

R数据预处理(一)
一、相关统计量
mean平均值
> mean(c(2,3,4,5,6,7)) [1] 4.5
> cardata mpg cyl disp hp drat wt qsec Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 Datsun 710 22.8 4 108 93 3.85 2.320 18.61 Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 Valiant 18.1 6 225 105 2.76 3.460 20.22
> apply(cardata,1,mean)#按行求均值 Mazda RX4 Mazda RX4 Wag Datsun 710 Hornet 4 Drive 45.71143 45.82786 36.08286 60.16214 Hornet Sportabout Valiant 83.61571 54.36286
> apply(cardata,2,mean)#按列统计 mpg cyl disp hp drat wt qsec 20.500000 6.000000 211.833333 117.166667 3.440000 2.988333 18.128333
忽略NA求均值
> x<-c(2,3,4,5,6,7,NA) > mean(x) [1] NA > mean(x,na.rm=TRUE) [1] 4.5
median中位数:粗略统计可使用中位数,如果异常值没有经过处理会影响到均值,而中位数一般在均值附近,因此若在对未经过数据处理的数据进行粗略统计时使用中位数的效果可能会比均值好
> median(c(2,3,4,5,6,NA),na.rm = TRUE)#删除向量中的缺失值 [1] 4 > median(c(2,3,4,5,6,NA),na.rm = FALSE)#若含有缺失值而不删除则会出现NA [1] NA
Mode众数:一组数据中出现次数最多的值,可同时作用于数字和字符数据
R没有内置函数计算众数,接下来定义一个函数来计算众数
> x<-c(12,7,3,4.2,18,2,54,-21,8,-5) > unique(x) #查看向量中的元素 [1] 12.0 7.0 3.0 4.2 18.0 2.0 54.0 -21.0 8.0 -5.0
> v<-c(2,1,2,3,1,2,3,4,1,5,5,3,2,3)
> table(v)
v
1 2 3 4 5
3 4 4 1 2
函数主体
> getmode <- function(x) {
+ t <- table(x)
+ if (sum(t == max(t)) == length(unique(x))) {#如果个数等于去重后的个数
+ print('没众数!')
+ }
+ else {
+ names(t)[t == max(t)]
+ }
+ }
> getmode(x)#测试
[1] "没众数!"
> getmode(v)
[1] "2" "3"
众数还能在字符上使用
二、统计函数
> head(sim.dat)#默认显示前6行数据,可指定显示行数head(sim.dat,n=3),对应的有tail显示尾部 > str(sim.dat)#显示数据类型,字符型主动变为factor,当然可指定不变sim.dat<-read.table("SegData2.TXT",header = TRUE,stringsAsFactors = F)
> str(sim.dat) 'data.frame': 6 obs. of 19 variables: $ age : int 57 63 59 60 51 59 $ gender : Factor w/ 2 levels "Female","Male": 1 1 2 2 2 2 $ income : num 120963 122008 114202 113616 124253 ... $ house : Factor w/ 1 level "Yes": 1 1 1 1 1 1 $ store_exp : num 529 478 491 348 380 ... $ online_exp : num 304 110 279 142 112 ... $ store_trans : int 2 4 7 10 4 4 $ online_trans: int 2 2 2 2 4 5 $ Q1 : int 4 4 5 5 4 4 $ Q2 : int 2 1 2 2 1 2 $ Q3 : int 1 1 1 1 1 1 $ Q4 : int 2 2 2 3 3 2 $ Q5 : int 1 1 1 1 1 1 $ Q6 : int 4 4 4 4 4 4 $ Q7 : int 1 1 1 1 1 1 $ Q8 : int 4 4 4 4 4 4 $ Q9 : int 2 1 1 2 2 1 $ Q10 : int 4 4 4 4 4 4 $ segment : Factor w/ 1 level "Price": 1 1 1 1 1 1
