
自己读入数据的方法:(input)https://blog.csdn.net/weixin_50853979/article/details/124978009
https://www.jianshu.com/p/f757eb7ec7a2 (sys.stdin.readline()用法)
python map 函数的使用!!!(和lambda函数一起效果更好!!!)https://www.runoob.com/python/python-func-map.html
区间问题的补充: https://www.nowcoder.com/questionTerminal/4edf6e6d01554870a12f218c94e8a299 (同一时间重叠最多)
1.sorted() 和sort()的用法辨析注意 Python sorted() 函数 | 菜鸟教程 (runoob.com)
3. reversed()内置函数的用法http://c.biancheng.net/view/2238.html
2. 设计sort特定的函数 lamda的用法
intervals = [[1,3],[2,6],[8,10],[15,18]]
intervals.sort(key=lambda x: x[0]) //根据x[0]进行排序
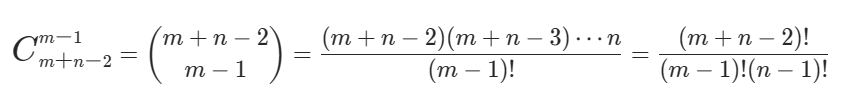
import math
ans = comb(m + n - 2, n - 1)
4.[算法总结] 十大排序算法 - 知乎 (zhihu.com)
5. x//2 整除(取整)
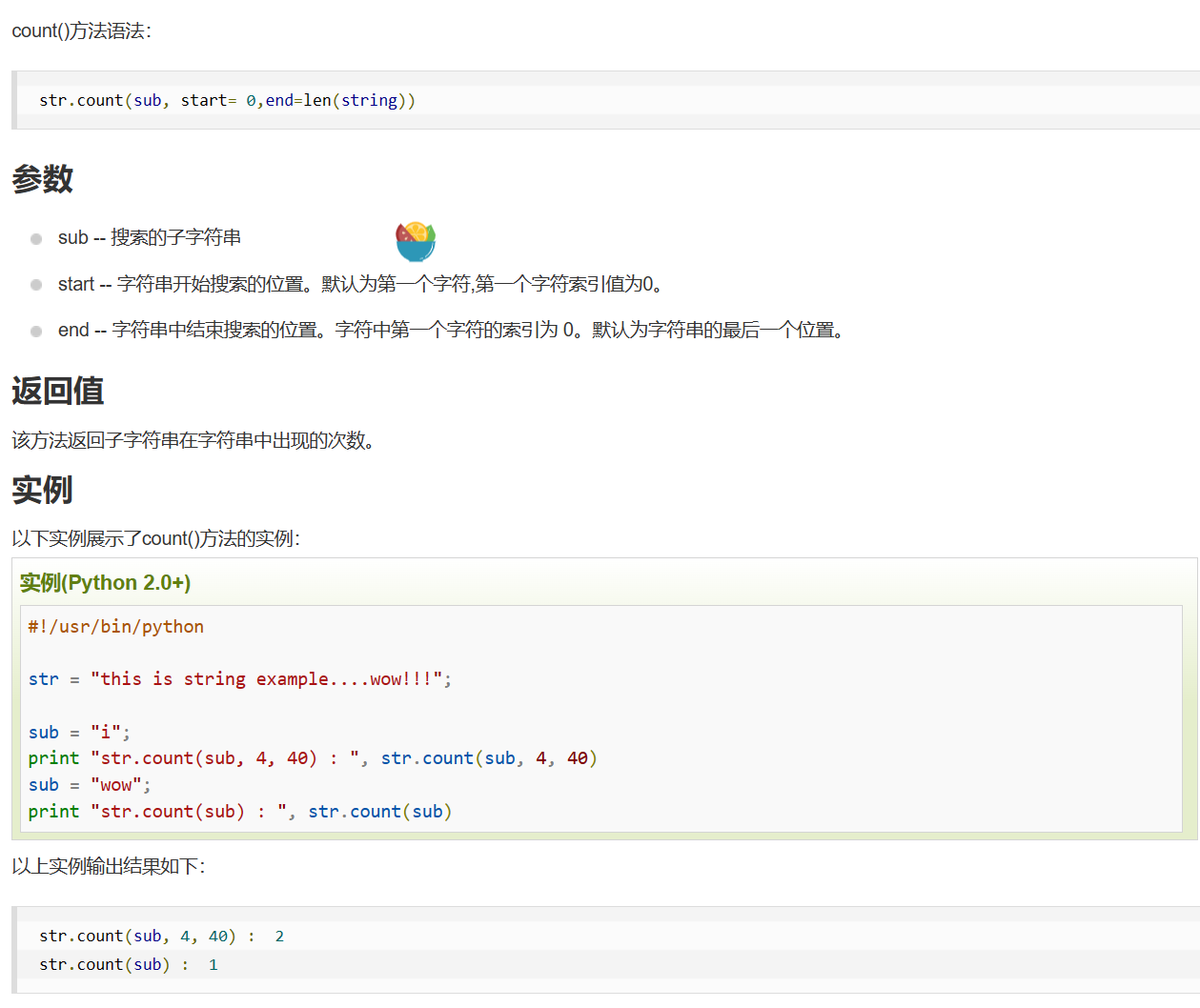
6. count 用法
7. collections.Counter()用法
主要功能:可以支持方便、快速的计数,将元素数量统计,然后计数并返回一个字典,键为元素,值为元素个数。
from collections import Counter list1 = ["a", "a", "a", "b", "c", "c", "f", "g", "g", "g", "f"] dic = Counter(list1) print(dic) #结果:次数是从高到低的 #Counter({'a': 3, 'g': 3, 'c': 2, 'f': 2, 'b': 1}) print(dict(dic)) #结果:按字母顺序排序的 #{'a': 3, 'b': 1, 'c': 2, 'f': 2, 'g': 3} print(dic.items()) #dic.items()获取字典的key和value #结果:按字母顺序排序的 #dict_items([('a', 3), ('b', 1), ('c', 2), ('f', 2), ('g', 3)]) print(dic.keys()) #结果: #dict_keys(['a', 'b', 'c', 'f', 'g']) print(dic.values()) #结果: #dict_values([3, 1, 2, 2, 3]) print(sorted(dic.items(), key=lambda s: (-s[1]))) #结果:按统计次数降序排序 #[('a', 3), ('g', 3), ('c', 2), ('f', 2), ('b', 1)] for i, v in dic.items(): if v == 1: print(i) #结果: #b
8. Python 按键(key)或值(value)对字典进行排序 | 菜鸟教程 (runoob.com)
