UE4/UE5移动端延迟渲染
移动端延迟渲染的支持情况

① UE4.26不支持OpenGL ES,Vulkan和Metal使用4个input attachments
注:color attachment是在GPU上的渲染目标,即rendert arget(RT),新型图形的API像vulkan,metal中叫color attachment,存储渲染后的颜色缓冲(color buffer),对应的深度缓冲(depth buffer)则存储在depth attachment。
对于支持MRT的移动设备(实现延迟渲染),则有多个render targets,新型图形API中就是color attachments。
② UE4.27将input attachments降到了3个,可以支持更多的设备。
另外增加了更多功能:带光照的延迟贴花(Lit Deferred Decal)、Light Function、IES Light Profile、Glass Local Light,Glass Reflection
③ UE5.1支持了OpenGL ES,从而支持所有移动平台,可用于实际的项目开发
移动端延迟渲染的优势
与前向渲染比,延迟渲染的优势:
① BasePass(几何Pass)不需要光照计算,材质可以和光照解耦开,更少的shader变体(permutation) 注:shader变体多,会导致更新的patch很大,占用的内存很多

② BasePass(几何Pass)不需要光照计算,复杂情况下,可以省6-7个Sampler:
Reflection capture (1~2)
Shadow texture (1)
Planar reflection (1)
Light grid data (3)
