最小表示法&Manacher学习笔记+杂题
字符串系列
前言:
孩子从小就自卑。
四、最小表示法&Manacher学习笔记+杂题
相关题单:戳我
1.最小表示法
最小表示法是用于解决字符串最小表示问题的方法。
(1)字符串的最小表示:
字符串 \(s\) 的最小表示为与 \(s\) 循环同构的所有字符串中字典序最小的字符串。
循环同构指的是当字符串 \(s\) 与 \(t\) 中有一个位置i满足 \(s[i...n]+s[1...i-1]=t\) ,那么我们就称 \(s\) 与 \(t\) 循环同构。
(2)暴力做法:
枚举 \(s\) 的每一位为开头,找出其中字典序最小的一个,时间复杂度是 \(O(n^2)\)。
(3)算法过程:
其实是类似于双指针的做法,让两个箭头不断比较然后向后跳。
初始化指针 \(i\) 为0, \(j\) 为1;初始化匹配长度 \(k\) 为0。
比较第\(k\)位的大小,根据比较结果跳转相应指针,如果是\(i\)指针当前代表的字母值大,就跳\(i\),因为此时前面的都是一样的,这里 \(i\) 比 \(j\) 小,说明 \(j\) 开头更优, \(i\) 跳到 \(i+k+1\) ,前面 \(k\) 个都是一样的,那就不用再匹配了,反之同理。若跳转后两个指针相同(比如跳了之后 \(i,j\) 都是指向2,这是向后比较是没有意义的),则随意选一个加一以保证比较的两个字符串不同。如果当前 \(i,j\) 指向的字符相同,那么 \(k++\),代表前面的相同长度
重复上述过程,直到比较结束。
答案为 \(i,j\) 中较小的一个。
时间复杂度是 \(O(n)\) 的,几乎没有常数,非常的优秀。
(4)例题:
P1368 【模板】最小表示法P1368 【模板】最小表示法
洛谷上的模板题,给出一个数组,问你这个数组的最小表示法,只是将字符改成了数组,但操作都是一样的,注意的点标在代码上。
代码:
#include<iostream>
#include<cmath>
#include<cstring>
#include<algorithm>
#include<queue>
#include<cstdio>
#define int long long
using namespace std;
inline int max(int x,int y){return x>y?x:y;}
inline int min(int x,int y){return x>y?y:x;}
const int M=3e5+5;
int n,s[M];
signed main()
{
ios::sync_with_stdio(false);
cin.tie(0);cout.tie(0);
cin>>n;
for(int i=0;i<n;i++) cin>>s[i];//从下标为0的地方输入
int i=0,j=1,k=0;//将两个指针一个指向1,一个指向2。
while(i<n&&j<n&&k<n)//边界条件
{
int a=s[(i+k)%n],b=s[(j+k)%n];//直接对n取模,这也是为什么要从下标为0处输入
if(a==b) ++k;//累计前面相同长度
else
{
if(a>b) i=i+k+1;//i代表的大,就跳i
else j=j+k+1;
if(i==j) i++;//跳完之后两个的指向同一个就需要将任意一个向后移一位
k=0;//清空k
}
}
i=min(i,j);//答案是两个较小的那个,一般有一个都会跑到n外面去
for(int k=i;k<n;k++) cout<<s[k]<<" ";//输出i-k+0-i-1 这就是最小的表示法
for(int k=0;k<i;k++) cout<<s[k]<<" ";
return 0;
}
P1709 [USACO5.5] 隐藏口令 Hidden Password
同样是板子题,因为 \(O(n)\) 求最小表示法只是一种思想,转化的方法并不是很多,所以基本上都是板子题,而且也没几道最小表示法的题目。
口令其实就是最小表示法最后找的开头i。
代码:
#include<iostream>
#include<cmath>
#include<cstring>
#include<algorithm>
#include<queue>
#include<cstdio>
#define int long long
using namespace std;
inline int max(int x,int y){return x>y?x:y;}
inline int min(int x,int y){return x>y?y:x;}
const int M=5e6+5;
int n;
char s[M];
signed main()
