
3D渲染相关基本概念
渲染管线
图形渲染管线(Graphics Pipeline):将三维模型渲染到二维屏幕上的过程。为了满足实时性,管线在GPU硬件上进行实现,其与CPU流水线一样,各个步骤都会以并行的形式运行。
固定管线(Fixed-Function Pipeline):通常是指在较旧的GPU上实现的渲染流水线,通过DX、OpenGL等图形接口函数,开发者来对渲染流水线进行配置,控制权十分有限。
可编程管线(Programmable Pipeline):随着人们对画面品质和GPU硬件能力的提升,在原有固定管线流程中插入了Vertex Shader、Geometry Shader(非必需)、Fragment(Pixel) Shader等可编程的阶段,让开发者对管线拥有更大控制权
例如:Vertex Shader修改顶点属性(如顶点空间变换、逐顶点关照、uv变换)以及通过自定义属性向管线传入一些数据,Geometry Shader可增删和修改图元,Fragment(Pixel) Shader来进行逐像素的渲染
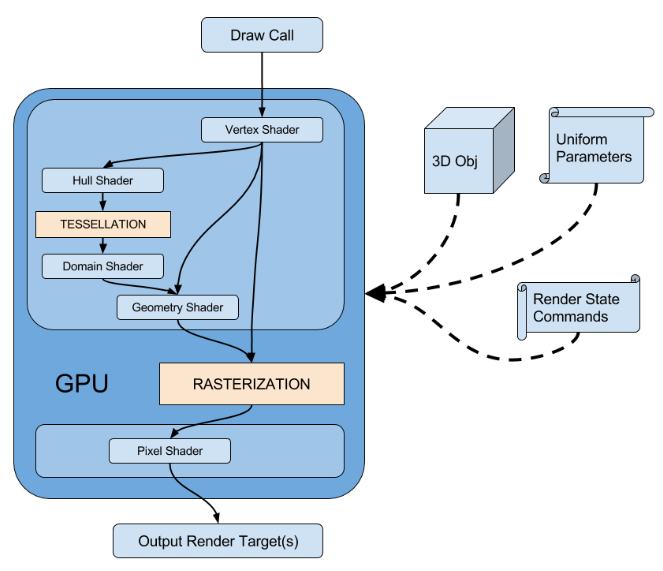
管线资源
材质(Material):用于描述光与物体的交互过程,即:如何反射(包括漫反射和镜面反射),折射,透射等。用于控制物体的视觉外观。是一些程序(即shader)、贴图以及其他属性的集合体。
在执行光照计算时,需要用到一些材质属性才能得到表面的最终颜色。
常见的几种属性有Diffuse(漫反射)、Emissive(自发光)、Specular(高光)、Normal(法线)等。
着色器(Shader):是执行在GPU上可编程图形管线的代码片段,用于告诉图形硬件如何绘制物体。包括:Vertex Shader、Fragment(Pixel) Shader、Geometry Shader。
Shader在早期是用汇编来编写的,后面出现更高级的着色语言,如DirectX的HLSL(High Level Shading Language)、OpenGL的GLSL(OpenGL Shading Language)以及nVidia的Cg(C for Graphic)。
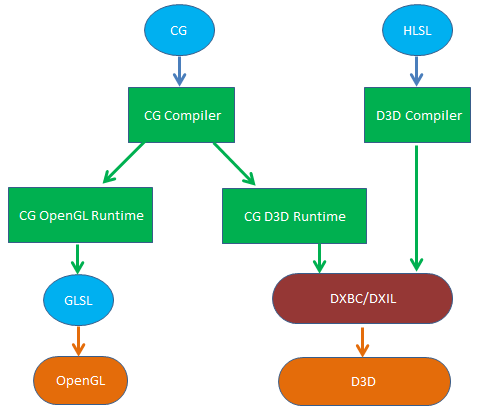
GLSL具有跨平台性,其在被OpenGL使用前不需要进行额外编译,而是由显卡驱动直接编译成GPU使用的机器指令。注:OpenGL4.1以上,可以通过glGetProgramBinary回读编译好的机器码,在相同的gpu驱动下避免二次编译。
HLSL仅能在windows平台上使用,需预先编译成与硬件无关的DX中间字节码(DXBC/DXIL,注:D3D12使用DirectX Shader Compiler,工具为dxc.exe,将HLSL编译成DXIL;之前的D3D版本使用d3dcompiler,工具为fxc.exe,将HLSL编译成DXBC)才能被D3D使用。
注:相比d3dcompiler,dxc虽然也需要将HLSL二次编译成GPU的机器码,但是我们可以回读这些机器码,然后缓存取来,这样就可以在相同的gpu驱动下避免二次编译。
