Direct3D Compute Shader基础
从DirectX 11.0版本(即SM5.0,需win7及以上)开始,引入Compute Shader(计算着色器)来进行GPU编程。
Compute Shader不属于图形渲染管线的一个步骤,使得开发者可以脱离图形渲染管线的束缚,利用GPU强大的并行计算能力来提升性能。
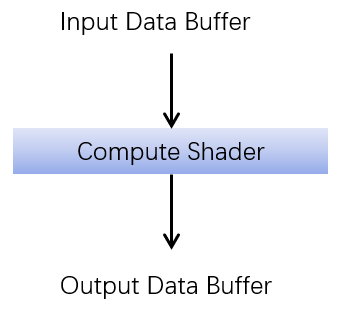
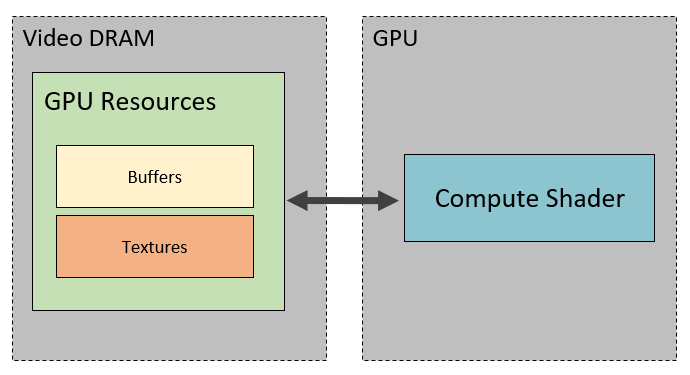
通过它对GPU资源进行读写操作,运行的结果通常会保存在Direct3D的资源中,我们可以将它作为结果显示到屏幕,或者给别的地方作为输入使用,或者将它保存到本地。
GPU用在非图形用途的应用程序可以称之为:通用GPU(GPGPU)编程。对于GPGPU编程,用户通常需要从显存中获取运算结果,将其传回CPU。
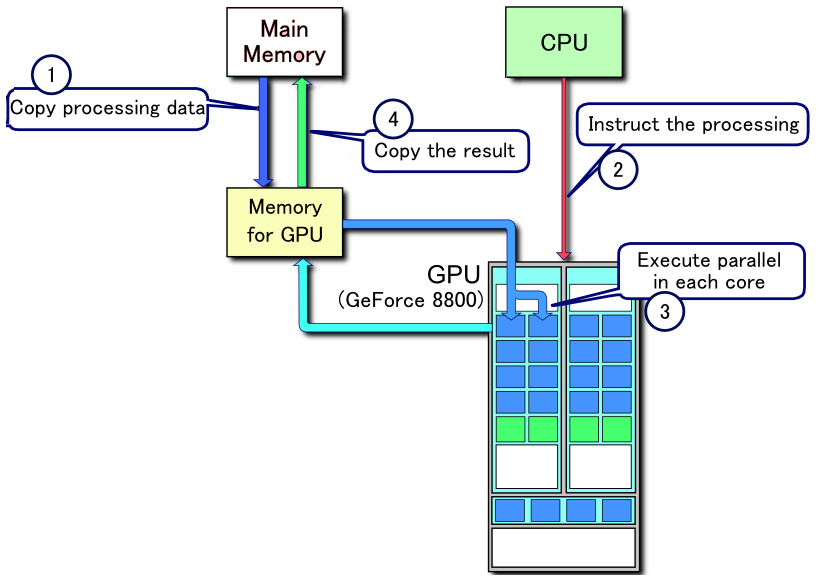
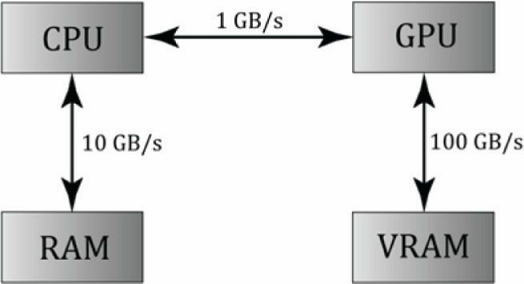
将显存结果复制到内存中,这样虽然速度会慢一些,但起码还是比直接在CPU运算会快很多。
如果是用于图形编程的话,倒是可以省掉数据传回CPU的时间,比如:我们要对渲染好的场景再通过计算着色器来进行一次模糊处理。
Compute Shader(计算着色器)使用的是HLSL语言来编写逻辑。
CSInput g_Input; CSOutput g_Output; void ComputeShader() { CSInput &input = g_Input; CSOutput &output = g_Output; // compute code ... }
在C++侧通过Dispatch发起调用
需要从CPU侧调用Dispatch方法来执行Compute Shader
void ID3D11DeviceContext::Dispatch( UINT ThreadGroupCountX, // [In]X维度下线程组数目 UINT ThreadGroupCountY, // [In]Y维度下线程组数目 UINT ThreadGroupCountZ); // [In]Z维度下线程组数目
也可以使用DispatchIndirect方法来执行
void DispatchIndirect( [in] ID3D11Buffer *pBufferForArgs, [in] UINT AlignedByteOffsetForArgs );
注:ID3D11Buffer *pBufferForArgs是一块指向显存的Buffer数据,此时AlignedByteOffsetForArgs为偏移值16