{
ios::sync_with_stdio(false);
cin.tie(0);cout.tie(0);
cin>>n;
for(int i=0;i<n;i++) cin>>s[i];
int i=0,j=1,k=0;
while(i<n&&j<n&&k<n)
{
char a=s[(i+k)%n],b=s[(j+k)%n];
if(a==b) k++;
else
{
if(a>b) i=i+k+1;
else j=j+k+1;
if(i==j) i++;
k=0;
}
}//板子哒
i=min(i,j);//注意的是,最小表示法最后的答案是两个中较小的那个
cout<<i<<"\n";
return 0;
}
2.manacher
manacher算法又称为马拉车算法,应该是所有字符串的算法中最好理解的一个。manacher的作用就是找到一个字符串中所有的回文子串,相应的知道了所有的回文子串,也就相当于求出了最大的回文子串。所以manacher算法一般解决的是和字符串回文有关的题目。
(1)字符串的回文子串的解法:
朴素的暴力做法是对每个回文中心1从开始从小到大暴力枚举,如果全串都只有一个相同的字符全,时间复杂度就会被卡成 \(O(n^2)\) 。
其实回文子串作为一种非常特殊的性质具有多种解法,字符串哈希可以在 \(O(nlogn)\) 的时间解决,后缀数组和快速LCA(什么玩意)可以在 \(O(n)\) 的时间解决。
manacher的时间复杂度也是 \(O(n)\) ,但是manacher无论在思路,代码实现难度,常数上都比上面的几种解法好得多。
(2)回文串的性质
首先对于一个回文串,肯定都有唯一并确定的对称中心,这时候我们就需要分类讨论了,明显长度为奇数的回文串与长度为偶数的回文串对称中心是不同的的。(设字符串为 \(s\) , \(|s|\) 代表字符串的长度)
首先对于长度为奇数的回文串,对称中心是下标为 \(mid\) 的那个点( \(mid=|s+1|/2\) ),而对于长度为偶数的回文串,它的对称中心就是 \(mid\) 与 \(mid+1\) 之间的空隙(\(mid=|s|/2\))。
在算法中为了避免对奇偶分类讨论,尝试将所有偶回文子串转化为奇回文子串。可以将每一个空格都看作一个字符,在前后也都插上,那么字符串的长度就变成奇数了,例如对于字符串 abba,在其前后与每一个字符的间隔都插上一个字符,而为了避免插入的字符对答案造成影响,所以选择在字符串中没有出现过的字符,例如&,%,¥,#,@等,插入后原字符串就变成了#a#b#b#a#,长度就是奇数了。
再引入一个概念——回文半径,表示的是一个回文串的开头到对称中心的距离,那么我们可以发现对于插入字符后的字符串,它的回文串的回文半径减1就是原字符串的回文长度。还是以abba为例,这是一个回文串,长度为4,插入后#a#b#b#a#的长度为9,它的回文半径是5,减去1就是原本回文串的长度。
(3)算法过程
需要一个数组 \(R\) ,其中 \(R_i\) 代表以\(i\)为对称中心最大的回文半径,例如对于#a#b#b#a#(下标从1开始), \(a_5\) 就等于5(以其为对称中心获得的最长的回文串就是整个串了,长度为9,半径为5)。
首先将的所有字符之间插入相同分隔符,包括头尾,然后在整个字符串头尾插入另外两种不同的分隔符,以防止越界。
观察前面的朴素做法,思考如何优化,由于已经处理出来的对于每一个下标的最大回文半径其实对后面各个点计算最大的回文半径是有巨大的用途。
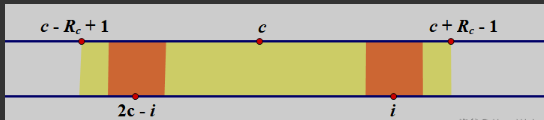
如图,我们在向后查找的时候,维护当前所有已经找过的点中,回文串最靠右的点的位置和与其对应的对称中心的下标,设这个最靠右的位置为 \(r\) ,对应的对称中心下标是 \(c\) 。最靠右的点自然就是 \(c+R_c-1\) ,现在我们要求 \(R_i\) 了,那么对于的 \(i\) 的大小分类讨论。
如果 \(i\) 的值大于 \(r\) ,那么 \(i=1\) 然后朴素的找最大的情况。
反之,此时由于回文串的性质,对称中心两边是相同的,那么 \(R_i\) 至少都等于 \(R_{2c-i}\) (两块橙色的区域是相同的)。但这种情况下是有特殊的,如果 \(r-i+1\) 小于了 \(R_{2c-i}\) ,也就是说超出 \(r\) 的边界了,那么我们就无法判断 \(R_i\) 的值了,这种情况下, \(R_i=min(r-i+1,R_{2c-i})\) 。然后朴素向两边延申。
每一次操作之后都判断一下当前的 \(i\) 与 \(R_i\) 是否可以更新 \(r\) 与 \(c\) ,可以更新就更新。
