
GCC编译器原理(一)04------GCC 工具:nlmconv、nm、objcopy、objdump和 ranlib
1.3.13 nlmconv
nlmconv 将可重定位的对象文件(Infile)转换为 NetWare 可加载模块(outfile),并可选择读取头文件信息获取 NLM 头信息。
选项,描述
|
-I bfdname |
--input-target=bfdname 指定源文件得格式为 bfdname |
|
-O bfdname |
--output-target=bfdname 使用对象格式bfdname编写输出文件。 nlmconv 根据输入格式推断输出格式,例如对于 i386 输入文件,输出格式为 nlm32-i386。 |
|
-T headerfile |
--header-file=headerfile 从 NLM 头信息中读取头文件。 |
|
-V |
--version 显示 nlmconv 的版本号并退出。 |
|
-h |
--help 显示 nlmconv 的帮助信息并退出。 |
1.3.14 nm:列出目标文件中的符号
nm用来列出目标文件中的符号,可以帮助程序员定位和分析执行程序和目标文件中的符号信息和它的属性。利用命令行选项,可以根据符号的地址、尺寸或名字组织这些符号,而且可以按照很多方式格式化该输出结果。符号也可以被demangled,产生的结果和源代码中的一样。
如果没有目标文件作为参数传递给nm,nm 假定目标文件为 a.out。
来个例子:
bye.c
1 #include <stdio.h> 2 #include <stdlib.h> 3 4 void bye(void) 5 { 6 printf("good bye!\n"); 7 }
hello.c
1 #include <stdio.h> 2 #include <stdlib.h> 3 4 void hello(void) 5 { 6 printf("hello!\n"); 7 }
main.c
1 #include <stdio.h> 2 #include <stdlib.h> 3 4 int main(int argc, char *argv[]) 5 { 6 hello(); 7 bye(); 8 return 0; 9 }
执行命令: gcc -Wall -c main.c hello.c bye.c
gcc 生成 main.o,hello.o,bye.o 三个目标文件(这里没有声明函数原型,加了-Wall,gcc会给出警告)
执行命令:nm main.o hello.o bye.o
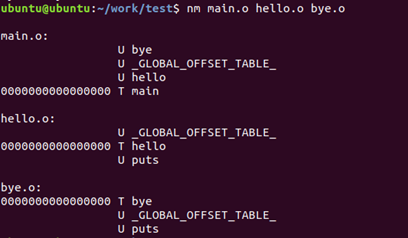
-
结合这些输出结果,以及程序代码,可以知道:
- 对于main.o, bye和hello未被定义, main被定义了
- 对于hello.o,hello被定义了,puts未被定义
- 对于bye.o, bye被定义了,puts未被定义
-
几个值得注意的问题:
-
"目标文件" 指 .o文件, 库文件, 最终的可执行文件
- .o : 编译后的目标文件,即含有最终编译出的机器码,但它里面所引用的其他文件中函数的内存位置尚未定义.
- 如果用 nm 查看可执行文件,输出会比较多,仔细研究输出,可以对 nm 用法有更清醒的认识。
- 在上述 hello.c,bye.c 中,调用的是 printf(),而 nm 输出中显示调用的是 puts(),说明最终程序实际调用的 puts(),如果令 hello.c 或 bye.c 中的 printf() 使用格式化输出,则 nm 显示调用 printf()。( 如: printf("%d", 1); )
-
|
选项 |
描述 |
|
-A |
同选项 --print-file-name |
|
-a |
同选项 --debug-syms |
|
-B |
同选项 --format=bsd。这是默认设置 |
|
-C [type] |
同选项 --demangle |
|
-D |
同选项 –dynamic |
|
--debug-syms |
显示调试器使用的符号。通常不会显示这些符号 |
|
--demangle[=type] |
demangles 符号,使它变回源代码中找到的用户级的名字。如果指定类型,会为如下类型之一:auto、gnu、lucid、arm、hp、edg、gnu-v3、java、gnat 或 compaq |
|
--dynamic |
对于动态目标,例如共享库,该选项可以显示动态符号而不是普通符号 |
|
--extern-only |
显示定义为外部的符号 |
|
-f fmt |
同选项 --format |
|
--format=fmt |
使用指定的输出格式显示符号。可选的格式包括 bsd、sysv 和 posix,其中 bsd 为默认格式 |
|
-g |
同选项 --extern-only |
|
-h |
显示选项列表,然后退出 |
|
--help |
显示选项列表,然后退出 |
|
-l |
同选项 --line-numbers |
|
--line-numbers |
使用文件中保存的调试信息来确定文件名和每个符号的行号 |
|
-n |
同选项 --numeric-sort |
|
--no-sort |
指出不要将符号排序 |
|
--numeric-sort |
按照符号地址的数值排序 |
|
-o |