CG语法上与HLSL高度相似,具有真正意义上的跨平台:在不同的平台上实现了shader编译器,并通过CG OpenGL Runtime和CG D3D Runtime来将CG转换成GLSL和DX中间字节码。
纹理(Texture):可以理解为运行时的贴图,可以通过UV坐标映射到模型的表面。另外,其拥有一些渲染相关的属性,如:纹理地址模式(ADDRESSU、ADDRESSV),纹理过滤方法(MAGFILTER、MINFILTER、MIPFILTER)等
图形API概念
DrawCall:为CPU向GPU发起的一个命令(如:OpenGL中的glDrawElements函数、D3D9中的DrawIndexPrimitive函数、D3D11中的Draw、DrawIndexed函数)。
这个命令仅仅会指向一个需要被渲染的图元(primitives)列表(IBO,Index Buffer Object)。发起DrawCall时,GPU就会根据渲染状态(RenderState)和输入的顶点数据(VBO,Vertex Buffer Object)来计算,最终输出成屏幕上显示的像素。
渲染状态(RenderState):这些状态定义了场景中Mesh是怎样被渲染的。如:使用哪个vs、哪个fs、光源属性、材质、纹理、是否开启混合等
颜色缓冲区(Color Buffer):即帧缓冲区(Frame Buffer,Back Buffer),用于存放渲染出来的图像。D3D存放在一个RTV(RenderTargetView)中。
深度缓冲区(Depth Buffer):用于存放深度的图像。D3D存放在一个DSV(DepthStencilView)中。
模板缓冲区(Stencil Buffer):用于获得某种特定效果的离屏缓存。分辨率与颜色缓冲区及深度缓冲区一致,因此模板缓冲区中的像素与颜色缓冲区及深度缓冲区是一一对应的。
其功能与模版类似,允许动态地、有针对性地决定是否将某个像素写入后台缓存中
D3D中,与深度缓冲区一起存放在一个DSV(DepthStencilView)中。
表面(Surface):D3D在显存中用于存储2D图像数据的一个像素矩阵。D3D9中对应的COM接口为IDirect3DSurface9。
Render Target(RT,渲染目标):对应显卡中一个内存块, D3D中概念(OpenGL中叫做FBO,Framebuffer object),常用于是离屏渲染。
渲染管线默认使用后备缓冲区(BackBuffer)RT来存放渲染结果,可通过调用CreateRenderTarget或RTT来创建多个额外的RT来进行离屏渲染,最后将它们组装到后备缓冲区(BackBuffer)中以产生最终的渲染画面。
注1:调用Device->CreateRenderTarget创建RT成功后,会返回IDirect3DSurface9* pRTSurface;然后调用Device->SetRenderTarget(0, pRTSurface)绑定pRTSurface到指定的RT索引。
在执行SetRenderTarget前可调用Device->GetRenderTarget(0, pOriginRTSurface),以便在完成RT绘制后还原回pOriginRTSurface所指向RT的Surface