manacher最后求出来的具有用处的就是\(R\)数组,根据题目的要求进行操作。manacher的时间复杂度是 \(O(n)\) 的,因为每一次的朴素运算都会让 \(r\) 至少增加1,而 \(r\) 不递减。并且manacher的代码实现简单,常数也很小。
实现:
cin>>s+1;n=strlen(s+1);//s是原串,t是插入字符后的串
t[0]='!',t[1]='@';//将第0位插上不同的字符,避免越界RE
for(int i=1;i<=n;i++) t[++m]=s[i],t[++m]='@';//复制一个插入一个
t[++m]='%';//最后也插入一个不同的字符
for(int i=1,c=0,r=0;i<m;i++)//初始化,处理的区间实际上就是1-m-1,c与r一开始都为0
{
R[i]=i>r?1:min(r-i+1,R[2*c-i]);//分类讨论,i大于r就赋为1,否则就是两个中取min
while(t[i-R[i]]==t[i+R[i]]) R[i]++;//朴素的向两边延展
if(i+R[i]-1>r) r=i+R[i]-1,c=i;//更新r与c
}
(4)习题:
P3805 【模板】manacher
模板题是让我们找出一个字符串中的最长回文子串。
那么之前已经说过了,原串以 \(i\) 为对称中心的最长长度就是插入后的字符串的最长对称半径减1,也就是 \(R_i-1\) ,那么处理出来了 \(R\) 数组,这题就是个若质题。
代码:
#include<iostream>
#include<cmath>
#include<cstring>
#include<algorithm>
#include<queue>
#include<cstdio>
#define int long long
using namespace std;
inline int max(int x,int y){return x>y?x:y;}
inline int min(int x,int y){return x>y?y:x;}
const int M=3e7+5;
int n,m=1,ans=0,R[M];
char s[M],t[M];
signed main()
{
ios::sync_with_stdio(false);
cin.tie(0);cout.tie(0);
cin>>s+1;n=strlen(s+1);
t[0]='!',t[1]='@';
for(int i=1;i<=n;i++) t[++m]=s[i],t[++m]='@';
t[++m]='%';//处理t
for(int i=1,c=0,r=0;i<m;i++)
{
R[i]=i>r?1:min(r-i+1,R[2*c-i]);//分类讨论
while(t[i-R[i]]==t[i+R[i]]) R[i]++;
ans=max(ans,R[i]-1);//找出最大的回文子串的长度
if(i+R[i]-1>r) r=i+R[i]-1,c=i;//更新
}
cout<<ans<<"\n";
return 0;
}
P1723 高手过愚人节
上一道题的双倍经验,唯一的不同就是有多组询问,其实不需要咋处理,因为 \(R\) 数组是由字符串更新的,加一个多组询问就好。
代码:
#include<iostream>
#include<cmath>
#include<cstring>
#include<algorithm>
#include<queue>
#include<cstdio>
#define int long long
using namespace std;
inline int max(int x,int y){return x>y?x:y;}
inline int min(int x,int y){return x>y?y:x;}
const int M=2e7+5;
int n,m,q,ans;
int R[M];
char s[M],t[M];
signed main()
{
ios::sync_with_stdio(false);
cin.tie(0);cout.tie(0);
cin>>q;
while(q--)//多组询问
{
cin>>s+1,n=strlen(s+1),m=1,ans=0;//初始化m与ans
t[0]='!',t[1]='#';
for(int i=1;i<=n;i++) t[++m]=s[i],t[++m]='#';
t[++m]='$';
for(int i=1,c=0,r=0;i<m;i++)
{
R[i]=i>r?1:min(R[2*c-i],r-i+1);
while(t[i+R[i]]==t[i-R[i]]) ++R[i];
ans=max(ans,R[i]-1);
if(i+R[i]-1>r) r=i+R[i]-1,c=i;
