字符编码
乱码
主要原因有:
1. 文本文件的编码与解码程序不一致(如:浏览器把GBK码的网页当成Big5码进行显示)
2. 字体中没有对应文字的形状定义(表现为使用方框来填充)
ASCII / EASCII(1个字节)- 起源
下面的ASCII表中:淡蓝色部分为控制字符,淡灰色部分为可显示字符

EASCII是ASCII的扩充,新增了的符号包括表格符号、计算符号、希腊字母和特殊的拉丁符号。

http://www.rapidtables.com/code/text/ascii-table.htm
在Windows下,打开小键盘,按住ALT键,然后输入EASCII码[如:按住ALT键并依次输入数字键区数字2、4、7可输入÷]。
在Vim中,在插入模式下,可以先按Ctrl-V,再输入代表EASCII码的(至多三位)十进制数字。
ASCII/EASCII编码被世界上任意一种字符编码所兼容!!
GB2312、GBK、GB18030(多字节字符集【MBCS】,最常见的MBCS实现是双字节字符集 (DBCS))- 各自为政
【内容】:
GB2312字符集中除常用简体汉字字符外还包括希腊字母、日文平假名及片假名字母、俄语西里尔字母等字符,共7445个字符。
GBK增加了繁体字、生僻字、汉字部首符号、竖排标点符号等内容,是GB2312编码的超集,向下完全兼容GB2312,兼容的含义是不仅字符兼容,而且相同字符的编码也相同。共20902个字符。
GB18030收录了所有Unicode3.1中的字符,包括中国少数民族字符,GBK不支持的韩文字符等等,也可以说是世界大多民族的文字符号都被收录在内。
【特点】:
GB2312和GBK都是双字节等宽编码,如果算上和ASCII兼容所支持的单字节,也可以理解为是单字节和双字节混合的变长编码。
GB18030编码是变长编码,有单字节、双字节和四字节三种方式。
GB18030 > GBK > GB2312,依次向下兼容。
除了GB系列的中文编码方式外,世界各个地区也都有自己的编码方式,例如:港澳台地区的繁体汉字Big5编码、日本的SJIS编码、韩国的KSC编码等
这些字符编码之间不兼容,互相冲突,给全球信息交换带来了很大的麻烦。
UNICODE - 天下归一
标准方式:ucs2、ucs4
ucs2:用两个字节编码;可容纳65536个字符,基本可以包含世界所有国家的常用文字了。
ucs4:用四个字节编码;可容纳2147483648(21亿)个字符,如果需要考虑一些偏僻字,那么ucs4则绝对可以满足了。
标准方式将所有字符一视同仁,会带来浪费空间的问题,因此,人类在标准方式的基础上,发明了uft编码。
实现方式:utf8、utf16、utf32
utf8以字节为单位对Unicode进行编码,一个英文字符占1个字节,汉字占3个字节;
utf16以16位无符号整数为单位对Unicode进行编码,中文英文都占2个字节;utf16可看成是ucs2的父集。对于两个字节的ucs码,utf16编码就等于ucs码。
英文范围:0x0000-0x007F 中文范围:0x4E00-0x9FBF
utf32以32位无符号整数为单位对Unicode进行编码,中文英文都占4个字节。utf32可看成是ucs4的父集,目前uft32完全等同于ucs4。
中文"汉字"的utf8、utf16、utf32的编码如下:
1 BYTE data_utf8[] = {0xE6, 0xB1, 0x89, 0xE5, 0xAD, 0x97}; // UTF-8编码 2 WORD data_utf16[] = {0x6c49, 0x5b57}; // UTF-16编码 3 DWORD data_utf32[] = {0x00006c49, 0x00005b57}; // UTF-32编码
小端大端(uft16、uft32)
x86,MOS Technology 6502,Z80,VAX,PDP-11等处理器为Little endian。注:windows系统使用的x86的处理器,因此windows为小端序
Motorola 6800,Motorola 68000,PowerPC 970,System/370,SPARC(除V9外)等处理器为Big endian
ARM, PowerPC (除PowerPC 970外), DEC Alpha, SPARC V9, MIPS, PA-RISC and IA64的字节序是可配置的。