对于不支持MRT的显卡,只会有一个索引为0的RT;对于支持MRT(N个)的显卡,索引可以为0,1, ...N-1,可同时绑定N个Surface到N个RT的索引上
注2:成功绑定RT后:对于不支持MRT的显卡,在Pixel Shader中通过标识COLOR0来写入内容到索引为0的RT中;对于支持MRT(N个)的显卡,在Pixel Shader中通过标识COLOR0, COLOR1, ...COLOR(N-1)来写入内容到对应的RT中
注3:可以调用Device->StretchRect来将RT的Surface拷贝到后备缓冲区(BackBuffer)或者另外一个Surface中
注4:可以调用Device->GetBackBuffer(0,0,D3DBACKBUFFER_TYPE_MONO,&pRTBackBuffer))来得到后备缓冲区(BackBuffer)的Surface
进一步可参考:Render to Surface
RTT(Render To Texture,渲染到纹理):用法与上面的RT一致,只是先调用Device->CreateTexture来创建出IDirect3DTexture9* pTexture,然后再通过pTexture->GetSurfaceLevel(0, IDirect3DSurface9**)来创建RT返回IDirect3DSurface9* pRTSurface
注:与上面RT相比,RTT不支持MultiSample 进一步可参考:渲染到纹理(Render To Texture, RTT)详解
MRT(Multiple Render Targets,多渲染目标):在一个pass(如:几何Pass,Geometry Pass)中将渲染信息保存到多个render target,并可在后续的管线流程中被其他shader使用或作为3D模型的纹理使用。
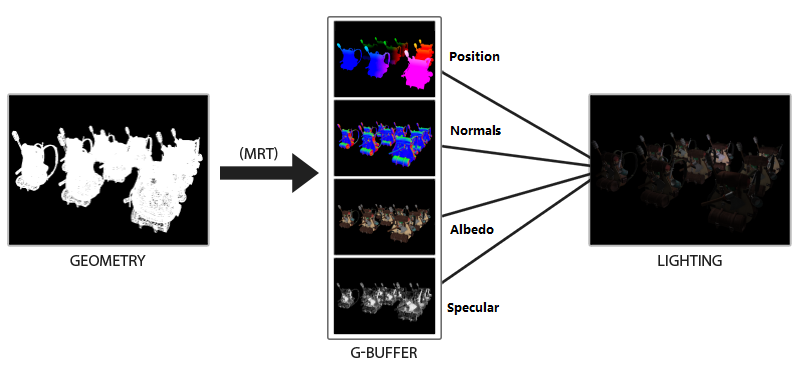
MRT需要显卡硬件和图形API(从OpenGL2.0和D3D9起)支持(对于不支持MRT的硬件可以使用多次渲染解决),提供了单个pass同时操作多个render target的能力,
MRT技术提高了渲染过程存储中间数据(如:Normal、Diffuse、Depth、Specular和Shininess等)的容量和渲染效率,是一种典型空间换时间的例子。注:Shininess值决定Specular光圈的大小
然而使用多个render target来渲染也并不是百利无一害,多个render target的读写IO开销也会不小,因此要紧凑地使用render target各bit来存储信息,能用一张就不要用两张,要尽量省以提升渲染效率。
(1) D3D9使用DirectX Caps Viewer查看显卡支持MRT个数
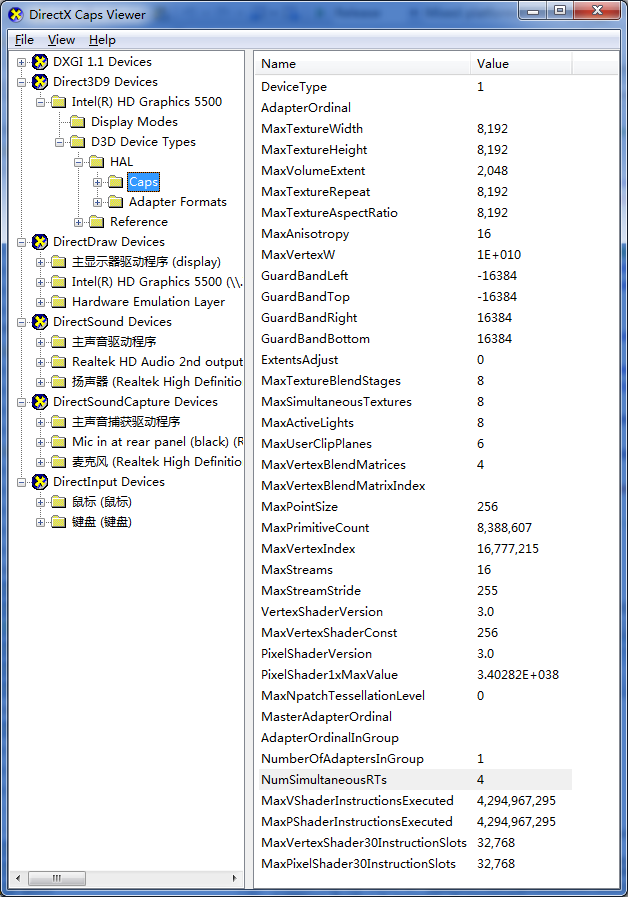
(2)D3D9可使用下列方法查询显卡支持MRT个数
