
/// <summary>
/// 事务隔离级别
/// </summary>
public IsolationLevel? IsolationLevel { get; set; }
}
使用前准备第三步:引入动态代理库
在 Before 从容器中获取 UnitOfWorkManager,调用它的 var uow = uowManager.Begin(attr.Propagation, attr.IsolationLevel) 方法
在 After 调用 Before 中的 uow.Commit 或者 Rollback 方法,最后调用 uow.Dispose
自问自答:是不是进方法就开事务呢?
不一定是真实事务,有可能是虚的,就是一个假的 unitofwork(不带事务),也有可能是延用上一次的事务,也有可能是新开事务,具体要看传播模式。
IFreeSql.InsertOrUpdate 批量插入或更新
IFreeSql 定义了 InsertOrUpdate 方法实现批量插入或更新的功能,利用的是数据库特性进行保存,执行时根据数据库自动适配:
| Database | Features |
|---|---|
| MySql | on duplicate key update |
| PostgreSQL | on conflict do update |
| SqlServer | merge into |
| Oracle | merge into |
| Sqlite | replace into |
| Dameng | merge into |
fsql.InsertOrUpdate<T>()
.SetSource(items) //需要操作的数据
.ExecuteAffrows();
由于我们前面定义 fsql 变量的类型是 MySql,所以执行的语句大概是这样的:
INSERT INTO `T`(`id`, `name`) VALUES(1, '001'), (2, '002'), (3, '003'), (4, '004')
ON DUPLICATE KEY UPDATE
`name` = VALUES(`name`)
当实体类有自增属性时,批量 InsertOrUpdate 最多可被拆成两次执行,内部计算出未设置自增值、和有设置自增值的数据,分别执行 insert into 和 上面讲到的 merge into 两种命令(采用事务执行)。
WhereDynamicFilter 动态过滤
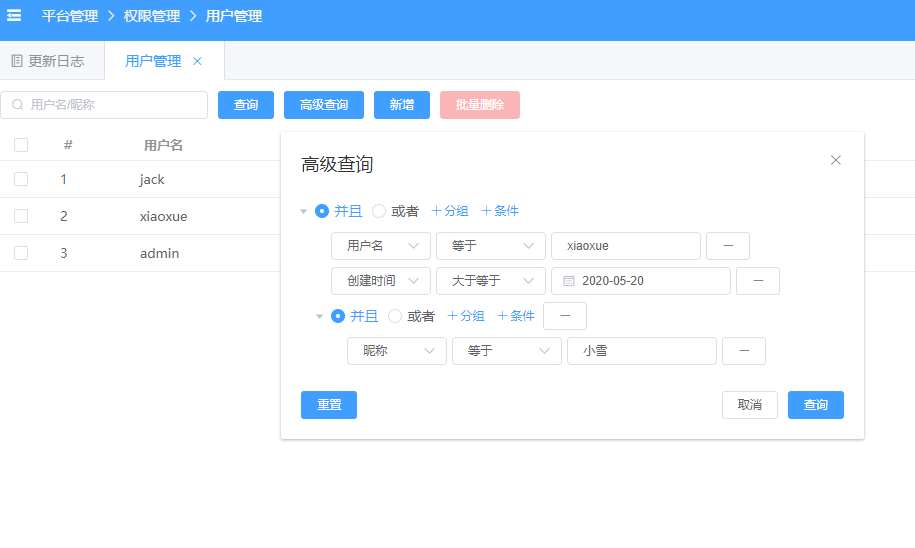
是否见过这样的高级查询功能,WhereDynamicFilter 在后端可以轻松完成这件事情,前端根据 UI 组装好对应的 json 字符串传给后端就行,如下:
DynamicFilterInfo dyfilter = JsonConvert.DeserializeObject<DynamicFilterInfo>(@"
{
""Logic"" : ""Or"",
""Filters"" :
[
{
""Field"" : ""Code"",
""Operator"" : ""NotContains"",
""Value"" : ""val1"",
""Filters"" :
[
{
""Field"" : ""Name"",
""Operator"" : ""NotStartsWith"",
""Value"" : ""val2"",
}
]
},
{
""Field"" : ""Parent.Code"",
""Operator"" : ""Eq"",
""Value"" : ""val11"",
""Filters"" :
[
{
""Field"" : ""Parent.Name"",
""Operator"" : ""Contains"",
""Value"" : ""val22"",
}
]
}
]
}
");
fsql.Select<VM_District_Parent>().WhereDynamicFilter(dyfilter).ToList();
//SELECT a.""Code"", a.""Name"", a.""ParentCode"", a__Parent.""Code"" as4, a__Parent.""Name"" as5, a__Parent.""ParentCode"" as6
//FROM ""D_District"" a
//LEFT JOIN ""D_District"" a__Parent ON a__Parent.""Code"" = a.""ParentCode""
//WHERE (not((a.""Code"") LIKE '%val1%') AND not((a.""Name"") LIKE 'val2%') OR a__Parent.""Code"" = 'val11' AND (a__Parent.""Name"") LIKE '%val22%')
