Hbase 永久 Region-In-Transition 的查错记录
状态:
部分 region 的状态为 FAILED_CLOSE,且一直停留在 RIT,不可服务。
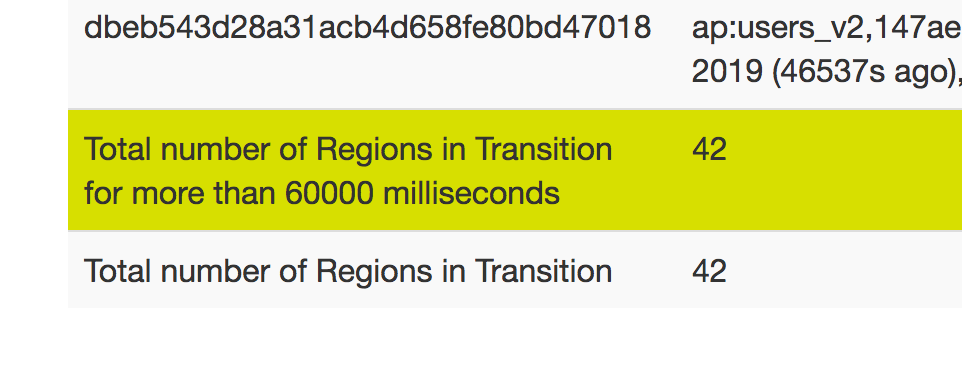
1. 首先,到 hbase region 上查日志(/var/log/hbase/),看到是 hdfs 文件的问题(参考 https://www.cnblogs.com/cenliang/p/8485011.html)
于是通过 HADOOP_USER_NAME=hdfs hdfs fsck /apps/hbase,发现部分文件缺少备份,运行以下命令设置备份,但始终不能完成所有文件的备份。
HADOOP_USER_NAME=hdfs hadoop fs -setrep -R 3 /apps/hbase
且 RIT 一直没有变化。
2. 继续研究日志,注意到另外一个高频的错误
2019-03-21 03:19:42,153 INFO [Thread-17726] hdfs.DFSClient: Exception in createBlockOutputStream
java.io.IOException: Got error, status message , ack with firstBadLink as 10.10.243.116:50010
at org.apache.hadoop.hdfs.protocol.datatransfer.DataTransferProtoUtil.checkBlockOpStatus(DataTransferProtoUtil.java:142)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.createBlockOutputStream(DFSOutputStream.java:1484)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.nextBlockOutputStream(DFSOutputStream.java:1386)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.run(DFSOutputStream.java:564)
3. 跳到 10.10.243.116 机器上看日志,发现以下错误持续存在
2019-03-20 08:11:28,060 ERROR datanode.DataNode (DataXceiver.java:run(278)) - ip-10-10-243-116.ec2.internal:50010:DataXceiver error processing WRITE_BLOCK operation src: /10.10.240.145:52666 dst: /10.10.243.116:50010
org.apache.hadoop.util.DiskChecker$DiskOutOfSpaceException: No more available volumes
at org.apache.hadoop.hdfs.server.datanode.fsdataset.RoundRobinVolumeChoosingPolicy.chooseVolume(RoundRobinVolumeChoosingPolicy.java:57)
at org.apache.hadoop.hdfs.server.datanode.fsdataset.impl.FsVolumeList.chooseVolume(FsVolumeList.java:80)
at org.apache.hadoop.hdfs.server.datanode.fsdataset.impl.FsVolumeList.getNextVolume(FsVolumeList.java:107)