}//板子
cout<<ans<<"\n";
}
return 0;
}
P1659 [国家集训队] 拉拉队排练
稍微麻烦了一点,其实就是利用\(R\)数组进行查找答案。首先还是用manacher处理好\(R\)数组。由于\(R_i\)代表的是以\(i\)为对称中心可以形成的最大的回文串的回文半径,所以 \((i-0,i+0)\) , \((i-1,i+1)\) , \((i-2,i+2)\) ...... \(i-R[i]+1,i+R[i]-1\) 都是回文串,那么我们就可以找出对于每一个固定的长度的回文串的个数。
但是不可能一个一个的从长度1一直加。那么对于这种区间加一的操作,我们可以使用差分,将 \(sum[1]++,sum[R[i]]--\) 就可以了(因为对应原串,长度实际上是 \(R_i-1\) ,而差分下标需要加1,所以就是 \(sum[R[i]]--\) ),处理完后做一遍前缀和,就得到每一个长度回文串出现的次数,最后统计一共有多少个,少于 \(k\) 就输出-1,否则再使用快速幂,统计答案。有些细节详见代码
代码:
#include<iostream>
#include<cmath>
#include<cstring>
#include<algorithm>
#include<queue>
#include<cstdio>
#define int long long
#define mod 19930726
using namespace std;
inline int max(int x,int y){return x>y?x:y;}
inline int min(int x,int y){return x>y?y:x;}
const int M=2e6+5;
int n,m=1,k;
int R[M],maxx,sum[M];
char s[M],t[M];
inline int quick(int x,int y)
{
int res=1;
while(y)
{
if(y&1)res=res*x%mod;
x=x*x%mod; y>>=1;
}
return res;
}
signed main()
{
ios::sync_with_stdio(false);
cin.tie(0);cout.tie(0);
cin>>n>>k;
cin>>s+1;
t[0]='!',t[1]='@';
for(int i=1;i<=n;i++) t[++m]=s[i],t[++m]='@';
t[++m]='%';
for(int i=1,r=0,c=0;i<m;i++)
{
R[i]=i>r?1:min(R[2*c-i],r-i+1);
while(t[i-R[i]]==t[i+R[i]]) R[i]++;
maxx=max(maxx,R[i]-1);//找出最长的回文串长度
if(i%2==0) sum[1]++,sum[R[i]]--;//t中下标为偶数的就是原字符
if(i+R[i]-1>r) r=i+R[i]-1,c=i;
}//其余都是板子
int res=0,ans=1;
for(int i=1;i<=maxx;i++)
{
sum[i]+=sum[i-1];//前缀和
if(i%2) res+=sum[i];//统计和,只统计长度为奇数的回文串
}
if(res<k)//不足就输出-1
{
cout<<"-1\n";return 0;
}
for(int i=maxx;i>=1;i--)
{
if(i%2==0) continue;
if(k>=sum[i]) ans=(ans*quick(i,sum[i]))%mod,k-=sum[i];//边乘边减k,使用快速幂会快一点
else
{
ans=(ans*quick(i,k))%mod;//k没啦
break;
}
}
cout<<ans%mod<<"\n";
return 0;
}
P4555 [国家集训队] 最长双回文串
输入长度为 \(n\) 的串 \(S\),求 \(S\) 的最长双回文子串 \(T\),即可将 \(T\) 分为两部分 \(X, Y\)(\(|X|,|Y|≥1\))使得 \(X\) 和 \(Y\) 都是回文串。
也是利用 \(R\) 数组进行操作的题目。我们可以建立两个数组 \(lx,rx\) 分别代表以下标 \(i\) 为左/右端点时,最长的回文子串。如果将这两个数组处理出来,最后我们就是只用枚举每一个下标,统计 \(lx_i+rx_i\) 的最大值。
知道了\(R_i\)我们就知道了这个回文串的边界,所以 \(lx[i-R[i]+1]=max(lx[i-R[i]+1], R[i]-1)\),\(rx[i+R[i]-1]=max(rx[i+R[i]-1], R[i]-1);\) 。然后对于相邻的节点,长度是会减2的,于是我们就处理出 \(lx,rx\) 两个数组了。