D3DCAPS9 DeviceCaps; UINT AdapterIndex = D3DADAPTER_DEFAULT; D3DDEVTYPE DeviceType = D3DDEVTYPE_HAL; if(SUCCEEDED(Direct3D->GetDeviceCaps(AdapterIndex,DeviceType,&DeviceCaps))) { UINT32 MRTCount = DeviceCaps.NumSimultaneousRTs; // 支持MRT的个数 }
(3)D3D10最大支持MRT个数为D3D10_SIMULTANEOUS_RENDER_TARGET_COUNT // 8
D3D11最大支持MRT个数为D3D11_SIMULTANEOUS_RENDER_TARGET_COUNT // 8
实际支持多少个MRT由硬件显卡决定。mobile平台上,MRT最多只有4个,每个的bit数最多为32。
MRT的限制:
① 设定的RT需要具有相同的宽高
② 设定的RT一般需要有相同的位宽,比如同是16bits或32bits
G-Buffer(Geometry Buffer,几何缓冲区):延迟渲染管线中,在渲染场景物件时,用来存储几何和材质信息的RT图像(实际实现中常将各信息紧凑地挤进1个RT或MRT技术多个RT中),使得能在屏幕空间进行光照计算
Render Pass:现代游戏引擎会将渲染过程划分成多个Render Pass,一个模型会在多个Pass进行绘制处理。
例如UE的Mobile前向渲染,会先在PrePass中画带Mask透明材质模型的深度(用于后续Pass的EarlyZ剔除来减少OverDraw),然后再在BasePass中对模型进行着色,最后在Translucency的Pass中处理半透明的物体。
又比如阴影,需要先渲染深度图,再渲染场景,需要2个Pass。
Pass之间是相互依赖的,后面的Pass会用到前面Pass的数据(深度、几何信息),最后的Pass出来的数据才会写进FrameBuffer,所以Pass之间的关系可以形象的比喻为一道道工序。
渲染路径(Rendering Path)
前向渲染(Forward Rendering):逐光源逐物体进行光照计算
For each light:
For each object affected by the light:
framebuffer += object * light
对于多光源,使用Forward Rendering的效率会极其低下。 因为如果在vs中计算光照,其复杂度将是 O(num_geometry_vertexes∗num_lights)
而如果在fs中计算光照,其复杂度为 O(num_geometry_fragments∗num_lights) 。可见光源数目和复杂度是成线性增长的 。
延迟渲染(Deferred Shading):最早由Michael Deering在1988年的论文The triangle processor and normal vector shader: a VLSI system for high performance graphics提出,是一种基于屏幕空间着色的技术。
它的核心思想是将场景的物体绘制分离成两个Pass:几何Pass和光照Pass,目的是将计算量大的光照Pass延后,和物体数量和光照数量解耦,以提升着色效率。