支持的操作符:Contains/StartsWith/EndsWith/NotContains/NotStartsWith/NotEndsWith、Equals/Eq/NotEqual、GreaterThan/GreaterThanOrEqual、LessThan/LessThanOrEqual
表达式解析 yyyyMMdd c# 常用日期格式化
不知道大家有没有这个困扰,在 ORM 表达式使用 DateTime.Now.ToString("yyyyMM") 是件很难转换的事,在我适配的这些数据库中,只有 MsAccess 可以直接翻译成对应的 SQL 执行。
这个想法来自另一个 ORM issues,我时不时会去了解其他 ORM 优点和缺陷,以便给 FreeSql 做补充。
想法出来之后当于,也就是昨天 2020/5/24 奋战一宿完成的,除了每个数据库进行编码适配外,更多的时间耗在了单元测试上,目前已全部通过(4000+单元测试不是吹的)。
仅以此功能让大家感受一下 FreeSql 的认真,他不是一些人口中所说的个人项目,谢谢。

var dtn = DateTime.Parse("2020-1-1 0:0:0");
var dts = Enumerable.Range(1, 12).Select(a => dtn.AddMonths(a))
.Concat(Enumerable.Range(1, 31).Select(a => dtn.AddDays(a)))
.Concat(Enumerable.Range(1, 24).Select(a => dtn.AddHours(a)))
.Concat(Enumerable.Range(1, 60).Select(a => dtn.AddMinutes(a)))
.Concat(Enumerable.Range(1, 60).Select(a => dtn.AddSeconds(a)));
foreach (var dt in dts)
{
Assert.Equal(dt.ToString("yyyy-MM-dd HH:mm:ss.fff"), fsql.Select<T>().First(a => dt.ToString()));
Assert.Equal(dt.ToString("yyyy-MM-dd HH:mm:ss"), fsql.Select<T>().First(a => dt.ToString("yyyy-MM-dd HH:mm:ss")));
Assert.Equal(dt.ToString("yyyy-MM-dd HH:mm"), fsql.Select<T>().First(a => dt.ToString("yyyy-MM-dd HH:mm")));
Assert.Equal(dt.ToString("yyyy-MM-dd HH"), fsql.Select<T>().First(a => dt.ToString("yyyy-MM-dd HH")));
Assert.Equal(dt.ToString("yyyy-MM-dd"), fsql.Select<T>().First(a => dt.ToString("yyyy-MM-dd")));
Assert.Equal(dt.ToString("yyyy-MM"), fsql.Select<T>().First(a => dt.ToString("yyyy-MM")));
Assert.Equal(dt.ToString("yyyyMMddHHmmss"), fsql.Select<T>().First(a => dt.ToString("yyyyMMddHHmmss")));
Assert.Equal(dt.ToString("yyyyMMddHHmm"), fsql.Select<T>().First(a => dt.ToString("yyyyMMddHHmm")));
Assert.Equal(dt.ToString("yyyyMMddHH"), fsql.Select<T>().First(a => dt.ToString("yyyyMMddHH")));
Assert.Equal(dt.ToString("yyyyMMdd"), fsql.Select<T>().First(a => dt.ToString("yyyyMMdd")));
Assert.Equal(dt.ToString("yyyyMM"), fsql.Select<T>().First(a => dt.ToString("yyyyMM")));
Assert.Equal(dt.ToString("yyyy"), fsql.Select<T>().First(a => dt.ToString("yyyy")));
Assert.Equal(dt.ToString("HH:mm:ss"), fsql.Select<T>().First(a => dt.ToString("HH:mm:ss")));