文本文件在起始处使用BOM(Byte Order Mark)来区分不同字节序的utf编码,具体如下:

在线工具 http://tool.chinaz.com/tools/unicode.aspx
http://www.haomeili.net/Code/DetailCodes?wd=%E4%B8%AD
https://unicode-table.com/cn/ (Unicode表)
windows记事本:

注:ANSI - 表示使用本地系统的字符集
notepad++:

注:ANSI - 表示使用本地系统的字符集
vs2008:

vs2008工程字符集设置:

注:未设置 - 表示使用本地系统的字符集。
本地系统的字符集可用GetACP()获取当前的codepage值来得到,codepage值与字符集的对应表在这里!!!
可以在“区域和语言”面板中通过“更改系统区域设置”来修改当前的codepage值。
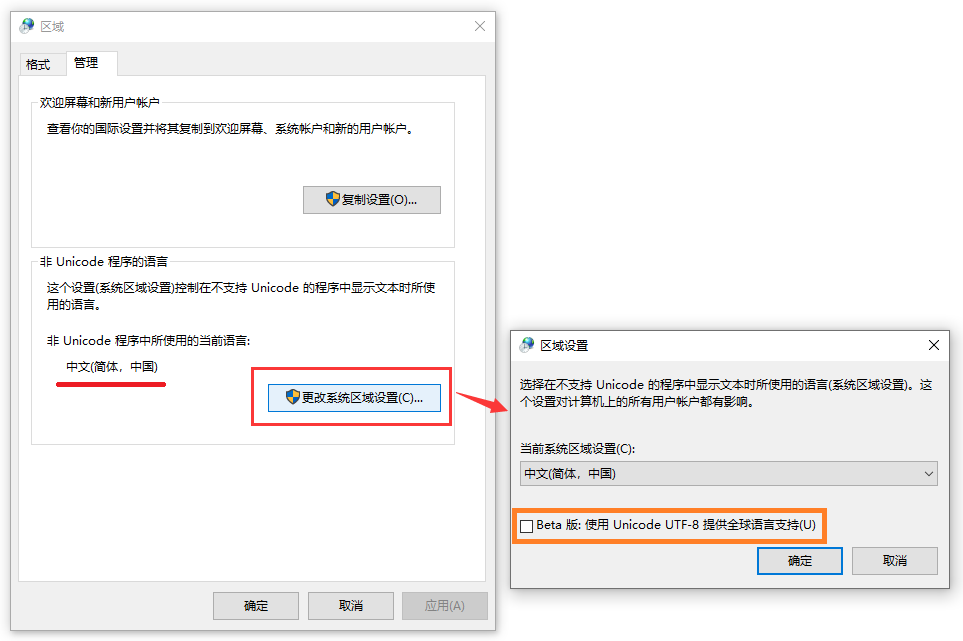
注:win10系统还可以通过勾选“Beta版: 使用Unicode UTF-8 提供全球语言支持”来将本地系统的字符集设置成utf8
windows对unicode的支持:
Windows操作系统内核中的字符表示为UTF-16小尾序,可以正确处理、显示以4字节存储的字符。
但是WindowsAPI实际上仅能正确处理UCS-2字符,即仅以2字节存储的,码位小于U+FFFF的Unicode字符。
其根源是Microsoft C++语言把wchar_t数据类型定义为16比特的unsigned short,
这就与一个wchar_t型变量对应一个宽字符,可以存储一个Unicode字符的规定相矛盾。
相反,Linux平台的GCC编译器规定一个wchar_t是4字节长度,可以存储一个UTF-32字符,宁可浪费了很大的存储空间。
验证程序:

参考:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号