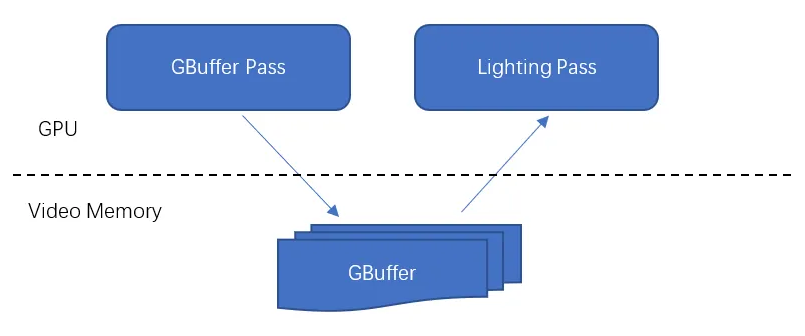
PC上延迟渲染
在PC上延迟渲染,GBuffer生成阶段和Lighting阶段之间通过video memory来传递数据
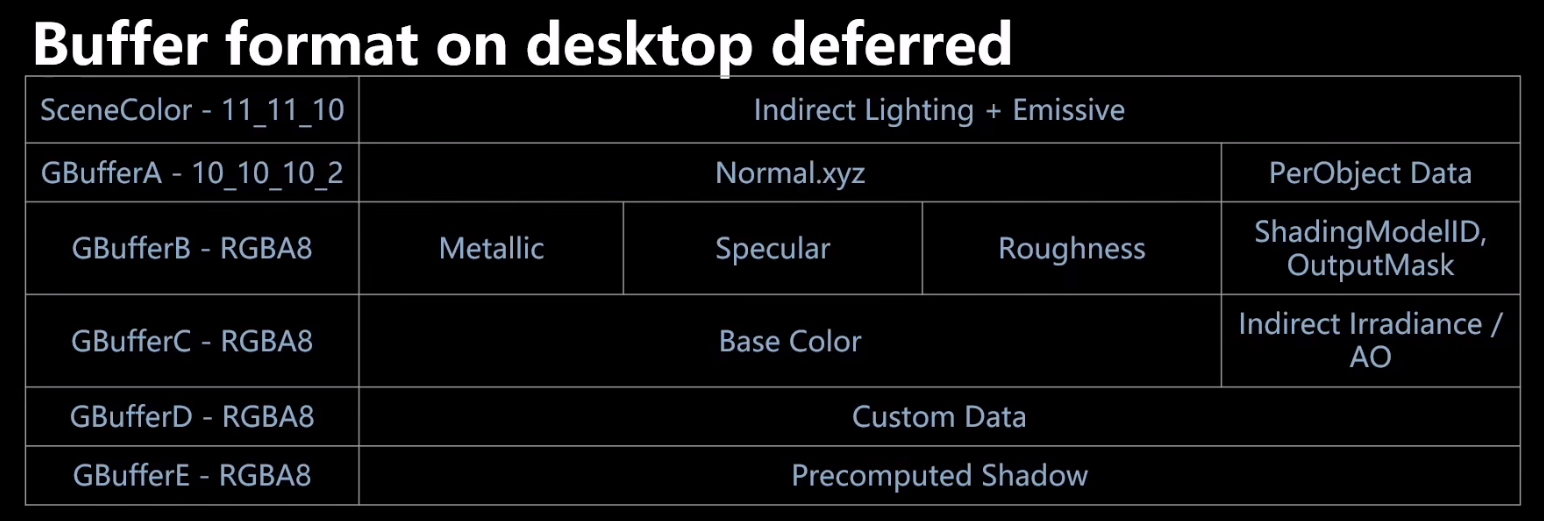
GBufferD存储是ShadingModel用到的Custom Data信息。GBufferE存储是烘培出来的ShadowMap的信息。
共6张RT,占192bits
移动端延迟渲染
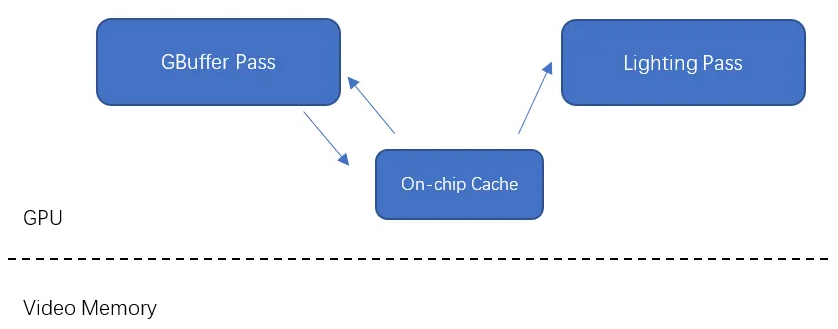
在移动端延迟渲染,为了省电,通过避免读写显存来节省带宽,GBuffer生成阶段和Lighting阶段之间直接通过on-chip cache来传递数据
注:当输出4张1080p * 1080p,32bpp(32 bits per pixel)RT的数据到Video Memory,在60fps的情况下,会带来1GB/s的写带宽
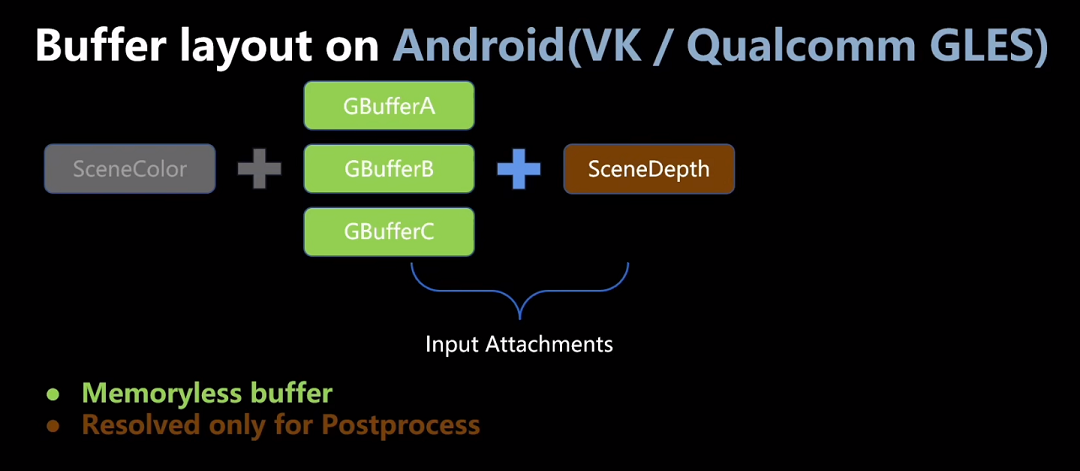
UE4.26/4.27中GBuffer结构

UE4移动端GBuffer的结构,共4张RT,共占128bits
为了存下这个信息,把法线从半球空间转到了八面体空间,留下的10bits来支持主方向光烘培出Precomputed Shadow
PerObject Data只有2bits,在移动端是没有使用的
SelectiveOutputMask在移动端也是没有使用的
与UE5.1相比,不支持pixel_local_storage,不支持shadingmodle(只支持DefaultLit),不支持spotlight shadow,不支持light channel
UE5.1中GBuffer结构

