
剖析可执行文件ELF组成
对比参考:剖析.o文件ELF组成

相比.o的ELF格式,有哪些变化?
.rel.text和.rel.data消失了
为什么这两个节会消失?
链接器将各.o中同名的.text和.data节整合到一起时,会对整合后的.text和.data进行重定位。其实重定位时主要针对就是.text和.data节,不过这.text和.data节重定位时需要依赖.rel.text和.rel.data中的信息,一旦重定位结束后,这两个节的使命就完成了,自然也就会消失。
多出了两个节
init节
作用
这个节会提供_init等函数,专门用于实现程序的一些初始化。程序入口为_start,从_start开始执行后,在正式调用main函数之前,会先调用_init等函数进行程序的初始化(比如建立函数栈等等)。
init节怎么来的
回顾gcc链接的过程,
-dynamic-linker /lib64/ld-linux-x86-64.so.2 //动态链接器
-lc //libc,常用c函数库——c标准库的子库
crtend.o crtn.o //扫尾代码
“可执行目标文件”的各个节归类
程序最终运行时,需要搬到内存上的节有:ELF/.init/.text/.rodata/.data/.bss。搬到内存上什么位置呢?搬到重定位的“运行地址”所指定的位置。
ELF/.init/.text/.rodata:只读的存储段(代码段)
.data/.bss:可读可写存储段(静态数据段)。之所以称为静态数据段,是因为.data/.bss的空间规划,是在编译时就进行了理论安排,并不是程序运行起来才安排的,所以被称为静态数据段。
程序的加载、运行
编译得到可执行目标文件后,就可以将“可执行目标文件”加载“运行地址”所指的内存位置,然后运行了。不过这里还是要分两种情况来看,第一种是裸机运行的情况,第二种是基于OS虚拟内存运行的情况。
裸机的情况
使用专门针对裸机的编译器来编译程序,最后得到的就是可以在裸机上运行的可执行程序。加载裸机程序时,由专门的加载程序(加载软件)来实现的。
加载
其实加载的过程就是将“代码段”和“数据段”复制到内存上。裸机时,链接器重定位后的“运行地址”是真实的物理地址,加载时直接将“代码段”和“数据段”复制到物理内存中“运行地址”所指定的位置。裸机运行地址是多少,可以由我们程序员自己来定。裸机时就不是ELF格式头了,而是bin格式头。
运行
①CPU的PC(程序计数器)存放第一条指令_start的地址,也就是将PC指向第一条指令_start。pc是cpu的寄存器之一。
②从_start开始执行启动代码。
③启动代码调用_init等函数进行初始化。初始化有一件非常重要的事情就是,从内存划出一片空间出来用作堆和栈,因为空间是以堆和栈的方式来管理的,因此就称为堆 和 栈。
④启动代码调用main函数,main函数再调用各个子函数,我们自己写的代码就开始运行了。
⑤main函数调用return关键字,返回到启动代码。
对于裸机的来说,返回到启动代码就结束了。至于return的返回值,有没有返回值,对于裸机来说都没有什么影响。就算有返回值,将返回值返回给启动代码后,这个返回值对启动代码来说也没有什么意义。所以说,对于裸机来说,其实main函数的返回值没有什么意义,所以大家在学习单片机时候,以前的main函数的返回值都是void的。


void main(void) { return; }
不过现在都规范化了,单片机等裸机里面,也要求main函数的返回值类型为int型。
int main(void) { return 0; }
尽管在这里要求返回int型的返回值,但是我们自己应该清楚,在裸机下,main函数的返回值并没有什么大的意义。
栈、堆
程序运行起来后,初始化代码会从内存中划出一片空间,用来作为程序运行所需要的栈和堆。
栈(stack)
栈的意思是,表示内存空间以栈这种数据结构来进行管理,所谓管理就是管理空间的开辟和释放。栈的特点是,只能在栈顶进行操作,不能够在栈的中间和栈底操作。
栈是向下生长的
所谓向下生长就是,栈底在最高地址处,当栈中没有任何空间被使用时,栈顶指针就指向栈底,每当栈顶被占用一个字节的空间,栈顶指针就向低地址方向移动一个字节。从高地址向低地址方向移动,就是向下生长,栈顶指针所指的那个字节是没被用的。栈顶和栈底之间的栈空间,就是被占用的空间。反过来,栈顶指针向高地址后退一个字节,就表示释放一个字节的空间。释放的意思就是将空间交出去,让别人可以使用。
怎么理解栈顶指针?