代码:
#include<iostream>
#include<cmath>
#include<cstring>
#include<algorithm>
#include<queue>
#include<cstdio>
#define int long long
using namespace std;
inline int max(int x,int y){return x>y?x:y;}
inline int min(int x,int y){return x>y?y:x;}
const int M=2e5+5;
int n,m=1,cnt=0;
int R[M],lx[M],rx[M];
char s[M],t[M];
signed main()
{
ios::sync_with_stdio(false);
cin.tie(0);cout.tie(0);
cin>>s+1;n=strlen(s+1);
t[0]='!',t[1]='@';
for(int i=1;i<=n;i++) t[++m]=s[i],t[++m]='@';
t[++m]='%';
for(int i=1,c=0,r=0;i<m;i++)
{
R[i]=i>r?1:min(R[2*c-i],r-i+1);
while(t[i-R[i]]==t[i+R[i]]) ++R[i];
if(i+R[i]-1>=r) r=i+R[i]-1,c=i;
lx[i-R[i]+1]=max(lx[i-R[i]+1], R[i]-1);
rx[i+R[i]-1]=max(rx[i+R[i]-1], R[i]-1);//当前点最远的边界,初始化lx,rx数组。
}
for(int i=m;i>=0;i-=2) rx[i]=max(rx[i],rx[i+2]-2);
for(int i=1;i<=m;i+=2) lx[i]=max(lx[i],lx[i-2]-2);//观察是否可以改变相邻的lx,rx值
int ans=0;
for(int i=1;i<=m;i+=2)
{
if(lx[i]&&rx[i]) ans=max(ans,rx[i]+lx[i]);//要两边都有回文子串,不然不符合题意
}
cout<<ans<<"\n";
return 0;
}
P9606 [CERC2019] ABB
我是用哈希水过去的,但是Manacher肯定是可以做的。详见
P6216 回文匹配
需要一点kmp的基础,首先使用kmp把所有 \(s_2\) 的出现位置记录下来,将每一个 \(s_2\) 出现的左端点打上标记。经,然后使用Manacher找出所有的回文串,得到 \(R\) 数组然后就可以做了(可能需要一点小技巧,比如二维前缀和)。
代码:
#include<iostream>
#include<cmath>
#include<cstring>
#include<algorithm>
#include<queue>
#include<cstdio>
#define int unsigned int
using namespace std;
inline int max(int x,int y){return x>y?x:y;}
inline int min(int x,int y){return x>y?y:x;}
const int M=3e6+5;
int n,m;
int ne[M],sum[M];
inline void kmp(string s,int n)
{
for(int i=2,j=0;i<=n;i++)
{
while(j&&s[i]!=s[j+1]) j=ne[j];
if(s[i]==s[j+1]) j++;
ne[i]=j;
}
}
inline void find(string s,int n,string t,int m)
{
for(int i=1,j=0;i<=n;i++)
{
while(j&&s[i]!=t[j+1])j=ne[j];
if(s[i]==t[j+1]) j++;
if(j==m)
{
sum[i-j+1]=1;
j=ne[j];
}
}
}
int p[M];
inline void manacher(string s,int n)
{
s.push_back('@');
for(int i=1,mid=0,r=0;i<=n;i++)
{
if(i<=r) p[i]=min(p[2*mid-i],r-i+1);
while(s[i-p[i]]==s[i+p[i]]) p[i]++;
if(i+p[i]-1>r) mid=i,r=i+p[i]-1;
}
}