9. (59条消息) Python反转列表的三种方式_bookaswine的博客-CSDN博客_列表反转的三种方法
10. 将字符转换成unicode编码数字 ord()函数的使用:Python ord() 函数 | 菜鸟教程 (runoob.com)
11. heapq 小顶堆的实现 (59条消息) Python heapq库的用法介绍_小斌哥ge的博客-CSDN博客_python heapq
(大顶堆:把在数据进堆的时候把所有数据都去相反数就可以啦)
12. 图算法:
Floyd算法详解 通俗易懂 - 知乎 (zhihu.com) 【不能有负权环】
深入理解 Dijkstra 算法实现原理 - 简书 (jianshu.com)【不能有负权边】
(61条消息) 图解弗洛伊德算法(每一对顶点之间的最短路径问题)_弗洛伊德算法过程图解_RonzL的博客-CSDN博客
弗洛伊德算法:不能处理含有负全环的图
Dijkstra算法:不能处理有负权边的图,即要求所有边都是正数!
Bellman-Ford算法:可以处理负全环的图,检测有没有负全环 :
Bellman-Ford算法 - 知乎 (zhihu.com)
(61条消息) Bellman-Ford算法(最短路径,解决负权边,检测负环回路)+队列优化_Knock man的博客-CSDN博客
eval()函数 :实现数据str变任何类型 自动识别list和dict等数据类型
13 回溯算法常用记忆搜索法@cache 和
from functools import lru_cache @lru_cache(None)
python内置缓存lru_cache - 知乎 (zhihu.com) 注意:Python 缓存函数提升性能—functools.cache - 知乎 (zhihu.com) 【由于使用了字典存储缓存,所以该函数的固定参数和关键字参数必须是可哈希的,也就是说不能传递list等在这个递归函数里面】

算法学习笔记(1) : 并查集 - 知乎 (zhihu.com)
背包问题力扣全集:https://leetcode.cn/problems/target-sum/solution/by-flix-rkb5/
完全背包+有序排列:https://leetcode.cn/problems/combination-sum-iv/
经典动态规划问题:高楼扔鸡蛋 - 知乎 (zhihu.com)
字符串逆转
''.join(list(reversed(s[i:j+1])))
---nolocal 变量的定义和说明

global nonlocal 和函数声明的顺序问题:
p=1 # global 的使用说明
def aaa():
global p # global 的使用说明
print("aaaaaaaaa")
print(p)
p=10
print(p)
# bbb() #(bbb要想使用需要放在aaa函数声明的前面)
aaa()
def bbb():
tmp=[10]
def ccc():
nonlocal tmp # 不需要nonlocal的使用(可以使用 可以不使用)
print(tmp)
ccc()
bbb()
负数的整除和取余操作需要注意:
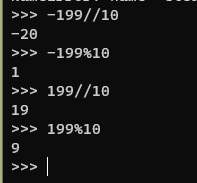 Python3 的整数除法在 x 为负数时会向下(更小的负数)取
Python3 的整数除法在 x 为负数时会向下(更小的负数)取
整(正数的时候就相当于直接切割;负数的取余 -=10 相当于去掉负号的正数的取余的结果!!!)