同选项 --print-file-name |
|
-p |
同选项 --no-sort |
|
-P |
同选项 --format=posix |
|
--portability |
同选项 --format=posix |
|
--print-armap |
在列举静态库成员符号时,该选项包含了模块的索引信息及其他信息,正是该模块含有所列符号 |
|
--print-file-name |
用源文件的名字标记每个符号,而不是只在文件头命名源文件 |
|
-r |
同选项 --reverse-sort |
|
--radix=base |
指出打印符号值的数字的进制。可选的为 d 的十进制、o 的八进制、或 x 的十六进制 |
|
--reverse-sort |
反序排列,不论字母还是数字均可 |
|
-s |
同选项 --print-armap |
|
--size-sort |
按照尺寸进行符号排序。计算尺寸取的是下一个符号的最高地址和本符号的地址的差。输出列出的是尺寸而不是通常的地址 |
|
-t base |
同选项 --radix |
|
--target=bfdname |
bfdname 是目标文件格式的名字,它不是当前机器的名字。为得到已知格式名字列表,键入命令 objdump –i |
|
-u |
同选项--undefined-only |
|
--undefined-only |
只显示文件引用但未定义的符号 |
|
-V |
同选项 --version |
|
--version |
显示版本信息,然后退出 |
1.3.15 objcopy
将目标文件的一部分或者全部内容拷贝到另外一个目标文件中,或者实现目标文件的格式转换。
objcopy 工具使用 BFD 库读写目标文件,它可以将一个目标文件的内容拷贝到另外一个目标文件当中。objcopy 通过它的选项来控制其不同的动作,它可以将目标文件拷贝成和原来的文件不一样的格式。需要注意的是 objcopy 能够在两种格式之间拷贝一个完全链接的文件,在两种格式之间拷贝一个可重定位的目标文件可能不会正常地工作。
objcopy 在做转换的时候会创建临时文件,然后将这些临时文件删除。objcopy 使用 BFD 来做它所有的转换工作;它访问BFD中描述的所有格式,可以不必指定就识别大多数的格式。
通过指定输出目标为 srec(例如 -O srec),objcopy 可以用来生成 S-record 文件。
通过指定输入目标为而进制文件(例如 -O binary),objcopy 可以生成原始格式的二进制文件。当 objcopy 生成一个原始格式的二进制文件的时候,它会生成输入的目标文件的基本内存拷贝,然后所有的标号和可重定位信息都会被去掉。内存拷贝开始于最低段的加载地址,拷贝到输出文件。
当生成一个 S-record 或者原始的二进制文件的时候,可以使用-S这个很有用的选项选项来移除一些包含调试信息的节。有时 -R 可以用来移除一些二进制文件不需要的节。
objcopy [选项]... 输入文件 [输出文件]
|
选项 |
描述 |
|
input-file outfile |
参数 input-file 和 outfile 分别表示输入目标文件(源目标文件)和输出目标文件(目的目标文件)。如果在命令行中没有明确地指定 outfile,那么 Objcopy 将创建一个临时文件来存放目标结果,然后使用 input-file 的名字来重命名这个临时文件(这时候,原来的 input-file 将被覆盖)。 |
|
-I bfdname |
--input-target=bfdname 明确告诉 Objcopy ,源文件的格式是什么,bfdname 是 BFD 库中描述的标准格式名。这样做要比让 Objcopy 自己去分析源文件的格式,然后去和 BFD 中描述的各种格式比较,通过而得知源文件的目标格式名的方法要高效得多。 |
|
-O bfdname |
--output-target= bfdname 使用指定的格式来写输出文件(即目标文件),bfdname 是 BFD 库中描述的标准格式名。 |
|
-F bfdname |
--target= bfdname 明确告诉 Objcopy ,源文件的格式是什么,同时也使用这个格式来写输出文件(即目标文件),也就是说将源目标文件中的内容拷贝到目的目标文件的过程中,只进行拷贝不做格式转换,源目标文件是什么格式,目的目标文件就是什么格式。 |
|
-R sectionname |
--remove-section= sectionname 从输出文件中删掉所有名为 sectionname 的段。这个选项可以多次使用。注意:不恰当地使用这个选项可能会导致输出文件不可用。 |
|
-S |
--strip-all (strip 剥去、剥)不从源文件中拷贝重定位信息和符号信息到输出文件(目的文件)中去。 |
|
-g |
--strip-debug 不从源文件中拷贝调试符号到输出文件(目的文件)中去。 |
|
--strip-undeeded |
剥去所有在重定位处理时所不需要的符号。 |
|
-K symbolname |
--keep-symbol= symbolname 仅从源文件中拷贝名为 symbolname 的符号。这个选项可以多次使用。 |
|
-N symbolname |