Assert.Equal(dt.ToString("yyyy MM dd HH mm ss yy M d H hh h"), fsql.Select<T>().First(a => dt.ToString("yyyy MM dd HH mm ss yy M d H hh h")));
Assert.Equal(dt.ToString("yyyy MM dd HH mm ss yy M d H hh h m s tt t").Replace("上午", "AM").Replace("下午", "PM").Replace("上", "A").Replace("下", "P"), fsql.Select<T>().First(a => dt.ToString("yyyy MM dd HH mm ss yy M d H hh h m s tt t")));
}
支持常用 c# 日期格式化,yyyy MM dd HH mm ss yy M d H hh h m s tt t
tt t 为 AM PM
AM PM 这两个转换不完美,勉强能使用。
IUpdate.SetSourceIgnore 不更新 null 字段
这个功能被用户提了几次,每一次都认为 FreeSql.Repository 的状态对比可以完成这件事。
这一次作者心疼他们了,为什么一定要用某个功能限制住使用者?大家是否经常听谁说 EF框架、MVC框架,框架的定义其实是约束+规范。
作者不想做这样的约束,作者更希望尽量提供多一些实用功能让用户自己选择,把项目定义为:功能组件。
fsql.Update<Song>()
.SetSourceIgnore(item, col => col == null)
.ExecuteAffrows();
第二个参数是 Func<object, bool> 类型,col 相当于属性的值,上面的代码更新实体 item 的时候会忽略 == null 的属性。

Ado.net 访问达梦数据库
武汉达梦数据库有限公司成立于2000年,为中国电子信息产业集团(CEC)旗下基础软件企业,专业从事数据库管理系统的研发、销售与服务,同时可为用户提供大数据平台架构咨询、数据技术方案规划、产品部署与实施等服务。多年来,达梦公司始终坚持原始创新、独立研发,目前已掌握数据管理与数据分析领域的核心前沿技术,拥有全部源代码,具有完全自主知识产权。
不知道大家没有听说过相关政策,政府推动国产化以后是趋势,虽然 .NET 不是国产,但是目前无法限制编程语言,当下正在对操作系统、数据库强制推进。

我们知道 EFCore for oracle 问题多,并且现在还没更新到 3.x,在这样的背景下,一个国产数据库更不能指望谁实现好用的 EFCore。目前看来除了 EFCore for sqlserver 我们没把握完全占优势,起码在其他数据库肯定是我们更接地气。
言归正传,达梦数据库其实蛮早就支持了,之前是以 Odbc 的方式实现的,后面根据使用者的反馈 Odbc 环境问题比较麻烦,经研究决定支持 ado.net 适配,让使用者更加方便。使用 ado.net 方式连接达梦只需要修改 IFreeSql 创建时候的类型即可,如下:
static IFreeSql fsql = new FreeSql.FreeSqlBuilder()
.UseConnectionString(FreeSql.DataType.Dameng, connectionString)
.UseAutoSyncStructure(true) //自动同步实体结构到数据库
.Build(); //请务必定义成 Singleton 单例模式
兼容 EFCore 实体特性、FluentApi
EFCore 目前用户量最多,为了方便一些项目过渡到 FreeSql,我们做了一些 “AI”:

- 自动识别 EFCore 实体特性:Key/Required/NotMapped/Table/Column
[Table("table01")] //这个其实是 EFCore 的特性
class MyTable
{
[Key]
public int Id { get; set; }
}
- 与 EFCore 90% 相似的 FluentApi
fsql.CodeFirst.Entity<Song>(eb => {
eb.ToTable("tb_song");
eb.Ignore(a => a.Field1);
eb.Property(a => a.Title).HasColumnType("varchar(50)").IsRequired();
eb.Property(a => a.Url).HasMaxLength(100);
eb.Property(a => a.RowVersion).IsRowVersion();
eb.Property(a => a.CreateTime).HasDefaultValueSql("current_timestamp");
eb.HasKey(a => a.Id);