计算光照的复杂度为 O(num_geometry_fragments + num_lights) 。在目前的主流渲染器和商业引擎中,有着广泛且充分的支持。
光照(lighting)
球谐光照(SH,Spherical harmonic lighting):用来计算低频环境光(即环境光diffuse部分)。用于Irradiance Volume和Precompute Radiance Transfer(PRT)。 https://huailiang.github.io/blog/2019/harmonics/
球谐光照实际上是一种对光照的简化,对于空间上的一点,受到的光照在各个方向上是不同的,也即各向异性,所以空间上一点如果要完全还原光照情况,那就需要记录周围球面上所有方向的光照。
注意这里考虑的周围环境往往是复杂的情况,而不是几个简单的光源,如果是那样的话,直接用光源的光照模型求和就可以了。
如果环境光照可以用简单函数表示,那自然直接求点周围球面上的积分就可以了。
但是通常光照不会那么简单,并且用函数表示光照也不方便,所以经常用的方法是使用环境光贴图,比如cubemap。
考虑一个简单场景中有个点,它周围的各个方向上的环境光照就是上面的cubemap呈现的,假如我想知道这个点各个方向的光照情况,那么就必须在cubemap对应的各个方向进行采样。
对于一个大的场景来说,每个位置点的环境光都有可能不同,每个点都对应一个cubemap,如果把每个点的环境光贴图储存起来,并且每次获取光照都从相应的贴图里面采样,可想而知这样的方法是非常昂贵的。
利用球谐函数就可以很好的解决这个问题,球谐函数的主要作用就是用简单的系数表示复杂的球面函数。
球谐光照实际上就是将周围的环境光采样成几个系数,然后渲染的时候用这几个系数来对光照进行还原,这种过程可以看做是对周围环境光的简化,从而简化计算过程。
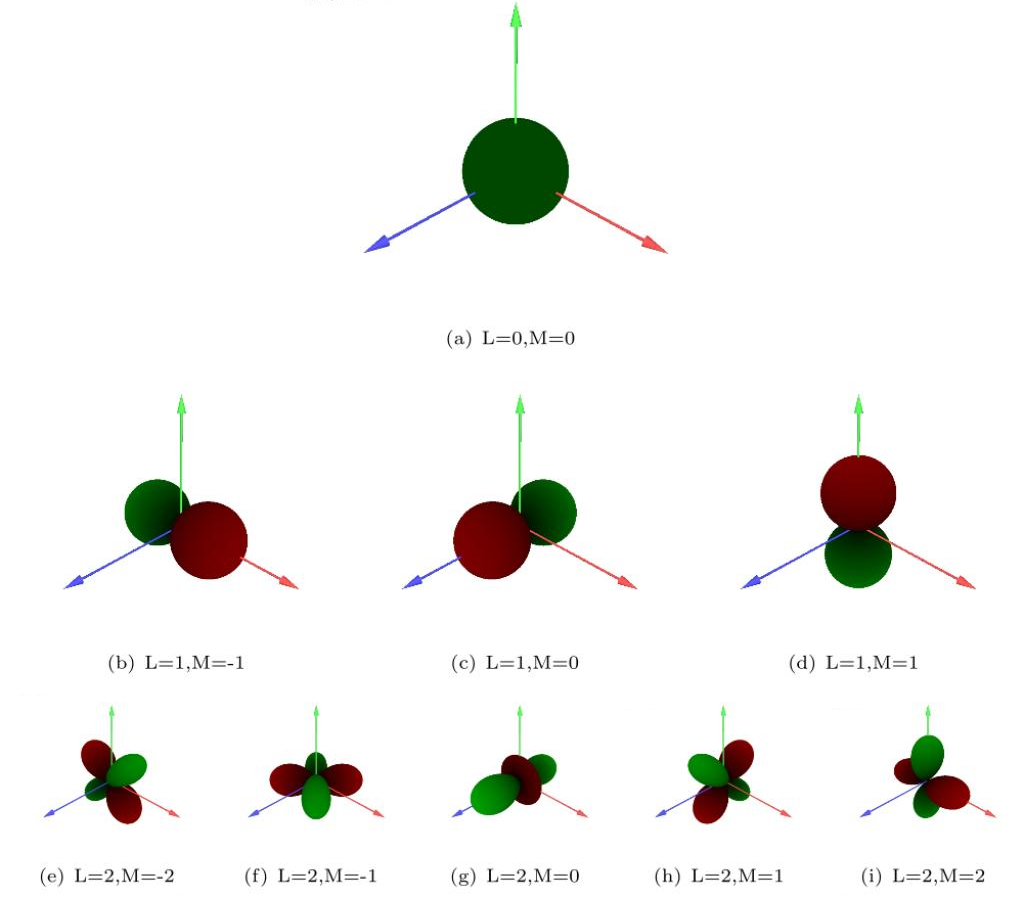
基于图像的光照(Image Based Lighting,IBL):将要反射的“环境”渲染为一张图(比如cubemap),然后渲染时通过查询这个贴图来计算来自周围的环境光照。用来计算环境反射光。https://huailiang.github.io/blog/2019/ibl/
PBR光照方程:
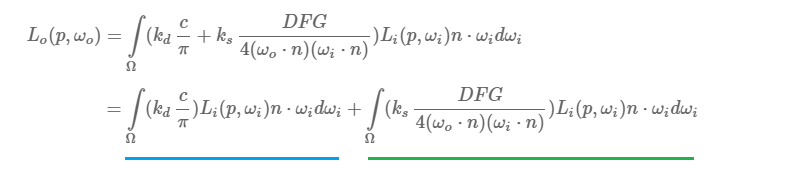
IBL计算环境光diffuse部分:
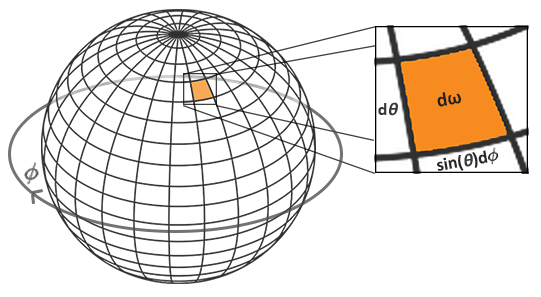
为了方便进行积分运算,一般都将渲染方程改为球面坐标的积分形式,其中:
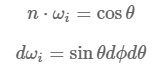
所以,方程转变为如下形式:
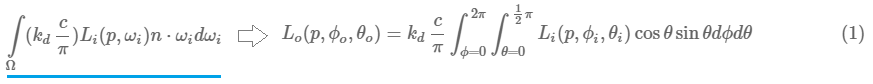
上述公式转换为Riemann Sum(黎曼和)的表述:
Riemann Sum是一种很简单的积分方法,当我们的步进值越小的时候,通过这种方法计算出来的h值就越加的接近真实值。
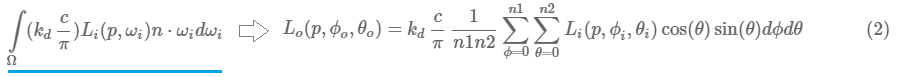
vec3 irradiance = vec3(0.0);
