2_线性回归
AI地图
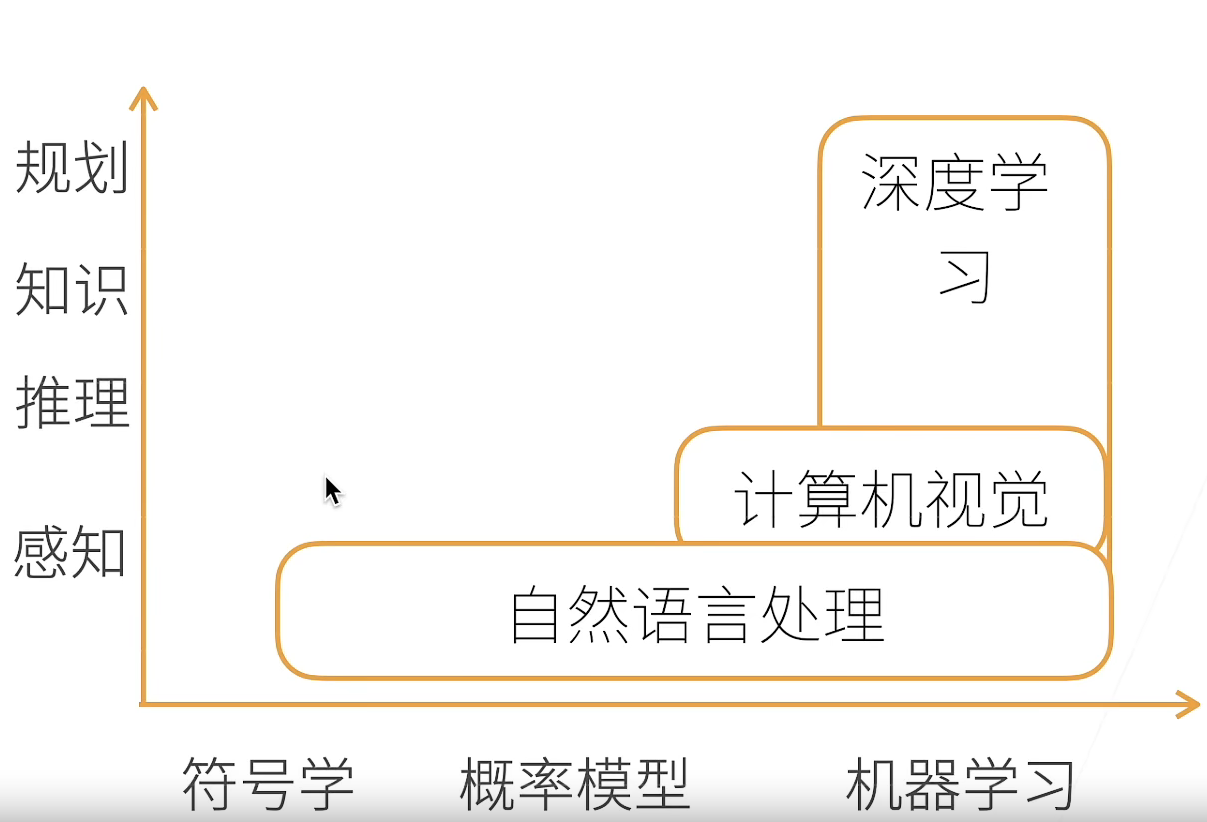
模型的可解释性
- 总的来说,我们的研究对于机器学习来说是有一些解释的,但是深度学习这一块还是没有太大研究
- 有效性和可解释性
- 有效性:我们能不能解释
- 可解释性:解释出来你能不能听懂(比如:模型在哪里会出现偏差)
线性回归
对loss.sum().backward()的理解:
.backward()的理解- 本质:当c.backward() 语句执行后,会自动对 c 表达式中 的可求导变量进行方向导数的求解,并将对每个变量的导数表达存储到 变量名.grad 中。
- 可如此理解 c.backward() = a.grad I + b.grad j(公式为c = a * b)
- 对
.sum()的理解- 观察下面一段代码
- 结合上面对backward的理解,我们对loss进行sum操作,不会改变loss的值,只是方便进行反向传播,所需要的梯度已经存储在x.grad中
import torch
x = torch.arange(4.0)
x.requires_grad_(True)
y = 2 * torch.dot(x, x)
y.backward()
