python - bilibili(四)抓包数据乱码
上一篇文章中不知道大家发现端倪木有,两张照片对比很明显发现第一张是信息很明显的,第二张是乱码的。
为什么会出现这种情况?细心的童鞋可能发现是我们发送给服务器的请求连接的数据不同:
第一张图的信息是{"roomid":98284,"uid":271298361556770}
第二张图的信息是{"uid":276194535568357,"protover":2,"roomid":98284}
roomid是真实的房间号,uid是随机生成的一串数字,可以直接复制登录。
相比而言,第二张多了个"protover":2参数。其实第一张图是抓取手机客户端的数据包,第二张图是抓取电脑网页数据包。所以有没有这个"protover":2这个参数都是可以连接到弹幕服务器的。
所以我们可以推断抓包的最容易抓的数据是手机端,其次是wap端,最后才是电脑端。


但是好多时候我们抓包数据的都是如图二所示的一串串乱码,不管你用utf8还是用gbk编码都达不到图一的那种效果。
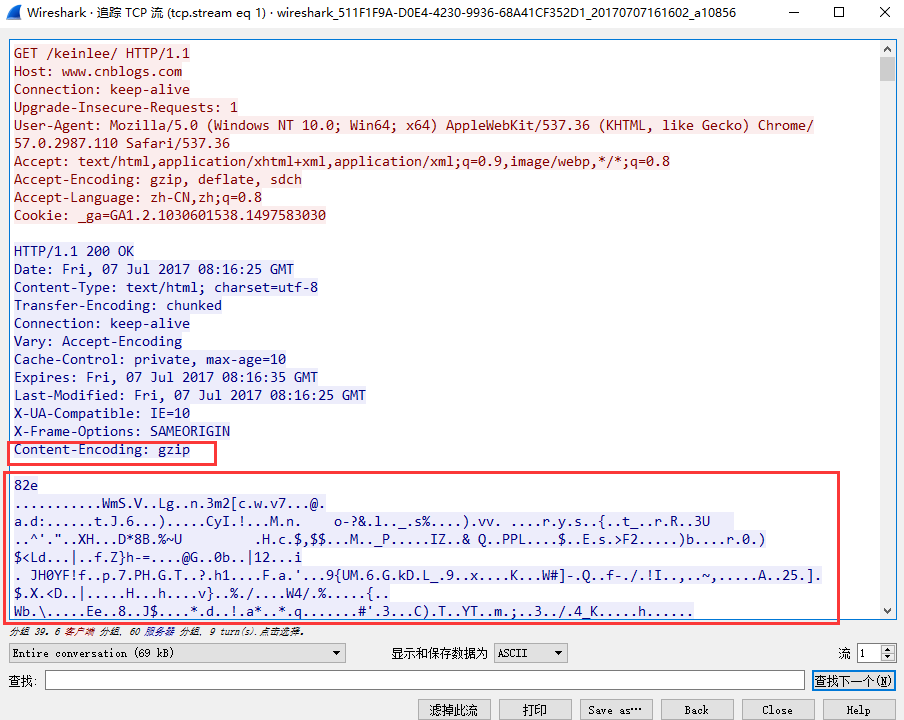
这种数据其实是一种压缩数据gzip,目前wireshark还不支持这种压缩数据的解压模式。
现在网站在传输中基本上都是用压缩模式进行传输的,所以你抓取到的数据是压缩后的数据,在你看来就是彻彻底底的乱码,无从下手。
如图所示,访问我的博客首页http://www.cnblogs.com/keinlee/,抓取服务器传送回来的网页数据是gzip模式,而我们平时访问的网页是经过浏览器解压数据并渲染然后呈现给我们。
既然分析哔哩哔哩服务器传送的是gzip数据,那么解决办法就很简单了,安装第三方zlib包或者gzip包都可以解决这个问题。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号