eb.HasIndex(a => new { a.Id, a.Title }).IsUnique().HasName("idx_xxx11");
//一对多、多对一
eb.HasOne(a => a.Type).HasForeignKey(a => a.TypeId).WithMany(a => a.Songs);
//多对多
eb.HasMany(a => a.Tags).WithMany(a => a.Songs, typeof(Song_tag));
});
fsql.CodeFirst.Entity<SongType>(eb => {
eb.HasMany(a => a.Songs).WithOne(a => a.Type).HasForeignKey(a => a.TypeId);
eb.HasData(new[]
{
new SongType
{
Id = 1,
Name = "流行",
Songs = new List<Song>(new[]
{
new Song{ Title = "真的爱你" },
new Song{ Title = "爱你一万年" },
})
},
new SongType
{
Id = 2,
Name = "乡村",
Songs = new List<Song>(new[]
{
new Song{ Title = "乡里乡亲" },
})
},
});
});
public class SongType {
public int Id { get; set; }
public string Name { get; set; }
public List<Song> Songs { get; set; }
}
public class Song {
[Column(IsIdentity = true)]
public int Id { get; set; }
public string Title { get; set; }
public string Url { get; set; }
public DateTime CreateTime { get; set; }
public int TypeId { get; set; }
public SongType Type { get; set; }
public int Field1 { get; set; }
public long RowVersion { get; set; }
}
ISelect.ToTreeList 查询树型数据 List
这是几个意思?有做过父子关系的表应该知道的,把数据查回来了是平面的,需要再用递归转化为树型。考虑到这个功能实用性比较高,所以就集成了进来。来自单元测试的一段代码:
var repo = fsql.GetRepository<VM_District_Child>();
repo.DbContextOptions.EnableAddOrUpdateNavigateList = true;
repo.DbContextOptions.NoneParameter = true;
repo.Insert(new VM_District_Child
{
Code = "100000",
Name = "中国",
Childs = new List<VM_District_Child>(new[] {
new VM_District_Child
{
Code = "110000",
Name = "北京市",
Childs = new List<VM_District_Child>(new[] {
new VM_District_Child{ Code="110100", Name = "北京市" },
new VM_District_Child{ Code="110101", Name = "东城区" },
})
}
})
});
var t3 = fsql.Select<VM_District_Child>().ToTreeList();
Assert.Single(t3);
Assert.Equal("100000", t3[0].Code);
Assert.Single(t3[0].Childs);
Assert.Equal("110000", t3[0].Childs[0].Code);
Assert.Equal(2, t3[0].Childs[0].Childs.Count);
Assert.Equal("110100", t3[0].Childs[0].Childs[0].Code);
Assert.Equal("110101", t3[0].Childs[0].Childs[1].Code);
注意:实体需要配置父子导航属性
BulkCopy 大批量数据
原先 FreeSql 对批量数据操作就做得还可以,例如批量数据超过数据库某些限制的,会拆分执行,性能其实也还行。
本需求也是来自用户,然后就实现了,实现完了我还专门做了性能测试对比,sqlserver bulkcopy 收益比较大,mysql 收益非常小。