就是某个寄存器或者指针变量,专门用于存放栈顶字节的地址。
栈的作用
函数自动局部变量、形参等就开辟于栈。
int fun(int a) { int b; ... }
不过这里有一点需要强调下,对于ARM来说,由于arm cpu内部寄存器比较多,所以如果形参在4个以内的,实际上形参是在寄存器中,而并不在栈中。如果超过4个的话,第4个往后的形参才会存在栈中。不过在intel的CPU上又不一样,因为Intel cpu的寄存器比较紧俏,所以形参基本都是存在栈中的。为了方便记忆我们一律认为形参都是在栈中的。从栈中开辟和释放自动局部变量、形参空间的过程,由函数被调用时,在运行的过程中自动完成的,无需程序员关心,开辟空间和释放空间的本质,其实就是栈顶指针移动的过程。
堆(heap)
堆空间和栈空间的管理方式是有区别的。
栈的话只能在栈顶才能进行操作,但是堆不是,堆的话可以在中间任何位置操作。堆的空间是向上生长的,也就是说在堆中开辟空间时与栈相反,是从低地址往高地址方向延伸的。
栈的空间是自动开辟和释放的,但是堆的空间不是的,堆只能手动开辟和释放。
从堆里面开辟空间
程序需要调用malloc函数来手动开辟。所谓手动开辟,就是程序员需要在程序中亲自调用某个函数来实现,至于说在堆中什么位置开辟空间,这个由malloc函数的算法来决定。
释放在堆中开辟的空间:
在程序中调用free函数,手动释放。释放的意思,也是将空间让出来,让别人可以使用。
基于OS虚拟内存的情况
基于OS运行程序时,常见有两种方式
①在图形界面,双击快捷图标实现
②在命令行,执行./a.out命令实现
每一个进程都是运行在自己的独立虚拟内存中的,命令行和图形界面本身也是一个程序(进程),所以也是运行在自己独立的虚拟内存上的。
程序的加载
当我们双击程序,或者执行./a.out命令时,就开始了程序的加载操作,具体步骤如下:
①首先从父进程复制出一个子进程
图形界面、命令行程序就是父进程,执行程序时会从父进程复制出子进程,复制的目的其实就是从父进程的“虚拟内存”复制出一个子进程的“虚拟内存”,准确讲应该是复制出“虚拟内存”的相关数据结构,用于建立子进程的虚拟内存。有了子进程的虚拟内存,就可以将新的程序加载到虚拟内存中了。虚拟内存空间被分为了两部分,一部分是内核空间,另一个部分是应用空间,应用程序的应该加载到应用空间。在Linux下复制子进程时需要调用Linux OS所提供的fork函数。至于虚拟内存与真实物理内存之间的对应关系,这个事情就留给“虚拟内存机制”来操心。