at org.apache.hadoop.hdfs.server.datanode.fsdataset.impl.FsDatasetImpl.createTemporary(FsDatasetImpl.java:1580)
at org.apache.hadoop.hdfs.server.datanode.BlockReceiver.<init>(BlockReceiver.java:205)
at org.apache.hadoop.hdfs.server.datanode.DataXceiver.writeBlock(DataXceiver.java:687)
at org.apache.hadoop.hdfs.protocol.datatransfer.Receiver.opWriteBlock(Receiver.java:137)
at org.apache.hadoop.hdfs.protocol.datatransfer.Receiver.processOp(Receiver.java:74)
at org.apache.hadoop.hdfs.server.datanode.DataXceiver.run(DataXceiver.java:251)
at java.lang.Thread.run(Thread.java:748)
这个错误是没有找到硬盘,但通过 df -lh 看到,放数据的硬盘存在,应该是启动时的未知异常
Filesystem Size Used Avail Use% Mounted on devtmpfs 16G 56K 16G 1% /dev tmpfs 16G 24K 16G 1% /dev/shm /dev/nvme0n1p1 50G 16G 34G 33% / /dev/nvme1n1 2.9T 1.9T 893G 69% /hadoopfs/fs1
4. region server状态如下
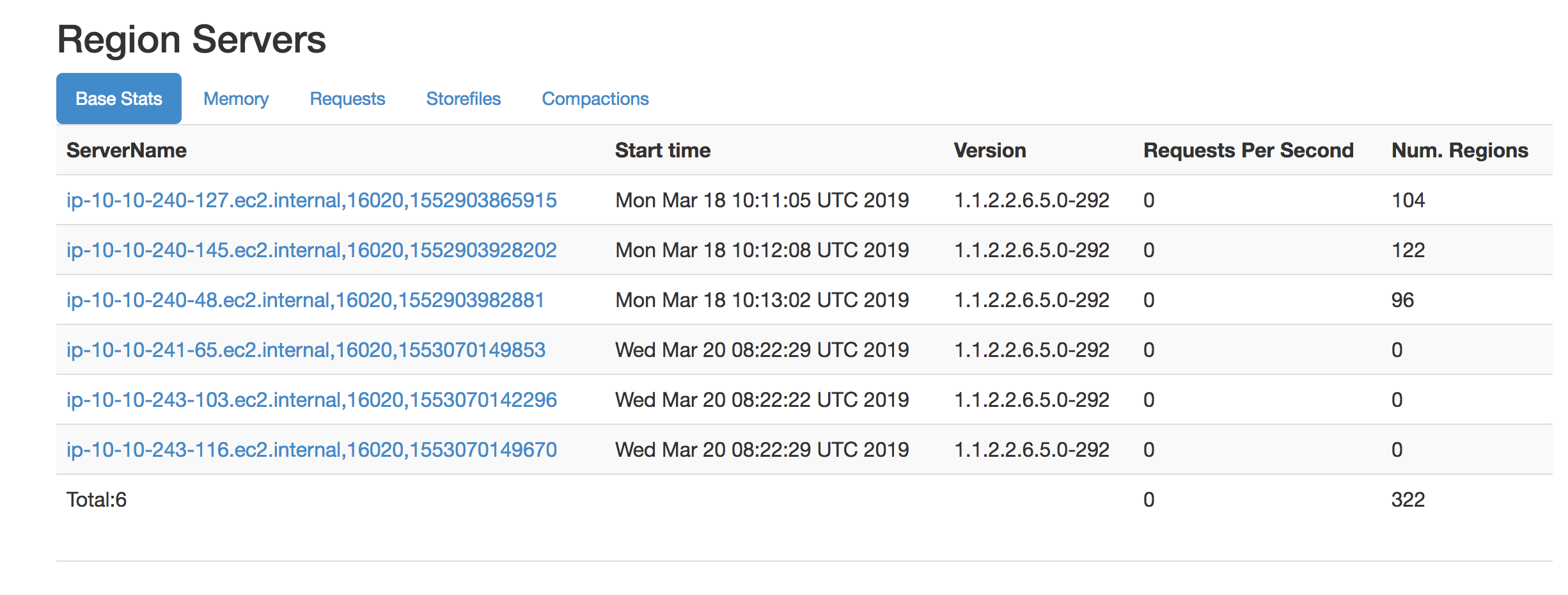
3台region server是最近重启的,没有 region 在上面,并且时间与 DiskOutOfSpaceException 出现的时间吻合,于是做以下推测。
===========================================================================================
1. 2019-03-20 08:11:28,060左右,先后重启了 data node 和 region server
2. 因为关闭了3台 region server,所有的 region 都迁移到活着的3台中(参见上图)
3. data node 启动了,但 10.10.243.116 状态不正常
4. region server 启动成功了,集群重新调整 region 的分布,即 unassign 部分 region server 上的region,assign 到刚启动的机器上
5. 此过程中,由于 data node 异常,这些 region 停留在 RIT,状态为 FAILED_CLOSE
注:region的状态机说明(http://hbasefly.com/2016/09/08/hbase-rit/)
解决方案:重启 data node
参考:
https://www.cnblogs.com/cenliang/p/8485011.html HBase 永久RIT(Region-In-Transition)问题
http://hbasefly.com/2016/09/08/hbase-rit/ region的状态机说明

 浙公网安备 33010602011771号
浙公网安备 33010602011771号