16 20 24 28 ---------------------------+-------------------+-------------------+-------------------+--- ThreadGroupCountX | ThreadGroupCountY | ThreadGroupCountZ | ---------------------------+-------------------+-------------------+-------------------+---
在某些时候,可能不知道要创建多少个线程组,需要依赖上个Compute Shader执行后的结果,来动态设置ID3D11Buffer *pBufferForArgs中的ThreadGroupCountX、ThreadGroupCountY、ThreadGroupCountZ数值
线程组(Thread Group)
一个线程组由一个多核处理器(Streaming MultiProcessor)来执行,cs着色器程序会Dispatch给多个线程组(Thread Group)来并发执行。
如果你的GPU有16个多核处理器,你会想要把问题分解成至少16个线程组以保证每个处理器都工作。
为了获取更好的性能,让每个处理器来处理至少2个线程组是一个比较不错的选择,这样当一个线程组在等待别的资源时就可以先去考虑完成另一个线程组的工作。
虽然可以设置任意数值,但出于性能考虑,最好还是把线程组的各维度大小设为1或32的倍数(32、64、96、128、160、192、224、256等)。如:Dipatch(32, 32, 1);
一个线程组由N个线程组成。硬件实际上会将这些线程划分成一系列warps(一个warp包含32个线程),并且一个warp由SIMD32中的多处理器进行处理(32个线程同时执行相同的指令)。注:GPU为单指令多数据模式
注:在cs4.x下,一个线程组的最大线程数为768,且Z的最大值为1。在cs5.0下,一个线程组的最大线程数为1024,且Z的最大值为64。
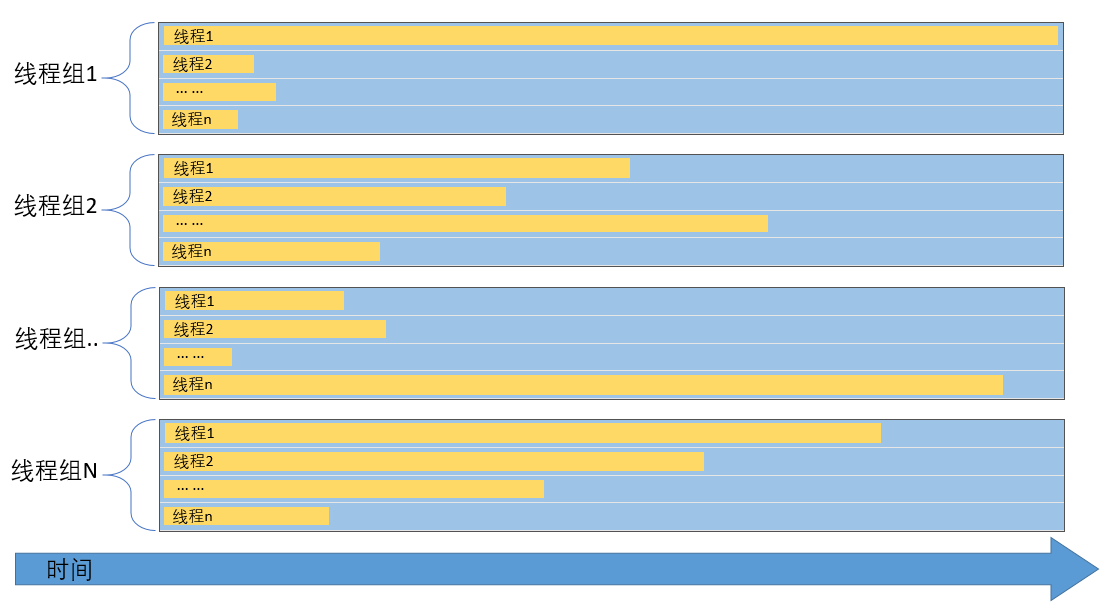
在Compute Shader中,通过线程修饰符numthreads来指定一个线程组中的线程数目
如果使用1D纹理,线程修饰符通常为[numthreads(X, 1, 1)]或[numthreads(1, Y, 1)];如果使用2D纹理,线程修饰符通常为[numthreads(X, Y, 1)],即第三维度为1。
① 仅带上SV_DispatchThreadID语义参数
[numthreads(16, 16, 1)] // 一个线程组中的线程数目,进行2维排布。注:线程可以1维展开,也可以2维或3维排布 void CS( uint3 DTid : SV_DispatchThreadID ) { // DTid为SV_DispatchThreadID uint x = DTid.x; uint y = DTid.y; uint z = DTid.z;
// ... ...