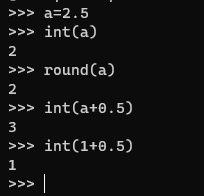
取整运算:(int 和round 都不能实现四舍五入 可以通过+0.5的操作来实现四舍五入的取整)
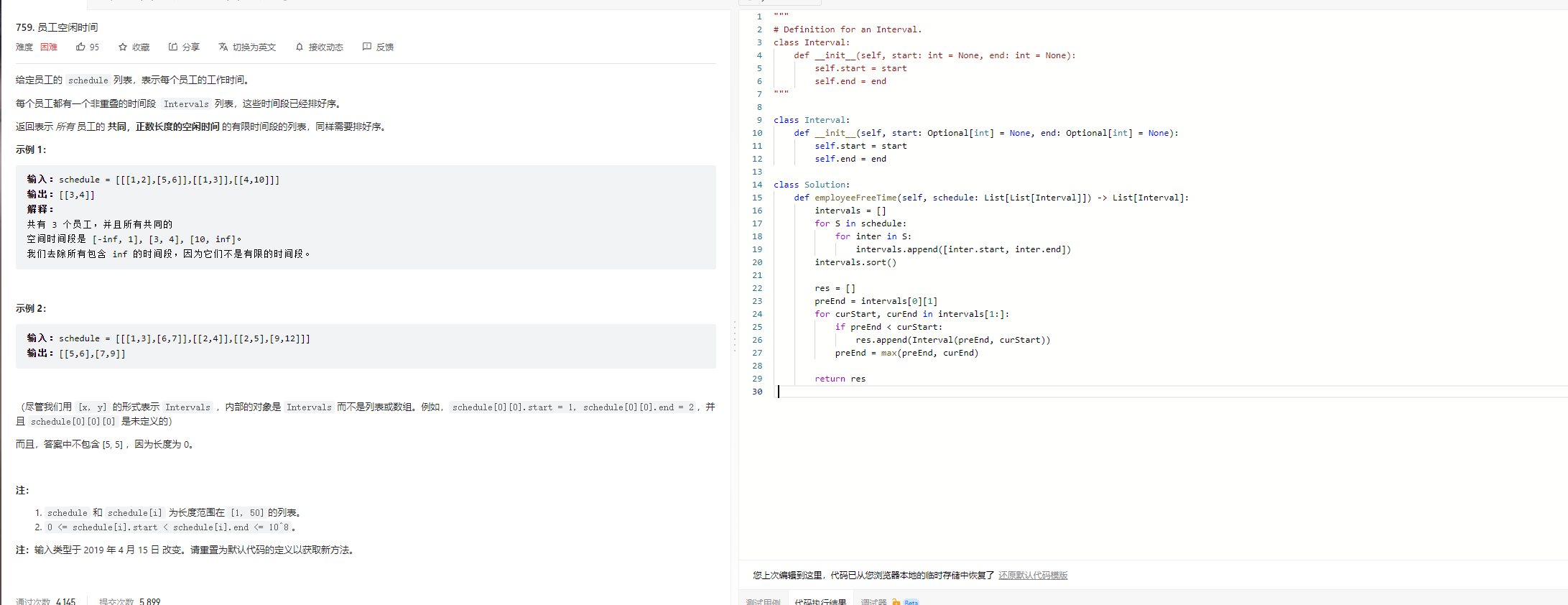
区间计算问题:
并查集的使用
class UnionFind: def __init__(self, n): self.n = n self.part = n self.parent = [x for x in range(n)] self.size = [1 for _ in range(n)] def Find(self, x: int) -> int: if self.parent[x] == x: return x return self.Find(self.parent[x]) def Union(self, x: int, y: int) -> bool: root_x = self.Find(x) root_y = self.Find(y) if root_x == root_y: return False if self.size[root_x] > self.size[root_y]: root_x, root_y = root_y, root_x self.parent[root_x] = root_y self.size[root_y] += self.size[root_x] self.part -= 1 def connected(self, x: int, y: int) -> bool: return self.Find(x) == self.Find(y) def get_part_size(self, x: int) -> int: root_x = self.Find(x) return self.size[root_x] class Solution: def validTree(self, n: int, edges: List[List[int]]) -> bool: UF = UnionFind(n) for x, y in edges: if UF.Union(x, y) == False: #失败了,说明已经在一个连通域中了。再连接就是环了 return False return UF.part == 1