--strip-symbol= symbolname 不从源文件中拷贝名为 symbolname 的符号。这个选项可以多次使用。它可以和其他的 strip 选项联合起来使用(除了 -K symbolname | --keep-symbol= symbolname 外)。 |
|
-L symbolname |
--localize-symbol= symbolname 使名为 symbolname 的符号在文件内局部化,以便该符号在该文件外部是不可见的。这个选项可以多次使用。 |
|
-W symbolname |
-weaken-symbol= symbolname 弱化名为 symbolname 的符号。这个选项可以多次使用。 |
|
-x |
--discard-all (discard 丢弃、抛弃) 不从源文件中拷贝非全局符号。 |
|
-X |
--discard-locals 不从源文件中拷贝又编译器生成的局部符号(这些符号通常是L或 . 开头的)。 |
|
-b byte |
--byte= byte 如果 --interleave 使能,则开始保持字节在一个范围内。字节范围为 0 到 字节总长 -1,字节总长由 --interleave 选项设定 |
|
-i interleave |
--interleave= interleave (interleave 隔行、交叉) 只复制每个宽度字节的范围 |
|
-p |
--preserve-dates (preserve 保存、保持) 设置输出文件的访问和修改日期和输入文件相同。 |
|
--debugging |
如果可能的话,转换调试信息。因为只有特定的调试格式被支持,以及这个转换过程要耗费一定的时间,所以这个选项不是默认的。 |
|
--gap-fill= val |
使用内容 val 填充段与段之间的空隙。通过增加段的大小,在地址较低的一段附加空间中填充内容 val 来完成这一选项的功能。 |
|
--pad-to= address |
填充输出文件到虚拟地址 address。通过增加输出文件中最后一个段的大小,在输出文件中最后一段的末尾和 address 之间的这段附加空间中,用 --gap-fill= val 选项中指定的内容 val 来填充(默认内容是0,即没有使用 --gap-fill= val 选项的情况下)。 |
|
--set-start= val |
设置新文件(应该是输出文件吧?)的起始地址为 val。不是所有的目标文件格式都支持设置起始地址。 |
|
--change-start = incr --adjust-start= incr |
通过增加值 incr 来改变起始地址。不是所有的目标文件格式都支持设置起始地址。 |
|
--change-addresses incr --adjust-vma incr |
通过加上一个值incr,改变所有段的 VMA(Virtual Memory Address 运行时地址)和 LMA(Load Memory Address 装载地址),以及起始地址。某些目标文件格式不允许随便更改段的地址。 |
|
--change-section-address section{= + -} val --adjust-section-vma section{= + -} val |
设置或者改变名为 section 的段的 VMA(Virtual Memory Address 运行时地址)和 LMA(Load Memory Address 装载地址)。如果这个选项中使用的是 "=",那么名为 section 的段的 VMA(Virtual Memory Address 运行时地址)和 LMA(Load Memory Address 装载地址)将被设置成 val;如果这个选项中使用的是 "-" 或者 "+" ,那么上述两个地址将被设置或者改变成这两个地址的当前值减去或加上 val 后的值。如果在输入文件中名为 section 的段不存在,那么 Objcopy 将发出一个警告,除非 --no-change-warnings 选项被使用。 这里的段地址设置和改变都是输出文件中的段相对于输入文件中的段而言的。例如: (1)--change-section-address .text = 10000 这里是指将输入文件(即源文件)中名为 .text 的段拷贝到输出文件中后,输出文件中的 .text 段的 VMA(Virtual Memory Address 运行时地址)和 LMA(Load Memory Address 装载地址)将都被设置成 10000。 (2)--change-section-address .text + 100 这里是指将输入文件(即源文件)中名为 .text 的段拷贝到输出文件中后,输出文件中的 .text 段的 VMA(Virtual Memory Address 运行时地址)和 LMA(Load Memory Address 装载地址)将都被设置成以前输入文件中 .text 段的地址(当前地址)加上 100 后的值。 |
|
--change-section-lma section{= + -} val |
