
代码地址:csiro-mlai/decision-tree-mpc (github.com) (先运行他给的adult示例代码)【ubuntu 运行环境】
修改成自己的数据集然后进行运行:
按照dockerfile 文件进行配置环境
进入文件夹decision-tree-mpc/:
- 修改 download.sh 将数据集换成自己的数据集 并运行./download.sh (这一步将会把数据集下载到decision-tree-mpc/文件夹下面)【对应的需要修改prepare.py文件,详见下】

-
安装MP-SPDZ文件 :从这个地方下载 zip文件:Releases · data61/MP-SPDZ (github.com)
-

cd MP-SPDZ 然后执行
Scripts/tldr.sh (生成所需要的.x文件)
-
cd MP-SPDZ; make boost mpir
- cd .. 然后 ./build-mp-spdz.sh (这里如果git出错 参考(57条消息) Git Clone错误解决:GnuTLS recv error (-110): The TLS connection was non-properly terminated._欧晨eli的博客-CSDN博客_gnutls recv error)多尝试几次就好了....
-
./convert.sh
-
./run-local.sh emul 2 2 运行即可
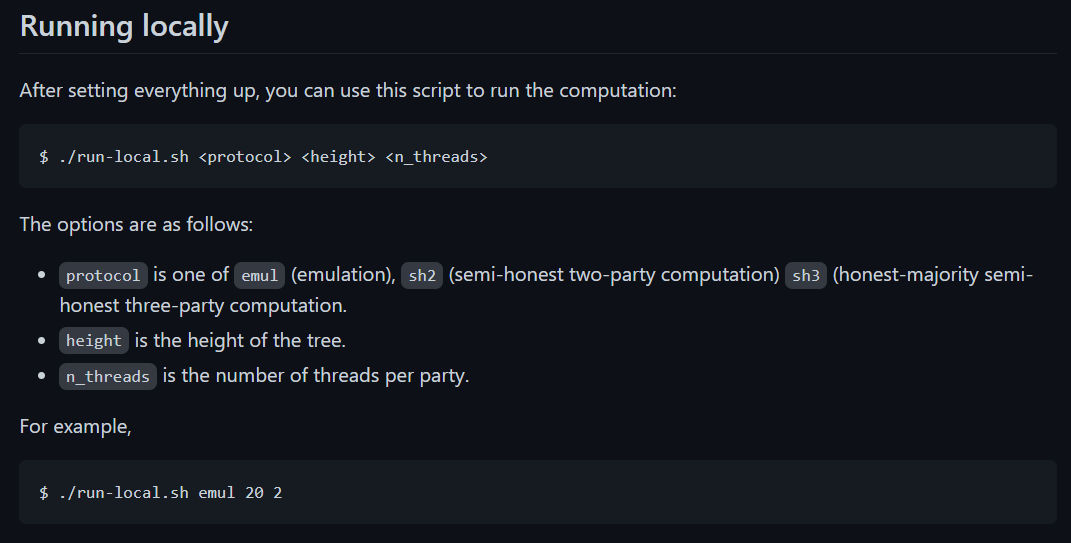
预测结果的表示:(计算正确率)
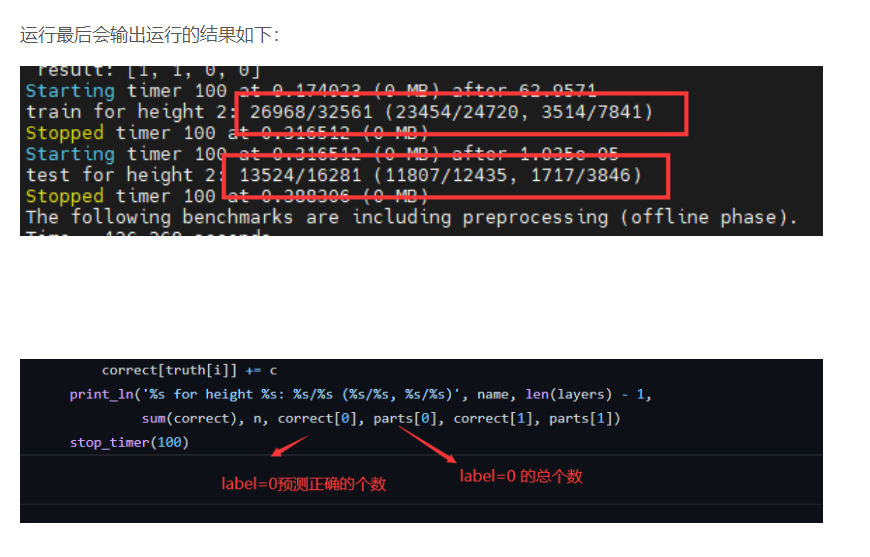
prepare.py文件对应的是对下载到decision-tree-mpc/文件夹下面 数据的处理方式(此处要求:先读入所有的label(只能是0/1),然后读入属性,相当于一列一列的读取所有的数据 行:样本个数 列:属性+label)【以下代码是对adult数据处理的方式的解读】
adult数据集如下:
0,1,2,3,4,5,6,7,8,9,10,11,12,13,14
39, State-gov, 77516, Bachelors, 13, Never-married, Adm-clerical, Not-in-family, White, Male, 2174, 0, 40, United-States, <=50K 50, Self-emp-not-inc, 83311, Bachelors, 13, Married-civ-spouse, Exec-managerial, Husband, White, Male, 0, 0, 13, United-States, <=50K 38, Private, 215646, HS-grad, 9, Divorced, Handlers-cleaners, Not-in-family, White, Male, 0, 0, 40, United-States, <=50K 53, Private, 234721, 11th, 7, Married-civ-spouse, Handlers-cleaners, Husband, Black, Male, 0, 0, 40, United-States, <=50K 28, Private, 338409, Bachelors, 13, Married-civ-spouse, Prof-specialty, Wife, Black, Female, 0, 0, 40, Cuba, <=50K 37, Private, 284582, Masters, 14, Married-civ-spouse, Exec-managerial, Wife, White, Female, 0, 0, 40, United-States, <=50K 49, Private, 160187, 9th, 5, Married-spouse-absent, Other-service, Not-in-family, Black, Female, 0, 0, 16, Jamaica, <=50K 52, Self-emp-not-inc, 209642, HS-grad, 9, Married-civ-spouse, Exec-managerial, Husband, White, Male, 0, 0, 45, United-States, >50K