UE5.1移动端GBuffer的结构,共4张RT,共占128bits
① 法线还是压缩在2个通道中,无法利用硬件来混合,所以不支持延迟贴花的混合
② 10bits中,ShadingModeID用4bits,其他6bits用于存储ShadingModel用到的Custom Data信息
③ Precomputed Shadow和Indirect Irradiance各8bits,只在静态光照中使用;因此在关掉静态光照时,可以用来存储ShadingModel用到的Custom Data信息
④ 很多ShadingMode下,不使用Metallic信息,因此这8bits,也可以用来存储ShadingModel用到的Custom Data信息
关掉静态光照情况下,支持了所有的ShadingMode:
SHADINGMODELID_SUBSURFACE
SHADINGMODELID_PREINTEGRATED_SKIN
SHADINGMODELID_CLEAR_COAT
SHADINGMODELID_SUBSURFACE_PROFILE
SHADINGMODELID_HAIR
SHADINGMODELID_TWOSIDED_FOLIAGE
SHADINGMODELID_CLOTH
SHADINGMODELID_EYE
SHADINGMODELID_SINGLELAYERWATER
SHADINGMODELID_THIN_TRANSLUCENT
注1:SHADINGMODELID_SINGLELAYERWATER、SHADINGMODELID_THIN_TRANSLUCENT是半透明效果才用到,延迟渲染不用考虑它们了,它们是用前向渲染绘制的
注2:SHADINGMODELID_EYE比较特殊,还用到了SHADINGMODELID_SUBSURFACE_PROFILE,一共有5个custom data,打包在4个通道中,只能把2个custom data压缩到1个通道里
r.Mobile.AllowPerPixelShadingModels 用于控制移动端延迟渲染是否支持PerPixelShadingModel,如果支持的话,材质球里面可以有多个ShadingMode的效果,默认是打开的
r.Mobile.EnabledShadingModelsMask 用于控制移动端延迟渲染那些shadingmode是可以打开的,如果没有打开就会切到DefaultLit上,缺省是全部打开的
Defaultlit only with static lighting enabled 开启静态光照情况下,移动端延迟渲染只支持DefaultLit,不支持其他的ShadingMode
把GBuffer存放在On-chip Cache上的好处
① 避免读写显存来节省带宽
② 避免在Video Memory上创建屏幕大小的多张RT,节省内存
把GBuffer存放在On-chip Cache上的问题
① 无法在PostProcess后处理阶段访问GBuffer数据 注:这也是移动端延迟渲染不支持Screen Space Reflection的原因
② 由于GBuffer占用了On-chip Cache,因此抗锯齿不能用MSAA,会使用FXAA、TAA、FSR等抗锯齿
访问On-chip Cache
要实现on-chip cache来传递数据,就必须具备访问on-chip cache的能力,即:LightingPass阶段的fragment shader可以直接读取存储在on-chip cache上的GBuffer数据
OpenGL ES
Framebuffer Fetch
EXT_shader_framebuffer_fetch这个扩展支持MRT,然而提出ARM_shader_framebuffer_fetch、ARM_shader_framebuffer_fetch_depth_stencil扩展的ARM确不支持这个进化出来的通用的版本
首先要启用扩展,然后在lighting的shader里使用修饰符inout标记GBuffer的多张RT,比如:
layout(location=0) inout vec4 out_Target0; layout(location=1) inout vec4 out_Target1; layout(location=2) inout vec4 out_Target2;
局限:该扩展只支持Adreno、PowerVR的GPU,不支持Mali的GPU
Pixel Local Storage(PLS)
EXT_shader_pixel_local_storage这个扩展比EXT_shader_framebuffer_fetch强大之处在于,我们可以在on-chip cache上自定义结构体
另外,扩展要区分兼容MRT和不兼容MRT两个版本。不兼容MRT的版本只能绑定一张RT,那么就会导致GBuffer其他未绑定的RT无法resolve,
只能在当前pass内部作为临时数据使用,但幸运的是,这个结构体可以不和GBuffer的RT一一对应,所以在不兼容MRT的版本上依然可以实现“GBuffer RTs无法全部resolve的延迟渲染”
局限:此扩展不兼容MRT的版本只支持Mali系列GPU,兼容MRT的版本只支持PowerVR系列GPU
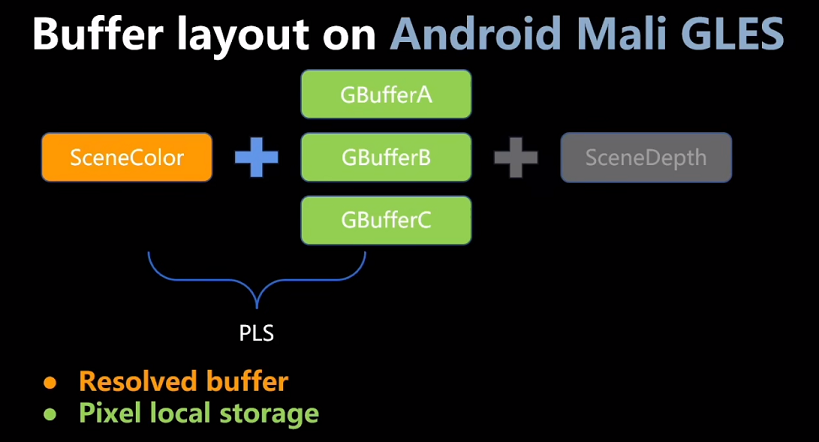
pixel_local_storage在Mali系列GPU上只有128bits(32bits x 4):1张32bits的SceneColor,3张32bits的GBuffer,不存储SceneDepth
在Mali系列GPU上
在PowerVR系列GPU上