仅设置或者改变名为 section 的段的 LMA(Load Memory Address 装载地址)。一个段的 LMA 是程序被加载时,该段将被加载到的一段内存空间的首地址。通常 LMA 和 VMA(Virtual Memory Address 运行时地址)是相同的,但是在某些系统中,特别是在那些程序放在 ROM 的系统中,LMA 和 VMA 是不相同的。如果这个选项中使用的是 "=",那么名为 section 的段的 LMA(Load Memory Address装载地址)将被设置成 val;如果这个选项中使用的是 "-" 或者 "+",那么LMA将被设置或者改变成这两个地址的当前值减去或加上 val 后的值。如果在输入文件中名为 section 的段不存在,那么 Objcopy 将发出一个警告,除非 --no-change-warnings 选项被使用。 |
|
--change-section-vma section{= + -} val |
仅设置或者改变名为 section 的段的 VMA(Load Memory Address 装载地址)。一个段的 VMA 是程序运行时,该段的定位地址。 通常 VMA 和 LMA(Virtual Memory Address 运行时地址)是相同的,但是在某些系统中,特别是在那些程序放在ROM的系统中,LMA 和 VMA 是不相同的。如果这个选项中使用的是 "=",那么名为 section 的段的 LMA(Load Memory Address 装载地址)将被设置成 val;如果这个选项中使用的是 "-" 或者 "+",那么 LMA 将被设置或者改变成这两个地址的当前值减去或加上 val 后的值。 如果在输入文件中名为 section 的段不存在,那么 Objcopy 将发出一个警告,除非 --no-change-warnings 选项被使用。 |
|
--change-warnings --adjust-warnings |
如果命令行中使用了 --change-section-address section{= + -} val 或者 --adjust-section-vma section{= + -} val ,又或者 --change-section-lma section{= + -} val ,又或者 --change-section-vma section{= + -} val ,并且输入文件中名为 section 的段不存在,则 Objcopy 发出警告。这是默认的选项。 |
|
--no-chagne-warnings --no-adjust-warnings |
如果命令行中使用了 --change-section-address section{= + -} val 或者 --adjust-section-vma section{= + -} val ,又或者 --change-section-lma section{= + -} val ,又或者 --change-section-vma section{= + -} val ,即使输入文件中名为 section 的段不存在, Objcopy 也不会发出警告。 |
|
--set-section-flags section=flags |
为 section 的段设置一个标识。这个 flags 变量的可以取逗号分隔的多个标识名字符串(这些标识名字符串是能够被 Objcopy 程序所识别的),合法的标识名有 alloc,load,readonly,code,data 和 rom。 |
|
--add-section sectionname=filename |
进行目标文件拷贝的过程中,在输出文件中增加一个名为 sectionname 的新段。这个新增加的段的内容从文件 filename 得到。这个新增加的段的大小就是这个文件 filename 的大小。只要输出文件的格式允许该文件的段可以有任意的段名(段名不是标准的,固定的),这个选项才能使用。 |
1.3.16 objdump
objdump 命令是用查看目标文件或者可执行的目标文件的构成的 gcc 工具。最常见得用法就是对目标文件进行反汇编,进行代码追踪。
选项如下:
|
选项 |
详细选项 |
描述 |
|
-a |
--archive-headers |
显示档案库的成员信息,类似 ls -l 将 lib*.a 的信息列出。 |
|
-b bfdname |
--target=bfdname |
指定目标码格式。这不是必须的,objdump 能自动识别许多格式,比如: objdump -b oasys -m vax -h fu.o 显示 fu.o 的头部摘要信息,明确指出该文件是 Vax 系统下用 Oasys 编译器生成的目标文件。objdump -i 将给出这里可以指定的目标码格式列表。 |
|
-C |
--demangle |
将底层的符号名解码成用户级名字,除了去掉所开头的下划线之外,还使得C++函数名以可理解的方式显示出来。 |
|
-g |
--debugging |
显示调试信息。企图解析保存在文件中的调试信息并以 C 语言的语法显示出来。仅仅支持某些类型的调试信息。有些其他的格式被 readelf -w 支持。 |
|
-e |
--debugging-tags |
类似 -g 选项,但是生成的信息是和 ctags 工具相兼容的格式。 |
|
-d |
--disassemble |
从 objfile 中反汇编那些特定指令机器码的 section。 |
|
-D |
--disassemble-all |
与 -d 类似,但反汇编所有 section. |
|
--prefix-addresses |
反汇编的时候,显示每一行的完整地址。这是一种比较老的反汇编格式。 |
|
|
-EB |
||
|
-EL |
