【计算机组成原理】:存储系统学习(上)
一、程序的运行
冯诺依曼机的运行大致可分为两个步骤,存储程序和程序控制。具体而言,可分为以下步骤:
(1)输入设备将程序与数据写入内存;
(2)CPU取指令;
(3)CPU执行指令期间读数据;
(4)CPU写回运算结果;
(5)输出设备输出结果。
二、存储系统层次结构
由于CPU和主存的运行速度相差较大,程序运行的速度就会受制于内存的速度。于是,存储系统引入了高速缓存(Cache)。Cache的引入使得CPU访问到的存储系统具有Cache的速度,赋存的容量和价格。

同时,Cache又可以划分为L1 Cache和L2 Cache。其中L1 Cache集成在CPU中,分数据分数据Cache(D-Cache)和指令Cache(I-Cache)。早期L2 Cache在主板上或与CPU集成在同一电路板上。随着工艺的提高L2 Cache被集成在CPU内核中,不分D-Cache和I-Cache。

三、主存中的数据
数据存放在内存中,分为按边界存放和未按边界存放。
(1)按边界存放
按边界存放的方式,在32位系统中,存储单元为4个字节。int占4个字节,short占两个字节,double占8个字节,char占1个字节。会产生空间空余。

(2)未按边界存放
未按边界存放充分利用了空间,但是增加了内存的访问次数。如double类型的x,占了三个存储单元,需要访问三次。因此,这种方式虽然节省了空间,但增加了访问内存的次数。

四、主存中的数据组织
知道了数据在内存中的存放方式,具体到代码层面有什么影响呢?
如下两种结构体的写法:
struct S1{ int i; char c; int j } struct S2{ int i; int j char c; }
在边界对齐的情况下,这些数据在内存中的存储如下图所示。可以看到S1的结构体写法占了12个字节,S2的结构体占了9个字节。但就一个结构体的数据而言,代码的写法确实可以节省空间。

五、Cache的基本原理
Cache主要是用来解决CPU与慢速的主存之间的速度差异。Cache的工作原理分为读操作和写操作。
(1)读操作

如果Cache中已经有了该数据,就直接读入,这个过程称为命中(HIT)。如果Cache中没有这个数据,就会从内存中读取一个数据块缓存到Cache中,接着从Cache中读取到CPU,这个过程称为缺失(MISS)。缺失会造成访问速度急剧下降。
(2)写操作

写操作有两种策略,写穿策略(WriteThrough)和写回策略(WriteBack)。写穿策略是CPU向Cache中写数据后,将Cache中的数据写入到主存。写回策略是CPU向Cache中写数据后,不向主存写入数据。写回策略速度很快,但是数据的更新没有刷新到主存。
六、Cache的地址映射机制
主存地址通常按照块地址进行划分,Cache地址通常按照行进行划分,主存块大小和Cache中的行大小相等。主存地址通常划分为三个部分,Tag用来判断该数据是否在Cache中,Index用来找Cache中对于的数据位,块内偏移用来查找对应数据。Cache的结构如下图所示,Tag与主存Tag一致,Data用来存储一行数据,Valid表示Cache中的数据是否有效,Dirty表示主存中的数据是否是最新的。


主存与Cache地址映射通常有三种方式,全相联(fully-associated)、直接相联(direct mapped)和组相联(set-associated)。
(1)全映射
主存地址变成二维(块号 块内地址),如地址61,二进制是00111101,将它划分为两部分 001111和01,其中001111是块号,01是块内地址。全映射的映射算法是主存的数据库可以映射到Cache的任意行,同时将该数据块地址对应行的标记存储体中保存。

全映射的过程如上图所示,若CPU的访问序列顺序为1F 20 24 1E。首先,对于1F地址,二进制为0001 1111,划分为二维后tag=000111,offset=11即第四哥单元。首先回判断tag为000111是否命中,一开始是缺失的,因此添加tag为000111的单元,并把有效位置为1,同时从主存中读取一个数据块1C 1D 1E 1F到Cache中。其中偏移地址为11的1F即可访问。20和24的访问同理可得。当访问到1E的时候,tag为000111的单元已经存在,此时是命中的状态,可以直接去除偏移为10的数据。
可以看到,全相联的映射Cache率很高,主存可以映射到Cache任意位置。同时,块冲突率低,淘汰算法复杂。因此,全映射算法适用于小容量Cache。
(2)直接映射
直接映射将主存地址从一维变成三维(区号、区内块号、块内地址),如地址61二进制为00111101,划分为000011 11 01。直接映射的映射算法是,假设Cache有n行,主存第j块号映射到Cache的行号为i=j mod n ,即内存的数据块映射到Cache的特定行。