}
② 带上SV_GroupID、SV_DispatchThreadID、SV_GroupThreadID、SV_GroupIndex语义参数
[numthreads(256, 1, 1)] // 一个线程组中的线程数目,进行1维展开。注:线程可以1维展开,也可以2维或3维排布 void CS(uint3 Gid : SV_GroupID, uint3 DTid : SV_DispatchThreadID, uint3 GTid : SV_GroupThreadID, uint GI : SV_GroupIndex) { // SV_GroupID uint Gx = Gid.x; uint Gy = Gid.y; uint Gz = Gid.z; // SV_DispatchThreadID uint DTx = DTid.x; uint DTy = DTid.y; uint DTz = DTid.z; // SV_GroupThreadID uint GTx = GTid.x; uint GTy = GTid.y; uint GTz = GTid.z; // SV_GroupIndex uint idx = GI;
// ... ...
}
下图以Dispatch(5, 3, 2)和[numthreads(10, 8, 3)]为例来讲解线程组和线程之间的关系:
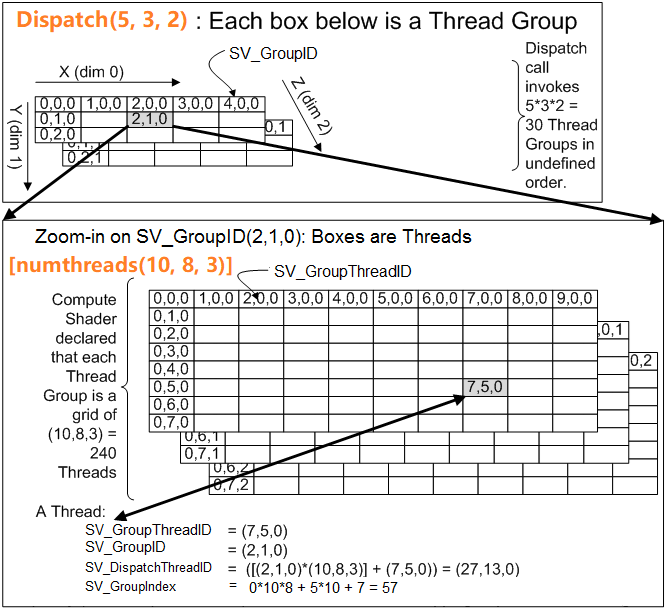
当Dispatch(a, b, c)和numthreads(m, n, p)时,SV_GroupThreadID、SV_GroupID、SV_DispatchThreadID、SV_GroupIndex的范围如下:
| # | 解释 | 最小(min) | 最大(max) |
| SV_GroupThreadID | 线程在其线程组中的三维索引值 | (0, 0, 0) | (m-1, n-1, p-1) |
| SV_GroupID | 当前线程组的三维索引值 | (0, 0, 0) | (a-1, b-1, c-1) |
| SV_DispatchThreadID | 线程在全局范围内的三维索引值 | (0, 0, 0) |
(a-1, b-1, c-1) * (m, n, p) + (m-1, n-1, p-1) = (a*m-1, b*n-1, c*p-1) = SV_GroupID * (m, n, p) + SV_GroupThreadID |
| SV_GroupIndex | 线程在其线程组中的一维索引值 | 0 | (p-1)*m*n + (n-1)*m + (m-1) = p*m*n -1 |
内存模型
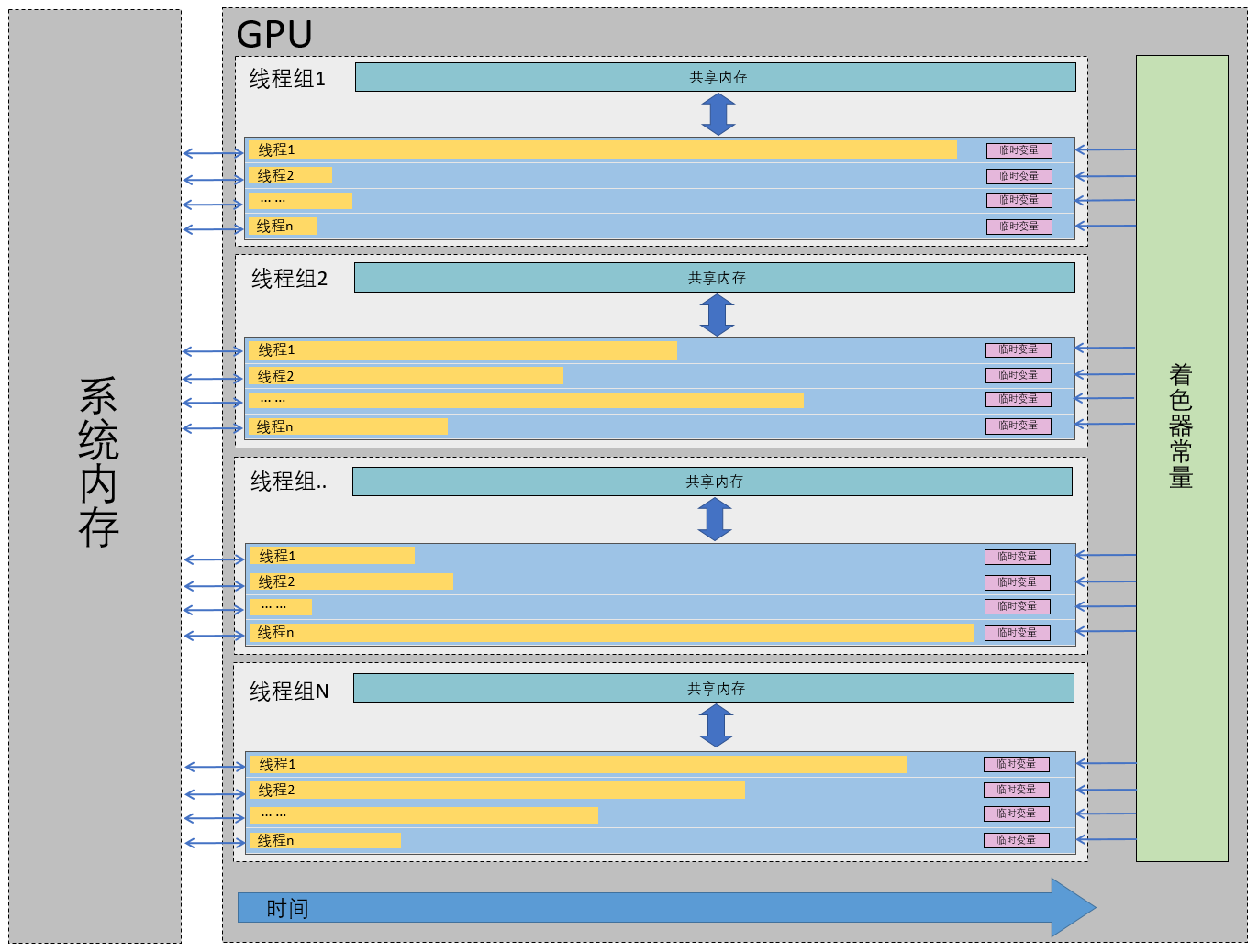
| 类型 | 说明 | 作用范围 | 读写情况 | 访问速度 | 可用内存 | 是否需要同步 |
| 系统内存 |
D3D设备创建出来的资源,这些资源可以长期存在,只要引用计数不为0。 可以给这些资源创建很大的内存空间来使用,但当执行频繁的读写操作时,性能将会受到严重影响。 ① 有类型的缓冲区(Typed Buffer) Buffer<float4> Buffer : register(t0); // 只读 RWBuffer<float4> RWBuffer : register(u0); // 可读写 ② 纹理 Texture2D DiffuseTexture : register( t0 ); // 只读 RWTexture2D<float4> MyTexture : register( u0 ); // 可读写 注1:绑定寄存器后,shader中会拿到Buffer和纹理的句柄来进行操作,但实际的数据块仍然在系统内存中。 注2:对于只读的Buffer和纹理的句柄,需要在c++中绑定SRV(ShaderResourceView),来供shader读取其在系统内存中的数据。 注3:对于可读写的Buffer和纹理的句柄,需要在c++中绑定UAV(UnorderedAccessView),来供shader读写其在系统内存中的数据。 |