x.grad
# 输出: tensor([ 0., 4., 8., 12.])
x.grad.zero_()
y = x.sum()
y.backward()
x.grad
# 输出: tensor([1., 1., 1., 1.])
x.grad.zero_()
y = x * x
# 等价于y.backward(torch.ones(len(x)))
y.sum().backward()
x.grad
#输出: tensor([0., 2., 4., 6.])
torch.utils.data.TensorDataset使用方法
- TensorDataset 可以用来对 tensor 进行打包,就好像 python 中的 zip 功能。
- 该类通过每一个 tensor 的第一个维度进行索引。因此,该类中的 tensor 第一维度必须相等.
- 另外:TensorDataset 中的参数必须是 tensor
##源码
class TensorDataset(Dataset):
r"""Dataset wrapping tensors.
Each sample will be retrieved by indexing tensors along the first dimension.
Arguments:
*tensors (Tensor): tensors that have the same size of the first dimension.
"""
'''数据集包装张量。
每个样本将通过沿第一维索引张量来检索。
参数:
*张量(张量):具有与第一维相同大小的张量。'''
def __init__(self, *tensors):
assert all(tensors[0].size(0) == tensor.size(0) for tensor in tensors)
self.tensors = tensors
def __getitem__(self, index):
return tuple(tensor[index] for tensor in self.tensors)
def __len__(self):
return self.tensors[0].size(0)
torch.utils.data.DataLoader使用方法
- dataset (Dataset) – 加载数据的数据集。
- batch_size (int, optional) – 每个batch加载多少个样本(默认: 1)。
- shuffle (bool, optional) – 设置为
True时会在每个epoch重新打乱数据(默认: False). - sampler (Sampler, optional) – 定义从数据集中提取样本的策略,即生成index的方式,可以顺序也可以乱序
- num_workers (int, optional) – 用多少个子进程加载数据。0表示数据将在主进程中加载(默认: 0)
- collate_fn (callable, optional) –将一个batch的数据和标签进行合并操作。
- pin_memory (bool, optional) –设置pin_memory=True,则意味着生成的Tensor数据最开始是属于内存中的锁页内存,这样将内存的Tensor转义到GPU的显存就会更快一些。
- drop_last (bool, optional) – 如果数据集大小不能被batch size整除,则设置为True后可删除最后一个不完整的batch。如果设为False并且数据集的大小不能被batch size整除,则最后一个batch将更小。(默认: False)
- timeout,是用来设置数据读取的超时时间的,但超过这个时间还没读取到数据的话就会报错
PyTorch源码解读之torch.utils.data.DataLoader
损失都需要平均吗
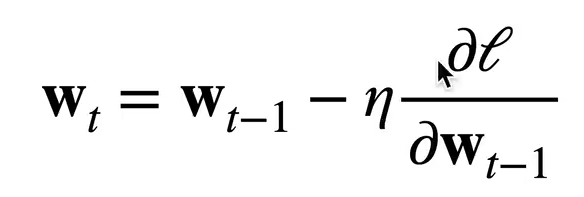
上图是梯度更新的公式,其中l是损失,如果说损失没有没有平均,那么就需要再学习率上除以样本大小,保证更新值保持在同一尺度。
为什么机器学习优化算法都采用梯度下降,而不采用牛顿法
梯度下降(一阶导算法) 牛顿法(二阶导算法、收敛速度更快)
- 二阶导并不是那么好算。比如一阶为100维的向量,那二阶导就是100 * 100的矩阵,计算的复杂性提升
- 我们在训练模型的时候首要考虑因素是达到近似最优解,其次再是收敛速度。
- 对于牛顿法而言,收敛速度确实快,不能容易陷入局部最优,最终效果不好

 浙公网安备 33010602011771号
浙公网安备 33010602011771号