> summary(sim.dat) 主要统计量,每个变量的最大值最小值,均值,中位数,分位数
> summary(sim.dat) age gender income house store_exp online_exp Min. :51.00 Female:2 Min. :107661 Yes:6 Min. :338.3 Min. :109.5 1st Qu.:57.50 Male :4 1st Qu.:113763 1st Qu.:355.8 1st Qu.:119.6 Median :59.00 Median :117583 Median :428.8 Median :168.7 Mean :58.17 Mean :117117 Mean :427.3 Mean :190.3 3rd Qu.:59.75 3rd Qu.:121747 3rd Qu.:487.6 3rd Qu.:258.4 Max. :63.00 Max. :124253 Max. :529.1 Max. :303.5
> install.packages("psych") > library(psych) > describe(sim.dat)【带*号不用看,默认把原来的因子向量的处理为数值型,不具意义】显示更详细的信息
# vars n mean sd median trimmed mad min max range age 1 6 58.17 4.02 59.00 58.17 2.22 51.00 63.00 12.00 gender* 2 6 1.67 0.52 2.00 1.67 0.00 1.00 2.00 1.00 income 3 6 117117.36 6321.25 117582.85 117117.36 6220.82 107661.46 124252.55 16591.10 house* 4 6 1.00 0.00 1.00 1.00 0.00 1.00 1.00 0.00 store_exp 5 6 427.28 81.83 428.82 427.28 106.01 338.32 529.13 190.82 online_exp 6 6 190.31 84.55 168.68 190.31 85.69 109.53 303.51 193.98 store_trans 7 6 5.17 2.86 4.00 5.17 1.48 2.00 10.00 8.00 online_trans 8 6 2.83 1.33 2.00 2.83 0.00 2.00 5.00 3.00
也可以直接排除factor列直接看非factor列
> describe(sim.dat[, !unlist(lapply(sim.dat, is.factor))]) vars n mean sd median trimmed mad min max range age 1 6 58.17 4.02 59.00 58.17 2.22 51.00 63.00 12.00 income 2 6 117117.36 6321.25 117582.85 117117.36 6220.82 107661.46 124252.55 16591.10 store_exp 3 6 427.28 81.83 428.82 427.28 106.01 338.32 529.13 190.82 online_exp 4 6 190.31 84.55 168.68 190.31 85.69 109.53 303.51 193.98 store_trans 5 6 5.17 2.86 4.00 5.17 1.48 2.00 10.00 8.00 online_trans 6 6 2.83 1.33 2.00 2.83 0.00 2.00 5.00 3.00
三、举个例子
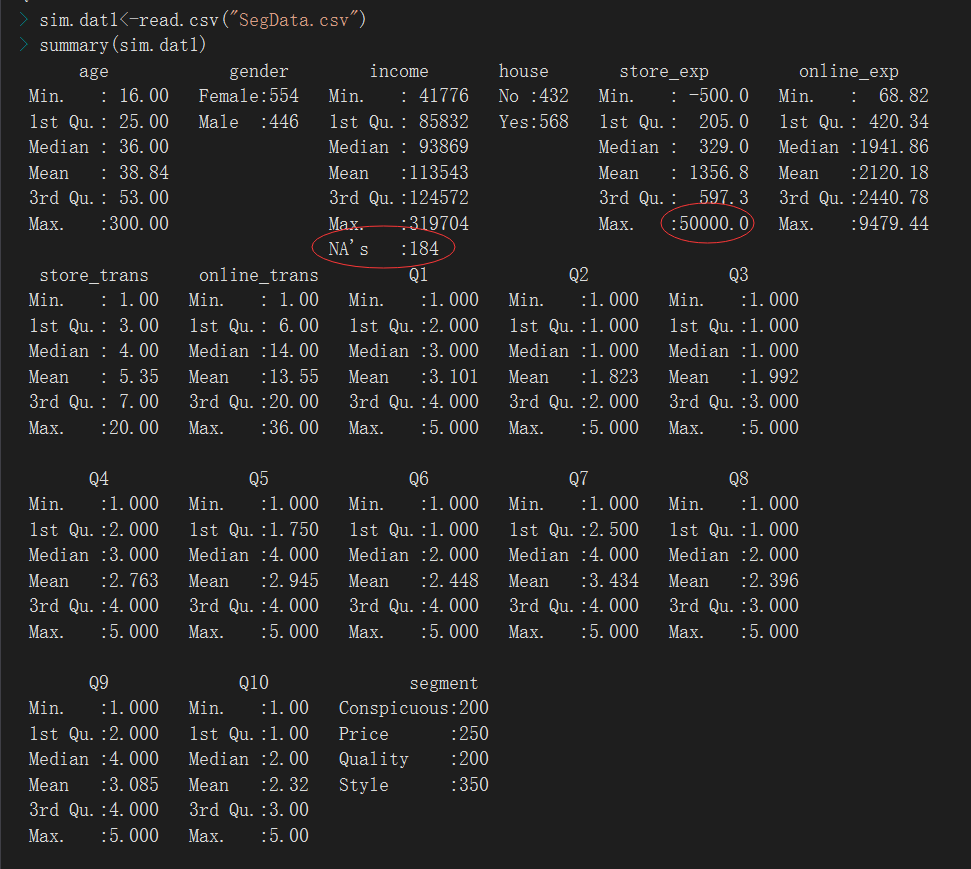