所有线程 | 只读或读写,可设置 | 慢 | 大 | 需要 |
| 共享内存 |
每个线程组最多只能分配32KB内存(即8192个标量,或2048个向量),供内部所有线程使用。不同的线程组不能相互访问对方的共享内存。 内部线程通常应该使用 注:分配太多的组共享内存会导致性能问题。假如一个多处理器支持32kb的组共享内存,然后你的计算着色器需要20kb的组共享内存,这意味着一个多处理器只适合处理一个线程组, 因为剩余的组共享内存不足以给新的线程组运行,这也会限制GPU的并行运算,当该线程组因为某些原因需要等待,会导致当前的多处理器处于闲置状态。 因此保证一个多处理器至少能够处理两个或以上的线程组(比如每个线程组分配16kb以下的组共享内存),以尽可能减少该多处理器的闲置时间。 #define BITONIC_BLOCK_SIZE 512 groupshared uint shared_data[BITONIC_BLOCK_SIZE]; [numthreads(BITONIC_BLOCK_SIZE, 1, 1)] void CS(uint3 Gid : SV_GroupID, uint3 DTid : SV_DispatchThreadID, uint3 GTid : SV_GroupThreadID, uint GI : SV_GroupIndex) { }
在全局变量前面加groupshared 注:仅支持计算着色器 |
线程组内 | 可读写 | 较快 | 较小 | 需要 |
| 着色器常量 |
有数目限制和大小限制。 ① 常量缓冲区(Constant Buffer) cbuffer ConstantBuffer : register(b0)
{
float4x4 g_WorldViewProj;
}
② 纹理缓冲区(Texture Buffer) 纹理缓冲区并不是用来存储纹理的,而是指可以像纹理那样来访问其中的数据,对于索引类数据有更好的性能。这些数据也是只读的。 tbuffer mytb : register(t0) { float weight[256]; // 可以从CPU更新,只读 } 注:绑定寄存器后,数据会复制到常量寄存器中,被shader代码私有访问。 |
所有线程 | 只读 | 快 | 小 | 不需要 |
| 临时变量 |
仅shader中可见的全局变量和函数内局部变量 注:shader编译成汇编后,这些变量会放在临时寄存器(r#或x#)中,被shader代码私有访问。 |
线程私有 | 可读写 | 最快 | 小 | 不需要 |
线程同步
线程是并发运行的,它们能通过组内共享内存或通过无序访问视图(UAV)对应的资源进行交互,因此需要能够同步线程之间的内存访问。
内存屏障(MemoryBarrier)
Shader Model 5在HLSL中引入了内存屏障函数,可用于同步线程组中所有线程的内存访问。
这些函数有两个不同的属性。第一个是同步的内存类别(设备内存、组内共享内存,或两者都有),第二个则指定给定线程组中的所有线程是否同步到其执行过程中的同一处。
根据这两个属性,衍生出了下面这些不同版本的内置函数:
| 类别 | 函数 | 示例 |
|---|---|---|
| 不带组内同步 | GroupMemoryBarrier() |
阻止执行组中的所有线程,直到所有组共享访问都已完成。 注:线程组中的所有线程对组内共享内存的所有写入都完成,保证后续能读到最新数据。 |
| DeviceMemoryBarrier() | 阻止执行组中的所有线程,直到所有设备内存访问都已完成。 | |
| AllMemoryBarrier() | 阻止执行组中的所有线程,直到所有内存访问都已完成。 | |
| 带组内同步 | GroupMemoryBarrierWithGroupSync() |
阻止执行组中的所有线程,直到所有组共享访问都已完成,并且组中的所有线程都已达到此调用。 注1:将双调排序项目中 因此可以这样判断:GroupMemoryBarrier()仅在线程组内的所有线程组存在线程写入操作时阻塞, 但可能会出现阻塞结束时绝大多数线程完成了共享数据写入,仍有少量线程甚至还没开始写入共享数据。因此实际上很少能够见到他出场的机会。 注2: 很明显,在所有组内共享内存都加载之前,我们不希望任何线程前进,这使它成为我们需要的完美同步方法。 |