signed main()
{
cin>>n>>m;
string s1,s2;
cin>>s1>>s2;
s1=' '+s1,s2=' '+s2;
kmp(s2,m);
find(s1,n,s2,m);
for(int i=1;i<=n;i++) sum[i]+=sum[i-1];
for(int i=1;i<=n;i++) sum[i]+=sum[i-1];
manacher(s1,n);
int ans=0;
for(int i=1;i<=n;i++)
{
if(2*p[i]-1<m) continue;
int r=i+p[i]-1,l=i-p[i]+1;
l--,r=r-m+1;
int mid=(l+r)/2;
ans+=sum[r]-sum[mid]-sum[((l+r)&1)?mid:mid-1]+sum[l==0?l:l-1];
}
cout<<ans<<"\n";
return 0;
}
P5446 [THUPC2018] 绿绿和串串
我觉得是一道非常神奇的题,需要自己手推样例发现性质:一个字符串的最长翻转子串就是它自己去掉最短末尾回文串的一半,在 Manacher 求出了每一个回文串的基础上,我们从后面往前面找每个最长翻转子串。我们使用manacher算法之后从末尾向前扫一遍,因为最长的肯定是从末尾开始的,如果能一次翻转成 或者能翻转成某个最长翻转子串并且没有越界,这样的位置就是符合要求的,打上标记后,最后输出。
代码:
#include<iostream>
#include<cmath>
#include<cstring>
#include<algorithm>
#include<queue>
#include<cstdio>
using namespace std;
inline int max(int x,int y){return x>y?x:y;}
inline int min(int x,int y){return x>y?y:x;}
const int M=2e6+5;
int n,m,q,ans;
char s[M],t[M];
int R[M],vis[M];
signed main()
{
cin>>q;
while(q--)
{
cin>>s+1;n=strlen(s+1);
t[0]='!',t[1]='@',ans=0,m=1;
for(int i=1;i<=n;i++) t[++m]=s[i],t[++m]='@';
t[m+1]='%';
for(int i=1,c=0,r=0;i<=m;++i)
{
R[i]=i>r?1:min(r-i+1,R[2*c-i]);
while(t[i-R[i]]==t[i+R[i]]) R[i]++;
if(i+R[i]-1>=r) r=i+R[i]-1,c=i;
}
for(int i=m;i>=1;--i)
{
if(i+R[i]-1==m) vis[i]=1;//一次可以反转成
else if(vis[i+R[i]-2]&&i==R[i]) vis[i]=1;//可以翻转成其他最长翻转子串
}
for(int i=1;i<=m;++i)
{
if(t[i]>='a'&&t[i]<='z'&&vis[i]) cout<<i/2<<" ";
vis[i]=0;
}
cout<<endl;
}
return 0;
}
P4287 [SHOI2011] 双倍回文
这道题被神犇用乱搞做法做过去了,具体做法是考虑所有 \(O(n)\) 个本质不同的回文串,对每个回文串都可以 \(O(1)\) 判断。只需要在manacher中r更新时,判断所有新出现的回文串的前一半是否为回文串即可。
代码:
#include<iostream>
#include<cmath>
#include<cstring>
#include<algorithm>
#include<queue>
#include<cstdio>
#define int long long
using namespace std;
inline int max(int x,int y){return x>y?x:y;}
inline int min(int x,int y){return x>y?y:x;}
const int M=1e6+5;
int n,m,ans;
int R[M];
char s[M],t[M];
signed main()
{
cin>>n;cin>>s+1;
t[1]='#';m=2*n+1;
for(int i=n;i;i--) t[i*2+1]='#',t[i*2]=s[i];
for(int i=1,c=0,r=0;i<=m;i++)
{
R[i]=i>r?1:min(R[2*c-i],r-i+1);