--endian={big|little} |
指定目标文件的小端。这个项将影响反汇编出来的指令。在反汇编的文件没描述小端信息的时候用。例如 S-records. |
|
-f |
--file-headers |
显示 objfile 中每个文件的整体头部摘要信息。 |
|
-h |
--section-headers --headers |
显示目标文件各个section的头部摘要信息。 |
|
-H |
--help |
简短的帮助信息。 |
|
-i |
--info |
显示对于 -b 或者 -m 选项可用的架构和目标格式列表。 |
|
-j name |
--section=name |
仅仅显示指定名称为 name 的 section 的信息 |
|
-l |
--line-numbers |
用文件名和行号标注相应的目标代码,仅仅和 -d、-D 或者 -r 一起使用使用 -ld 和使用 -d 的区别不是很大,在源码级调试的时候有用,要求编译时使用了 -g 之类的调试编译选项。 |
|
-m machine |
--architecture=machine |
指定反汇编目标文件时使用的架构,当待反汇编文件本身没描述架构信息的时候(比如 S-records),这个选项很有用。可以用 -i 选项列出这里能够指定的架构. |
|
-r |
--reloc |
显示文件的重定位入口。如果和 -d 或者 -D 一起使用,重定位部分以反汇编后的格式显示出来。 |
|
-R |
--dynamic-reloc |
显示文件的动态重定位入口,仅仅对于动态目标文件意义,比如某些共享库。 |
|
-s |
--full-contents |
显示指定 section 的完整内容。默认所有的非空 section 都会被显示。 |
|
-S |
--source |
尽可能反汇编出源代码,尤其当编译的时候指定了 -g 这种调试参数时,效果比较明显。隐含了 -d 参数。 |
|
--show-raw-insn |
反汇编的时候,显示每条汇编指令对应的机器码,如不指定 --prefix-addresses,这将是缺省选项。 |
|
|
--no-show-raw-insn |
反汇编时,不显示汇编指令的机器码,如不指定 --prefix-addresses,这将是缺省选项。 |
|
|
--start-address=address |
从指定地址开始显示数据,该选项影响 -d、-r 和 -s 选项的输出。 |
|
|
--stop-address=address |
显示数据直到指定地址为止,该项影响 -d、-r 和 -s 选项的输出。 |
|
|
-t |
--syms |
显示文件的符号表入口。类似于 nm -s 提供的信息 |
|
-T |
--dynamic-syms |
显示文件的动态符号表入口,仅仅对动态目标文件意义,比如某些共享库。它显示的信息类似于 nm -D | --dynamic 显示的信息。 |
|
-V |
--version |
版本信息 |
|
--all-headers |
-x |
显示所可用的头信息,包括符号表、重定位入口。-x 等价于 -a -f -h -r -t 同时指定。 |
|
-z |
--disassemble-zeroes |
一般反汇编输出将省略大块的零,该选项使得这些零块也被反汇编。 |
|
@file |
可以将选项集中到一个文件中,然后使用这个 @file 选项载入 |
1.3.17 ranlib:更新静态库
静态库文件需要使用 " ar " 来创建和维护。当给静态库增建一个成员时(加入一个 .o 文件到静态库中)," ar " 可直接将需要增加的 .o 文件简单的追加到静态库的末尾。
之后当我们使用这个库进行链接生成可执行文件时,链接程序 " ld " 可能提示错误,这可能是:主程序使用了之前加入到库中的 .o 文件中定义的一个函数或者全局变量,但连接程序无法找到这个函数或者变量。
这个问题的原因是:之前我们将编译完成的 .o 文件直接加入到了库的末尾,却并没有更新库的有效符号表。连接程序进行连接时,在静态库的符号索引表中无法定位刚才加入的 .o 文件中定义的函数或者变量。这就需要在完成库成员追加以后让加入的所有 .o 文件中定义的函数(变量)有效,完成这个工作需要使用另外一个工具 " ranlib " 来对静态库的符号索引表进行更新。
我们所使用到的静态库(文档文件)中,存在这样一个特殊的成员,它的名字是 " __.SYMDEF " 。它包含了静态库中所有成员所定义的有效符号(函数名、变量名)。因此,当为库增加了一个成员时,相应的就需要更新成员 " __.SYMDEF " ,否则所增加的成员中定义的所有的符号将无法被连接程序定位。
完成更新的命令是:ranlib ARCHIVEFILE
通常在 Makefile 中我们可以这样来实现。
libfoo.a: libfoo.a(x.o) libfoo.a(y.o) ...
ranlib libfoo.a
它所实现的是在更新静态库成员" x.o "和" y.o "之后,对静态库的成员" __.SYMDEF "进行更新(更新库的符号索引表)。
如果我们使用 GNU ar 工具来维护、管理静态库,我们就不需要考虑这一步。 GNU ar 本身已经提供了在更新库的同时更新符号索引表的功能(这是默认行为,也可以通过命令行选项控制 ar 的具体行为。可参考 GNU ar 工具的 man 手册)。