| DeviceMemoryBarrierWithGroupSync() | 阻止执行组中的所有线程,直到所有设备内存访问都已完成,并且组中的所有线程都已达到此调用。 | |
| AllMemoryBarrierWithGroupSync() | 阻止执行组中的所有线程,直到所有内存访问都已完成,组中的所有线程都已到达此调用。 |
现在来考虑下面的代码:
Texture2D g_Input : register(t0); RWTexture2D<float4> g_Output : register(u0); groupshared float4 g_Cache[256]; [numthreads(256, 1, 1)] void CS(uint3 GTid : SV_GroupThreadID, uint3 DTid : SV_DispatchThreadID) { // 将纹理像素值缓存到组共享内存 g_Cache[GTid.x] = g_Input[DTid.xy]; // 取出组共享内存的值进行计算 // 注意!!相邻的两个线程可能没有完成对纹理的采样 // 以及存储到组组共享内存的操作 float left = g_Cache[GTid.x - 1]; float right = g_Cache[GTid.x + 1]; // ... }
因为多个线程同时运行,同一时间各个线程当前执行的指令有所偏差,有的线程可能已经完成了组共享内存的赋值操作,有的线程可能还在进行纹理采样操作。
如果当前线程正在读取相邻的组共享内存片段,结果将是未定义的。为了解决这个问题,我们必须在读取组共享内存之前让当前线程等待线程组内其它的所有线程完成写入操作。这里我们可以使用GroupMemoryBarrierWithGroupSync函数:
Texture2D g_Input : register(t0); RWTexture2D<float4> g_Output : register(u0); groupshared float4 g_Cache[256]; [numthreads(256, 1, 1)] void CS(uint3 GTid : SV_GroupThreadID, uint3 DTid : SV_DispatchThreadID) { // 将纹理像素值缓存到组共享内存 g_Cache[GTid.x] = g_Input[DTid.xy]; // 等待所有线程完成写入 GroupMemoryBarrierWithGroupSync();
// 现在读取操作是线程安全的,可以开始进行计算 float left = g_Cache[GTid.x - 1]; float right = g_Cache[GTid.x + 1]; // ... }
原子操作
Shader Model 5在HLSL中引入了原子操作函数,可以在线程之间提供更细力度的同步。
原子操作可以用于组内共享内存和资源内存。只支持int、uint类型。
| 函数 | 示例 |
|---|---|
| InterlockedAdd |
groupshared int n1 = 110; InterlockedAdd(n1, 5); // n1=115 注:第3个参数可选 |
| InterlockedMin |
groupshared int n1 = 110; InterlockedMin(n1, 5); // n1=5 groupshared uint n2 = 120; uint r; InterlockedMin(n2, 200, r); // r=120 n2=120 注:200比120大,所以n2仍然为120 注:第3个参数可选 |
| InterlockedMax |