while(t[i-R[i]]==t[i+R[i]]) ++R[i];
if(i+R[i]-1>=r)
{
if(i&1)
{
for(int j=max(r,i+4);j<i+R[i];j++)
{
if(!(j-i&3)&&R[i-(j-i)/2]>(j-i)/2) ans=max(ans,j-i);
}
}
r=i+R[i]-1,c=i;
}
}
cout<<ans<<"\n";
return 0;
}
CF17E Palisection
这题是非常好的一道锻炼回文串的题。给定一个长度为 \(n\) 的小写字母串。问你有多少对相交的回文子串(其中包含也算相交),乍一看上去似乎还是比较简单的,但是\(R\)数组只是告诉我们每个点可以向两周延申多远,要判断相交的话似乎有一点麻烦。
但是真难则反,我们可以用所有回文串都相交在一起减去不相交的回文串。所有的回文串很好求,将所有的 \(R_i\) 加上后除以2,就是这个字符串子串所有回文串的数量,设为 \(sum\) ,那么我们先假设两两相交,那么一开始答案就是 \(sum*(sum-1)/2\) ,然后我们还需要减去不相交的两部分。
我们可以通过 \(R\) 数组处理出两个数组 \(f\) 与 \(g\) ,其中 \(f_i,g_i\) 分别代表以 \(i\) 为左/右端点的回文串的数量。这个也比较好处理(上面好像有道题和这个的处理方法类似),对于每一个 \(R_i\) ,它就代表了从 \(i-R_i+1\) 到 \(i\) 这中间每个点都是一个回文串的开头,同样的 \(i\) 到 \(i+R_i-1\) 都是每一个回文串的结尾,那么我们就可以使用差分区间修改 \(f[i-R[i]+1]++,f[i+1]--; g[i]++,g[i+R[i]]--;\) ,最后做一遍前缀和。
那么处理好了 \(f\) 与 \(g\) 数组,剩下的就是找出不相交的回文串的数量。可以发现以 \(i\) 结尾的回文串与以 \(i+1\) 开头的回文串不相交,所以我们就可以对于每一个点,找出再次之前就已经结束的回文串数量与再次之后才开始的回文串数量。拿总数区间就可以了,还需要注意的是由于答案可能很大,需要取模,注意边操作边取模。
代码:
#include<iostream>
#include<cmath>
#include<cstring>
#include<algorithm>
#include<queue>
#include<cstdio>
#define int long long
using namespace std;
inline int max(int x,int y){return x>y?x:y;}
inline int min(int x,int y){return x>y?y:x;}
const int M=4e6+6,mod=51123987;
int n,m=1;
char t[M],s[M];
int R[M],f[M],g[M];
signed main()
{
ios::sync_with_stdio(false);
cin.tie(0);cout.tie(0);
cin>>n;
cin>>s+1;
t[0]='!',t[1]='@';
for(int i=1;i<=n;i++) t[++m]=s[i],t[++m]='@';
t[++m]='%';
int ans=0,sum=0;
for(int i=1,c=0,r=0;i<m;i++)
{
R[i]=i>r?1:min(R[2*c-i],r-i+1);
while(t[i-R[i]]==t[i+R[i]]) ++R[i];
if(i+R[i]-1>=r) r=i+R[i]-1,c=i;
sum=(sum+R[i]/2)%mod;//统计回文串的总个数
}
for(int i=1;i<m;i++)
{
f[i-R[i]+1]++,f[i+1]--;
g[i]++,g[i+R[i]]--;//利用R数组找出以某个点开始/结尾的字符串的数量,区间修改使用差分
}
for(int i=1;i<m;i++) f[i]+=f[i-1],g[i]+=g[i-1];//前缀和
ans=(sum*(sum-1)/2)%mod,sum=0; //初始化总量ans
for(int i=2;i<m-2;i+=2)
{
sum=(sum+g[i])%mod;//此时的sum代表在i之前的已经结束的回文串的数量
ans=((ans-sum*f[i+2])%mod+mod)%mod;//i+2是因为我们插入了字符,这时候我们只看原串,所以for也是两个两个的跳,注意取模
}
cout<<ans<<"\n";
return 0;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号