②调用加载器
将自己程序(新程序)的“代码段”和“数据段”加载到子进程虚拟内存的应用空间中。
基于Linux运行的话,gcc链接时重定位的运行地址是从0x08048000或者0x0000000000400000开始的,所以程序会被加载到虚拟内存中0x08048000或者0x0000000000400000地址往后的空间中。至于虚拟内存0~0x08048000或者0~0x0000000000400000之间的虚拟空间,则未被使用。基于Linux OS运行时,加载器是由Linux OS提供的,任何一个程序都可以通过execve这个系统API来调用加载器,为了方便称呼,我们就直接将“execve函数”称为加载器。
运行
①cpu的pc指向_start(将第一条指令_start所在位置的虚拟地址存放到pc)
②从_start开始执行启动代码。
③启动代码调用_init等函数进行初始化。
其中很重要的就是弄出堆和栈这两个东西,这一点与前面裸机的情况时类似的,这里不再赘述。不过与裸机不同的是,在栈和堆之间,还有一个“共享映射区”。
④启动代码调用main函数,main函数再调用子函数,我们自己写的代码就开始运行了。
⑤main函数调用return关键字,返回到启动代码。
有OS时,main函数将返回值return给启动代码后,启动代码会调用exit函数,接着将返回值返回给OS。在裸机情况下,启动代码不存在调用exit函数这一说,只有基于OS时才存在这种情况。
对比裸机运行和基于os虚拟内存运行时,程序的内存结构(内存布局)
内存结构,其实就是程序运行时在内存中存储结构。不管是裸机还是基于OS虚拟内存运行的情况,内存布局基本都差不多,下面讲解虚拟内存的程序内存布局。
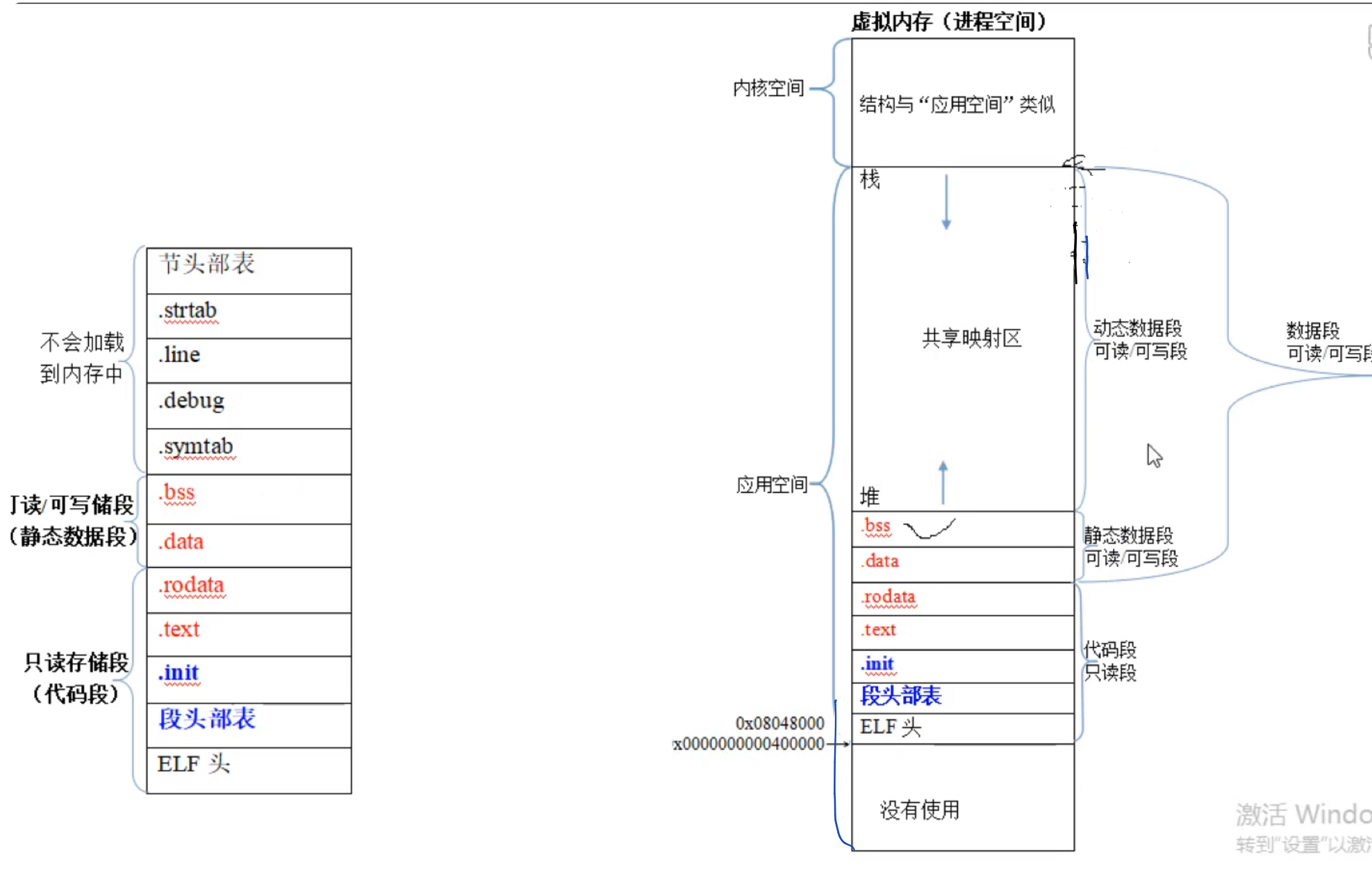
程序在内存中存储时,就存储两个东西,一是指令,二是数据。
指令存储在代码段中的.init和.text节中。.init节:放启动代码相关的指令 .text:主要放我们自己所写程序的指令

 浙公网安备 33010602011771号
浙公网安备 33010602011771号