vec3 up = vec3(0.0, 1.0, 0.0);
vec3 right = cross(up, normal);
up = cross(normal, right);
float sampleDelta = 0.025;
float nrSamples = 0.0;
for(float phi = 0.0; phi < 2.0 * PI; phi += sampleDelta)
{
for(float theta = 0.0; theta < 0.5 * PI; theta += sampleDelta)
{
// spherical to cartesian (in tangent space)
vec3 tangentSample = vec3(sin(theta) * cos(phi), sin(theta) * sin(phi), cos(theta));
// tangent space to world
vec3 sampleVec = tangentSample.x * right + tangentSample.y * up + tangentSample.z * N;
irradiance += texture(environmentMap, sampleVec).rgb * cos(theta) * sin(theta);
nrSamples++;
}
}
irradiance = PI * irradiance * (1.0 / float(nrSamples));cubemap在球谐面卷积采样, 生成的irradianceMap图(预计算辐射光照贴图),有点类似模糊的效果,大小就32x32, 精度不需要那么高, 中间值使用插值就可以得到。

IBL计算环境光specular部分:
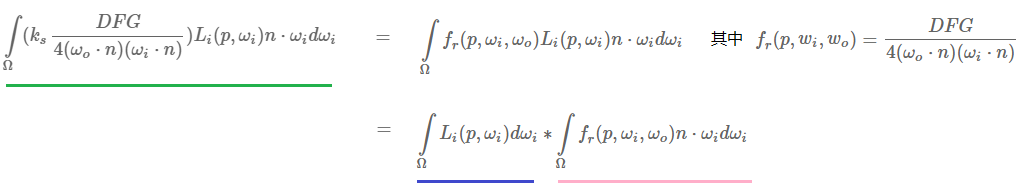
第一部分,我们使用预过滤环境贴图来解决,并且我们把粗糙度加入进去。由于粗糙程度的增加,环境贴图需要更多的离散采样向量和更多的模糊反射。
对于每一个粗糙度等级,我们将其连续的模糊结果储存在预过滤贴图的mipmap等级中。如下例所示:我们将5个不同模糊等级的结果存储在5个mipmap等级的贴图中。

第二部分,该部分就是双向反射分布函数(BRDF)的镜面反射积分。
如果我们假设每个方向的入射光的颜色是白的(即L(p,x)=1.0),在给出粗糙度和法线n与光向量Wi的夹角的情况下,我们可以预计算双向反射分布函数(BRDF)的返回值。
Epic Games 会根据每个法线n与光向量Wi的组合以及粗糙度来存储一个值到2D的查找纹理当中(LUT),这个贴图也叫做BRDF积分贴图。
这个2D的查找纹理输出一个scale(对应于图片的红色分量)和一个偏移值(绿色分量)为菲涅尔方程提供参数。

右边部分要求我们在给出N与W0的夹角、表面粗糙度和菲涅尔F0后对BRDF方程进行卷积。这很像当Li为1.0时对镜面BRDF进行积分。在3个变量的情况下对BRDF进行卷积十分麻烦,但是我们可以把F0移出镜面BRDF方程:
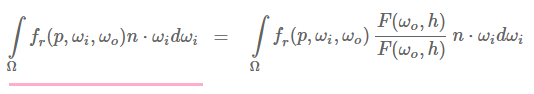