GPU不支持Depth Buffer Fetch,只能使用MRT的FrameBuffer Fetch,只能新申请一张Memoryless的RenderTarget来存储Depth
Vulkan
Vulkan是专门为TBDR理念设计的,相对直观的提供了render pass,subpass机制。
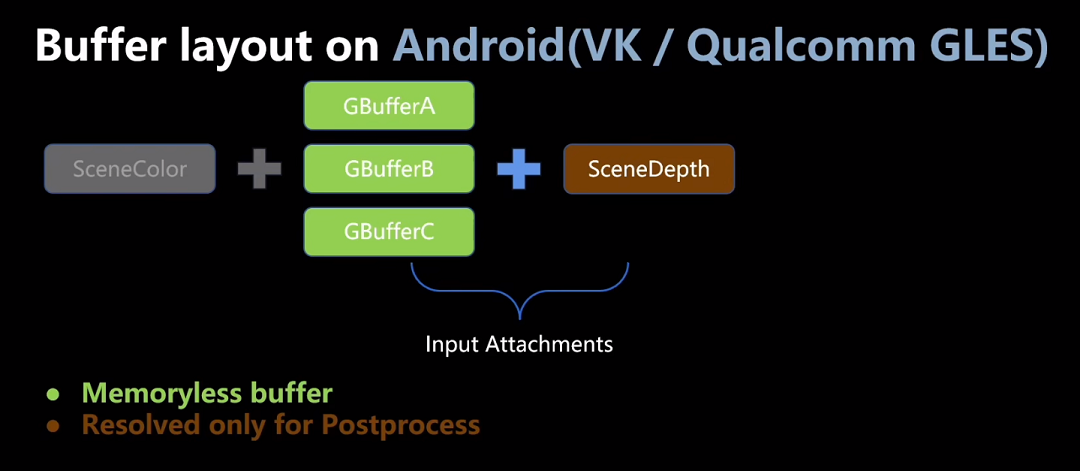
首先要把GBuffer和Lighing两个阶段设计成Vulkan中的同一个render pass的两个subpass。把GBuffer RTs作为第一个subpass的ColorAttachments,作为第二个subpass的InputAttachment。
然后Lighting阶段的shader正常读取InputAttachment即可。
局限:主流的GPU基本支持,但是subpass的InputAttachment最多能使用4个。 注:4个的设备占比16.3%,8个的设备占比83.7%
所以只能申请3张32bits的GBuffer
Metal
Metal的做法集成了EXT_shader_pixel_local_storage自定义结构体的灵活性和Vulkan基于TBDR的设计理念。
在Lighting阶段的shader内只需用color(n)即可访问对应的GBuffer的值。
局限:Metal 2.0提供了ImageBlock特性后才可以使用自定义结构体,1.0版本就没有这种灵活性。
GPU不支持Depth Buffer Fetch,只能使用MRT的FrameBuffer Fetch,只能新申请一张Memoryless的RenderTarget来存储Depth
对光照和阴影的支持情况

注1:Local light是分两次绘制的,第一次是在stencil里面标记灯光的区域,第二次是在这个区域里做像素着色
注2:Simple light是粒子创建出来的简单光源,通常是在clustered local lights阶段绘制的。如果没有开启clustered local lights,会有自己的pass,过程与local light pass类似。
Lighting Channel实现
在PC上是把Lighting Channel写到Stencil Buffer中,然后在shader中读取。这对移动设备比较困难,因为OpenGL ES不支持Texture View,所以ue5是在硬件上直接做Stencil Test的

注:一盏灯光只支持一个Lighting Channel,多个Lighting Channel会出错


 浙公网安备 33010602011771号
浙公网安备 33010602011771号