直接映射的过程如上图所示,若访问顺序为1F 20 24 1E 44。首先对于1F,地址划分为tag=0000,index=111,offset=11。因此,1F这个数据块只能映射到第7行。 如果某一行中,已经有了数据,且tag不一致,那么就会发生碰撞。这种情况下就会覆盖掉原来的数据。
直接映射的特点是Cache的利用率低,只能映射到特定行中。块冲突率高,淘汰算法简单,适用于大容量的Cache。
(3)组相联映射
组相连映射把地址从一维变成三维(组号、组内块号、块内地址)。如地址61划分为0000111 1 01。组内映射算法是Cache共n组,主存第j块号映射到Cache 的组号为: i=j mod n 即主存的数据块映射到Cache特定组的任意行。

组相联映射会把数据映射到对应组的任意行,接着根据tag进行判断是否命中,如果该组已经满了,就会发生碰撞。组相联映射相当于全相联映射和直接映射的折中。下图说明了组相联与其它两种方式的关系。若Cache有8行,当组相联数k=8时,组相联就变成了全相联。当k=1时,就变成了直接相联。

七、替换算法
当程序运行一段时间后,Cache存储空间被占满,当再有新数据要调入时,就需要通过某种机制决定替换的对象。因此,就需要替换算法。常见的替换算法有:先进先出法(FIFO,First in First out),最不经常使用法(LFU,Least Frequently Used),近期最少使用法(LRU,Least recently Used),随机替换法。
(1)先进先出法(FIFO)

先进先出法,顾名思义就是当需要替换时,先被访问的最先被替换。如上图,22载入添加一个标记0,后面没载入一次标记+1,依次载入到22 11 19 7,其中22命中一次。当载入16时,Cache已经满了。这时候需要采用先进先出的替换算法,其中22是最先被载入的,因此替换22。
(2)最不经常使用法(LFU)

最不经常使用法,就是优先替换掉命中次数最少的行,如果命中次数相同,可以搭配其它替换策略,如FIFO。如上图,当载入4时,22的次数为2,11的次数为1,19和16的次数为0。因此替换掉先进来的19。同理,当载入3时,优先替换掉次数少且先进来的16。
(3)近期最少使用法(LRU)

近期最少使用法,就是优先替换掉很长一段时间没有命中的单元。每次载入,如果命中则标记清0,否则标记+1。如上图所示,当载入16时,优先替换标记最大的11,载入4时,优先替换最大的22。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号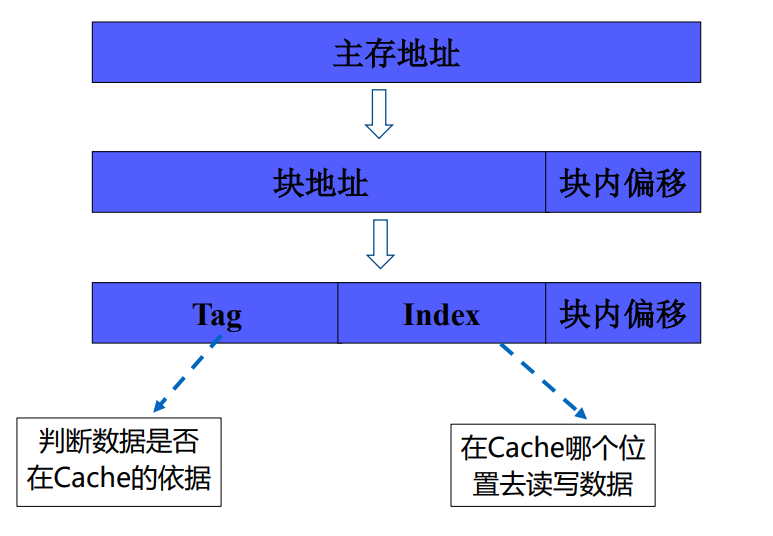{kind=link}