groupshared int n1 = 110; InterlockedMax(n1, 5); // n1=110 注:110比5大,所以n1仍然为110 groupshared uint n2 = 120; uint r; InterlockedMax(n2, 200, r); // r=120 n2=200 注:第3个参数可选 |
| InterlockedOr |
groupshared int n11 = 9; int n12 = 12; InterlockedOr(n11, n12); //n11=9|12=1001|1100=1101=13 n12=12 groupshared uint n21 = 8; uint n22 = 6; uint r; InterlockedOr(n21, n22, r); //r=8 n21=8|6=1000|0110=1110=14 n22=6 注:第3个参数可选 |
| InterlockedAnd |
groupshared int n11 = 9; int n12 = 12; InterlockedAnd(n11, n12); //n11=9&12=1001&1100=1000=8 n12=12 groupshared uint n21 = 8; uint n22 = 6; uint r; InterlockedAnd(n21, n22, r); //r=8 n21=8&6=1000&0110=0000=0 n22=6 注:第3个参数可选 |
| InterlockedXor |
groupshared int n11 = 9; int n12 = 12; InterlockedXor(n11, n12); //n11=9^12=1001^1100=0101=5 n12=12 groupshared uint n21 = 8; uint n22 = 6; uint r; InterlockedXor(n21, n22, r); //r=8 n21=8^6=1000^0110=1110=14 n22=6 注:第3个参数可选 |
| InterlockedCompareStore |
RWStructuredBuffer<uint> color; int i = 10; InterlockedCompareStore(color[i], 1, 3); // if (color[i]==1) {color[i]=3;}
|
| InterlockedCompareExchange |
RWStructuredBuffer<int> color1; int n1= 10; InterlockedCompareExchange(color[n1], 1, 3); // if (color1[n1]==1) {color1[n1]=3;} RWStructuredBuffer<uint> color2; int n2= 12; int r; InterlockedCompareExchange(color[n2], 5, 8, r); // r=color2[n2]; if (color2[n2]==5) {color2[n2]=8;} 注:第4个参数可选 |
| InterlockedExchange |
groupshared int n11 = 150; int n12 = 151; 注:第3个参数可选 |
示例
将flare.dds和flarealpha.dds两张图片混合,并将结果输出到一张图片中。
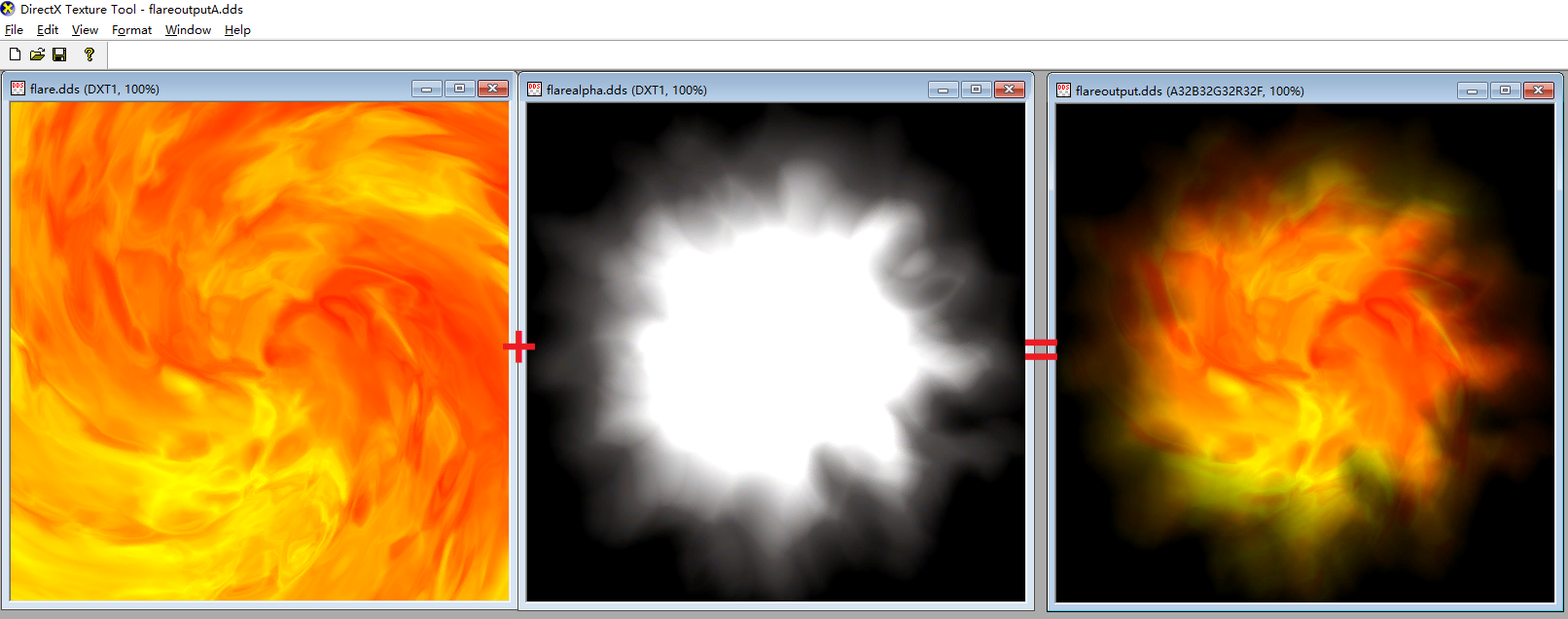
TextureMul_R32G32B32A32_CS.hlsl代码如下:
Texture2D g_TexA : register(t0); Texture2D g_TexB : register(t1); RWTexture2D<float4> g_Output : register(u0); [numthreads(16, 16, 1)] void CS( uint3 DTid : SV_DispatchThreadID ) { g_Output[DTid.xy] = g_TexA[DTid.xy] * g_TexB[DTid.xy]; }