测试结果(52个字段,18W-50行数据,单位ms):
| 18W | 1W | 5K | 500 | 50 | |
|---|---|---|---|---|---|
| MySql 5.5 ExecuteAffrows | 38,481 | 2,234 | 1,136 | 167 | 30 |
| MySql 5.5 ExecuteMySqlBulkCopy | 28,405 | 1,142 | 657 | 592 | 22 |
| SqlServer Express ExecuteAffrows | 402,355 | 24,847 | 11,465 | 915 | 88 |
| SqlServer Express ExecuteSqlBulkCopy | 21,065 | 578 | 326 | 79 | 48 |
| PostgreSQL 10 ExecuteAffrows | 46,756 | 3,294 | 2,269 | 209 | 37 |
| PostgreSQL 10 ExecutePgCopy | 10,090 | 583 | 337 | 61 | 25 |
| Oracle XE ExecuteAffrows | - | - | - | 10,648 | 200 |
| Sqlite ExecuteAffrows | 28,554 | 1,149 | 701 | 91 | 35 |
Oracle 插入性能不用怀疑,可能安装学生版限制较大
测试结果(10个字段,18W-50行数据,单位ms):
| 18W | 1W | 5K | 500 | 50 | |
|---|---|---|---|---|---|
| MySql 5.5 ExecuteAffrows | 11,171 | 866 | 366 | 50 | 34 |
| MySql 5.5 ExecuteMySqlBulkCopy | 6,504 | 399 | 257 | 100 | 16 |
| SqlServer Express ExecuteAffrows | 47,204 | 2,275 | 1,108 | 123 | 16 |
| SqlServer Express ExecuteSqlBulkCopy | 4,248 | 127 | 71 | 14 | 10 |
| PostgreSQL 10 ExecuteAffrows | 9,786 | 568 | 336 | 34 | 6 |
| PostgreSQL 10 ExecutePgCopy | 4,081 | 167 | 93 | 12 | 2 |
| Oracle XE ExecuteAffrows | - | - | - | 731 | 33 |
| Sqlite ExecuteAffrows | 4,524 | 246 | 137 | 19 | 11 |
测试结果,是在相同操作系统下进行的,并且都有预热
ExecuteMySqlBulkCopy 方法在 FreeSql.Provider.MySqlConnector 中实现的
Sqlite :memory: 内存模式
了解 EFCore 应该知道有一个 inMemory 实现,Sqlite 其实也有内存模式,所以在非常棒(忍不住)的 FreeSql.Provider.Sqlite 稍加适配就可以实现 inMemory 模式了。
使用 inMemory 模式非常简单,只需要修改 IFreeSql 创建的类型,以及连接字符串即可:
static IFreeSql fsql = new FreeSql.FreeSqlBuilder()
.UseConnectionString(FreeSql.DataType.Sqlite, "Data Source=:memory:")
.UseAutoSyncStructure(true) //自动同步实体结构到数据库
.Build(); //请务必定义成 Singleton 单例模式
内存模式 + FreeSql CodeFirst 功能,用起来体验还是不错的。因为每次都要迁移结构,fsql 释放数据就没了。
终于写完了

终于写完了,这篇文章是我有史以来编辑最长时间的,历时 4小时!!!原本我可以利用这 4小时编写一堆胶水代码,却非要写推广的文章,真心希望正在使用的、善良的您能动一动小手指,把文章转发一下,让更多人知道 .NET 有这样一个好用的 ORM 存在。谢谢了!!
FreeSql 开源协议 MIT https://github.com/dotnetcore/FreeSql,可以商用,文档齐全。QQ开发群:4336577(已满)、8578575(在线)、52508226(在线)
CSRedisCore 说:FreeSql 的待遇也好太多了。
如果你有好的 ORM 实现想法,欢迎给作者留言讨论,谢谢观看!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号