


超大文件排序
第1步> 超大文件排序
https://www.cnblogs.com/iois/p/9786233.html
第2步> 胜者树-败者树-归并选择排序(详解)
https://blog.csdn.net/weixin_44489823/article/details/103304290
(重点:) https://blog.csdn.net/weixin_39609051/article/details/111332041
如何编译测试文件生成程序和排序程序
c++,Vs2013下开发,win10 64。
2015/10/30
如何生成测试文件
1、随机生成一个字符串
即: 随机生成一个长度n的字符串;
- 思想:
新建一个空的字符串,然后每次在字符表的字典中随机取一个元素,添加到字符串中,重复n次;
但是效率比较低。
-
改进:
- 若内存允许,将
字符表中的单个元素两两组合,得到一个元素长度为2的字符串集合的候选列表。 - 同理,由字符表和元素长度为2的字符串集合的候选列表可以得到元素长度为3的字符串集合的候选列表....以此类推。
- 将包含单个字符的字符表,元素长度为2的字符串集合的候选列表,元素长度为3的字符串集合的候选列表放到一个表里面,得到最终的
候选字符串列表。
- 若内存允许,将
-
算法:
- 新建一个空的字符串
- 每次从
候选字符串列表中随机选择一个字符串,添加到字符串中,重复n次。 - 将字符串存到文件中,重复足够多次,得到随机文件。
如何执行排序程序
- 算法步骤(两步):
- 对每一个大文件进行排序,
- 对这几个排序好了的大文件多路归并合并到一个文件中。
-
步骤1
这里借用快速排序(分治)的思想,将文件分成足够小的小文件,并用一个树结构保存生成的文件名。step1,将选取文件第一个字符串作为标准字符串,将文件分成两个较小的文件;
step2,第一个文件中所有的字符串比标准字符串小或等于,第二个文件中所有的字符串比标准字符串大;
step3,判断生成的文件的大小,若足够小,则对其中的数据全部读入内存,排序;若还是比较大,则对该文件继续执行step1。
step4 合并。每个足够小的文件中的内容都排序后,根据纪录分解过程的树的最外围的子叶节点所记录的文件进行合并(已知前一个文件中所有的元素比后面文件中的小,只要把后一个文件追加到前一个就可以)。生成一个已经拍好序的大文件。
step5 根据据纪录分解过程的树,删除分解过程中生成的临时文件。
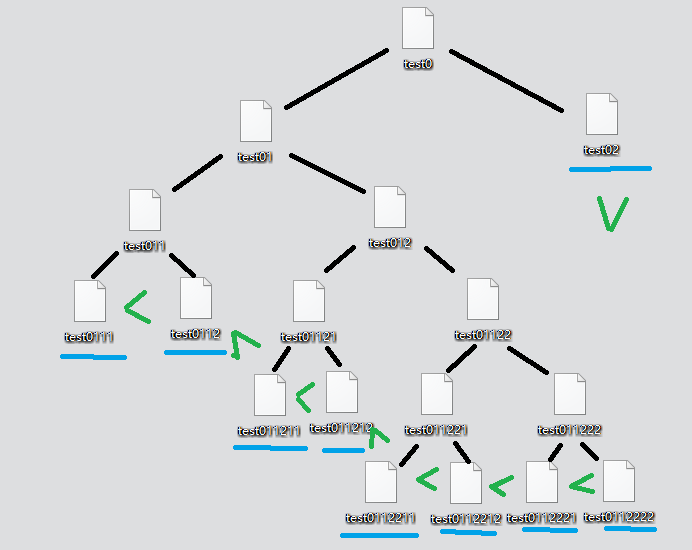
如图,每个节点代表一个文件,节点的左子节点的文件中的所有的字符串 比 右子节点的文件中的所有的字符串 小。
将所有最外围的叶节点依次排序,就能得到排好序的大文件。
结果示例。
- 步骤2
- 对每个已经排好序的大文件,读取其第一个元素,放到内存中,按顺序组成一个列表;取列表中最小的元素作为追加到 输出文件中。
- 再从最小元素所在的文件中读取一个元素,放到列表的相应位置。
- 如此反复,知道所有文件被读完。