F代表的是菲涅尔方程。将菲涅尔移动到BRDF的分母上,可以得到如下方程:
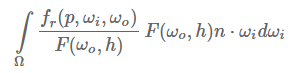
我们用菲涅尔方程的近似值来代替最右边的菲涅尔方程:
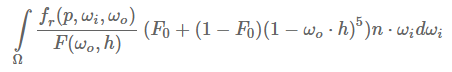
让我们用α来代替(1−ωo⋅h)5(1−ωo⋅h)^5,以便于更方便的解决F0:

然后我们将其分成两部分:
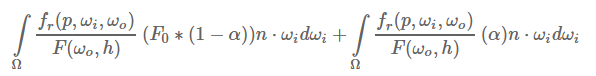
接下来,我们可以把F0提到积分外面,并将α变回原来的式子:
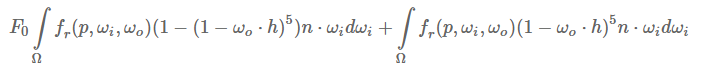
注意!!因为本身f(p,ωi,ωo)包含菲涅尔方程, 所以我们可以将分母上的F与其抵消~
使用一种相似的方式更早的对环境贴图进行卷积,我们可以通过BRDF方程的输入进行卷积:N与W0的夹角和粗糙度以及存储在纹理中的卷积结果。我们将卷积结果存储在一张2D查找纹理中(LUT),也被称为BRDF积分贴图,我们稍后会在PBR光照着色器中使用它来得到简介镜面反射结果。
BRDF卷积着色器对一个2D平面进行操作,使用2D纹理的坐标作为BRDF 卷积的直接输入(NdotV和粗糙度)。这部分的卷积代码与预过滤卷积代码十分的相似,不同之处是它的采样向量是根据BRDF的几何函数和菲涅尔方程近似值得到的:
vec2 IntegrateBRDF(float NdotV, float roughness)
{
vec3 V;
V.x = sqrt(1.0 - NdotV*NdotV);
V.y = 0.0;
V.z = NdotV;
float A = 0.0;
float B = 0.0;
vec3 N = vec3(0.0, 0.0, 1.0);
const uint SAMPLE_COUNT = 1024u;
for(uint i = 0u; i < SAMPLE_COUNT; ++i)
{
// generates a sample vector that's biased towards the
// preferred alignment direction (importance sampling).
vec2 Xi = Hammersley(i, SAMPLE_COUNT);
vec3 H = ImportanceSampleGGX(Xi, N, roughness);
vec3 L = normalize(2.0 * dot(V, H) * H - V);
float NdotL = max(L.z, 0.0);
float NdotH = max(H.z, 0.0);
float VdotH = max(dot(V, H), 0.0);
if(NdotL > 0.0)
{
float G = GeometrySmithIBL(N, V, L, roughness);
float G_Vis = (G * VdotH) / (NdotH * NdotV);
float Fc = pow(1.0 - VdotH, 5.0);
A += (1.0 - Fc) * G_Vis;
B += Fc * G_Vis;
}
}