c++代码如下:
class GameApp : public D3DApp { public:bool InitResource(); void Compute(); private: ComPtr<ID3D11ComputeShader> m_pTextureMul_R32G32B32A32_CS; ComPtr<ID3D11ShaderResourceView> m_pTextureInputA; ComPtr<ID3D11ShaderResourceView> m_pTextureInputB; ComPtr<ID3D11Texture2D> m_pTextureOutput; ComPtr<ID3D11UnorderedAccessView> m_pTextureOutput_UAV; }; // 初始化资源 bool GameApp::InitResource() { HR(CreateDDSTextureFromFile(m_pd3dDevice.Get(), L"..\\Texture\\flare.dds", nullptr, m_pTextureInputA.GetAddressOf())); // 内部会调用CreateShaderResourceView来创建贴图A的SRV视图 HR(CreateDDSTextureFromFile(m_pd3dDevice.Get(), L"..\\Texture\\flarealpha.dds", nullptr, m_pTextureInputB.GetAddressOf())); // 内部会调用CreateShaderResourceView来创建贴图B的SRV视图
// 创建用于UAV的纹理,必须是非压缩格式 D3D11_TEXTURE2D_DESC texDesc; texDesc.Width = 512; texDesc.Height = 512; texDesc.MipLevels = 1; texDesc.ArraySize = 1; texDesc.Format = DXGI_FORMAT_R32G32B32A32_FLOAT; texDesc.SampleDesc.Count = 1; texDesc.SampleDesc.Quality = 0; texDesc.Usage = D3D11_USAGE_DEFAULT; texDesc.BindFlags = D3D11_BIND_SHADER_RESOURCE | D3D11_BIND_UNORDERED_ACCESS; texDesc.CPUAccessFlags = 0; texDesc.MiscFlags = 0; HR(m_pd3dDevice->CreateTexture2D(&texDesc, nullptr, m_pTextureOutput.GetAddressOf())); // 创建无序访问视图 D3D11_UNORDERED_ACCESS_VIEW_DESC uavDesc; uavDesc.Format = DXGI_FORMAT_R32G32B32A32_FLOAT; uavDesc.ViewDimension = D3D11_UAV_DIMENSION_TEXTURE2D; uavDesc.Texture2D.MipSlice = 0; HR(m_pd3dDevice->CreateUnorderedAccessView(m_pTextureOutput.Get(), &uavDesc, m_pTextureOutput_UAV.GetAddressOf())); // 创建计算着色器 ComPtr<ID3DBlob> blob; HR(CreateShaderFromFile(L"HLSL\\TextureMul_R32G32B32A32_CS.cso", L"HLSL\\TextureMul_R32G32B32A32_CS.hlsl", "CS", "cs_5_0", blob.GetAddressOf())); HR(m_pd3dDevice->CreateComputeShader(blob->GetBufferPointer(), blob->GetBufferSize(), nullptr, m_pTextureMul_R32G32B32A32_CS.GetAddressOf()));// ******************