#!/usr/bin/python3 import sys binary = 'binary' in sys.argv mixed = 'mixed' in sys.argv nocap = 'nocap' in sys.argv if binary: out = open('binary', 'w') elif mixed: out = open('mixed', 'w') elif nocap: out = open('nocap', 'w') else: out = open('data', 'w') for start, suffix in (0, 'data'), (1, 'test'):# 这里是从./decision-tree-mpc目录下读取训练样本和测试样本,可以不通过download.sh 来下载,可以直接将数据集放到这个目录下就可以了 (这里必须是两个集合 一个读入train 一个读入test 数据) data = [l.strip().split(', ') for l in open('adult.%s' % suffix)][start:-1] print(' '.join(str(int(x[-1].startswith('>50K'))) for x in data), file=out) #处理adult的label信息 将 '>50K' 的变成1 其余的label 就是0 (只能处理二分类问题) total = 0 #代表了总共的attribute属性的个数 max_value = 0 if not binary: if nocap: attrs = 0, 4, 12 else:#我们将会进入到这个循环,这里是处理属性是连续变量的数据 (adult中0,2,4,10....列都是连续属性) attrs = 0, 2, 4, 10, 11, 12 for i in attrs: print(' '.join(x[i] for x in data), file=out) total += 1 for x in data: max_value = max(int(x[i]), max_value) if binary or mixed or nocap:#会进入这个循环 values = [set() for x in data[0][:-1]] for x in data: for i, value in enumerate(x[:-1]): values[i].add(value) for i in 1, 3, 5, 6, 7, 8, 9: #对应离散值属性的处理。将其变成one-hot形式的属性来表示 x = sorted(values[i]) print('Using attribute %d:' % i, ' '.join('%d:%s' % (total + j, y) for j, y in enumerate(x))) total += len(x) for y in x: print(' '.join(str(int(sample[i] == y)) for sample in data), file=out) print(len(data), 'items') print(total, 'attributes') print('max value', max_value)
如果对应修改成iris.data ,prepare.py 文件如下:
#!/usr/bin/python3 import sys binary = 'binary' in sys.argv mixed = 'mixed' in sys.argv nocap = 'nocap' in sys.argv if binary: out = open('binary', 'w') elif mixed: out = open('mixed', 'w') elif nocap: out = open('nocap', 'w') else: out = open('data', 'w') for start, suffix in [(0, 'data'),(0,'test')]: data = [l.strip().split(',') for l in open('iris.%s' % suffix)]print(' '.join(str(int(x[-1].startswith('Iris-setosa'))) for x in data), file=out) total = 0 max_value = 0 if not binary: if nocap: attrs = 0, 4, 12 else: attrs = 0,1, 2,3 #int 类型的数据不需要处理的数据 for i in attrs: print(' '.join(str(int(float(x[i])*100)) for x in data), file=out) print(' '.join(str(int(float(x[i])*100)) for x in data)) total += 1 for x in data: max_value = max(int(float(x[i])), max_value) print(len(data), 'items') print(total, 'attributes') print('max value', max_value)
修改adult.mpc 文件(这个是运行生成决策树的文件)文件位置如下:

对应adult的代码分析:
m = 6 #属性个数 n_train = 32561 #训练集大小 n_test = 16281 #测试集大小 combo = 'combo' in program.args binary = 'binary' in program.args mixed = 'mixed' in program.args nocap = 'nocap' in program.args try: n_threads = int(program.args[2]) except: n_threads = None if combo: n_train += n_test if binary: m = 60 attr_lengths = [1] * m elif mixed or nocap: #进入这个if cont = 6 if mixed else 3 #con 代表连续属性的个数 m = 60 + cont #二进制(不用管) attr_lengths = [0] * cont + [1] * 60 # 0:连续属性 1:离散属性个数(one-hot之后) else: attr_lengths = None program.set_bit_length(32) program.options_from_args() train = sint.Array(n_train), sint.Matrix(m, n_train) test = sint.Array(n_test), sint.Matrix(m, n_test) for x in train + test: x.input_from(0) import decision_tree, util #decision_tree.debug_layers = True decision_tree.max_leaves = 3000 if 'nearest' in program.args: sfix.round_nearest = True sfix.set_precision_from_args(program, True) trainer = decision_tree.TreeTrainer( train[1], train[0], int(program.args[1]), attr_lengths=attr_lengths, n_threads=n_threads) trainer.debug_selection = 'debug_selection' in program.args trainer.debug_gini = True layers = trainer.train_with_testing(*test) #decision_tree.output_decision_tree(layers)
对应iris 的代码分析:
m = 4 #总共属性的个数 n_train = 124 #训练集个数 n_test = 25 #测试数据的个数 combo = 'combo' in program.args binary = 'binary' in program.args mixed = 'mixed' in program.args #采用的这个 nocap = 'nocap' in program.args try: n_threads = int(program.args[2]) except: n_threads = None if combo: n_train += n_test if binary: m = 4 elif mixed or nocap: cont = 4 #代表连续属性的个数 m = 4 attr_lengths = [0] * cont # else: attr_lengths = None program.set_bit_length(32) program.options_from_args() train = sint.Array(n_train), sint.Matrix(m, n_train) test = sint.Array(n_test), sint.Matrix(m, n_test) for x in train + test: x.input_from(0) import decision_tree, util #decision_tree.debug_layers = True decision_tree.max_leaves = 3000 if 'nearest' in program.args: sfix.round_nearest = True sfix.set_precision_from_args(program, True) trainer = decision_tree.TreeTrainer( train[1], train[0], int(program.args[1]), attr_lengths=attr_lengths, n_threads=n_threads) trainer.debug_selection = 'debug_selection' in program.args trainer.debug_gini = True layers = trainer.train_with_testing(*test) #decision_tree.output_decision_tree(layers)
过程中如果遇到问题,可以先看下我和这个作者的对话(github issue):Change to the iris dataset · Issue #2 · csiro-mlai/decision-tree-mpc (github.com)