// 设置调试对象名 // D3D11SetDebugObjectName(m_pTextureOutput_UAV.Get(), "Output_R32G32B32A32"); D3D11SetDebugObjectName(m_pTextureMul_R32G32B32A32_CS.Get(), "TextureMul_R32G32B32A32_CS"); return true; } // 执行着色器计算 void GameApp::Compute() { assert(m_pd3dImmediateContext); //#if defined(DEBUG) | defined(_DEBUG) // ComPtr<IDXGraphicsAnalysis> graphicsAnalysis; // HR(DXGIGetDebugInterface1(0, __uuidof(graphicsAnalysis.Get()), reinterpret_cast<void**>(graphicsAnalysis.GetAddressOf()))); // graphicsAnalysis->BeginCapture(); //#endif m_pd3dImmediateContext->CSSetShaderResources(0, 1, m_pTextureInputA.GetAddressOf()); m_pd3dImmediateContext->CSSetShaderResources(1, 1, m_pTextureInputB.GetAddressOf()); // DXGI Format: DXGI_FORMAT_R32G32B32A32_FLOAT // Pixel Format: A32B32G32R32 m_pd3dImmediateContext->CSSetShader(m_pTextureMul_R32G32B32A32_CS.Get(), nullptr, 0); m_pd3dImmediateContext->CSSetUnorderedAccessViews(0, 1, m_pTextureOutput_UAV.GetAddressOf(), nullptr); m_pd3dImmediateContext->Dispatch(32, 32, 1); //#if defined(DEBUG) | defined(_DEBUG) // graphicsAnalysis->EndCapture(); //#endif HR(SaveDDSTextureToFile(m_pd3dImmediateContext.Get(), m_pTextureOutput.Get(), L"..\\Texture\\flareoutput.dds")); MessageBox(nullptr, L"请打开Texture文件夹观察输出文件flareoutput.dds", L"运行结束", MB_OK); }
注:由于位图是512x512x1大小,一个线程组的线程布局为16x16x1,线程组的数目自然就是32x32x1了。如果调度的线程组宽度或高度不够,输出的位图也不完全。
而如果提供了过宽或过高的线程组并不会影响运行结果,只是提供的线程组资源过多有些浪费而已。
参考
DirectX11 With Windows SDK--26 计算着色器:入门
DirectX11 With Windows SDK--29 计算着色器:内存模型、线程同步;实现顺序无关透明度(OIT)
DirectX11 With Windows SDK--27 计算着色器:双调排序


 浙公网安备 33010602011771号
浙公网安备 33010602011771号