异常数据:
1、年龄最高300
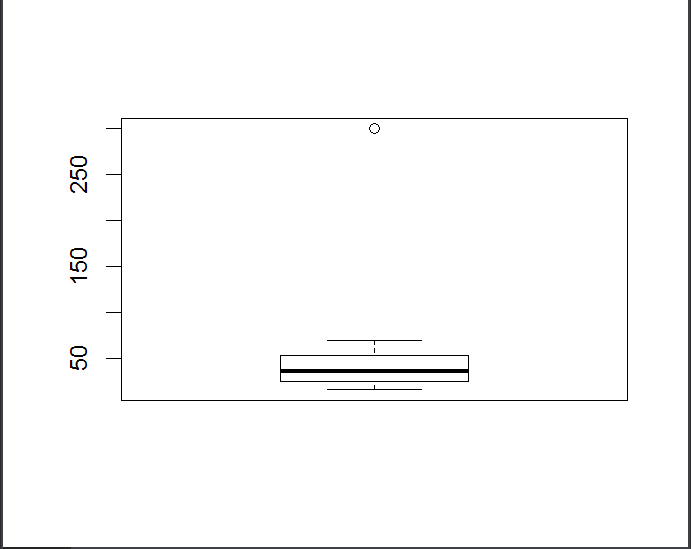
> sim.dat1$age[sim.dat1$age>=100]#找出年龄大于100岁的, [1] 300 > sim.dat1$age[sim.dat1$age>=100]<-NA#将其赋值为异常 > sim.dat1$age[sim.dat1$age>=100] [1] NA > summary(sim.dat1$age) Min. 1st Qu. Median Mean 3rd Qu. Max. NA's 16.00 25.00 36.00 38.58 53.00 69.00 1
2、零售店消费存在异常:-500、50000,都属于异常
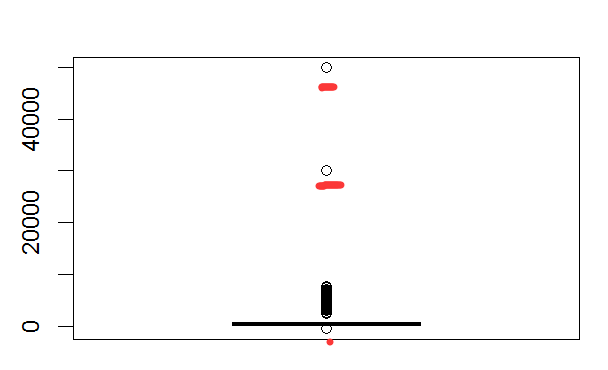
> summary(sim.dat1$store_exp) Min. 1st Qu. Median Mean 3rd Qu. Max. -500.0 205.0 329.0 1357.0 597.3 50000.0
假设以75%分位数597.3为合理最大值,则可以把大于这个数的所有值赋值为它
sim.dat1$store_exp[sim.dat1$store_exp>597.3]<-597.3
小于0的花费处理为缺失
> sim.dat1$store_exp[sim.dat1$store_exp<0]<-NA
缺失值处理:
填补缺失:随机缺失一般使用中位数、均值、众数;人为缺失-有效数据、哑变量
方法一:中位数填补
> median(sim.dat1$age,na.rm=T) [1] 36 > sim.dat1$age[is.na(sim.dat1$age)]<-36
> summary(sim.dat1$age)#查看一下,已无缺失,也无明显异常值 Min. 1st Qu. Median Mean 3rd Qu. Max. 16.00 25.00 36.00 38.58 53.00 69.00
> install.packages('caret') > library(caret) > medianImpute<-preProcess(sim.dat1, method = 'medianImpute')#中位数填充 > sim.dat1<-predict(medianImpute,sim.dat1) > summary(sim.dat1) age gender income house store_exp online_exp Min. :16.00 Female:554 Min. : 41776 No :432 Min. :155.8 Min. : 68.82 1st Qu.:25.00 Male :446 1st Qu.: 87896 Yes:568 1st Qu.:205.1 1st Qu.: 420.34 Median :36.00 Median : 93869 Median :329.8 Median :1941.86 Mean :38.58 Mean :109923 Mean :373.1 Mean :2120.18 3rd Qu.:53.00 3rd Qu.:119456 3rd Qu.:597.2 3rd Qu.:2440.78 Max. :69.00 Max. :319704 Max. :597.3 Max. :9479.44 store_trans online_trans Q1 Q2 Q3 Min. : 1.00 Min. : 1.00 Min. :1.000 Min. :1.000 Min. :1.000 1st Qu.: 3.00 1st Qu.: 6.00 1st Qu.:2.000 1st Qu.:1.000 1st Qu.:1.000 Median : 4.00 Median :14.00 Median :3.000 Median :1.000 Median :1.000 Mean : 5.35 Mean :13.55 Mean :3.101 Mean :1.823 Mean :1.992 3rd Qu.: 7.00 3rd Qu.:20.00 3rd Qu.:4.000 3rd Qu.:2.000 3rd Qu.:3.000 Max. :20.00 Max. :36.00 Max. :5.000 Max. :5.000 Max. :5.000 Q4 Q5 Q6 Q7 Q8 Min. :1.000 Min. :1.000 Min. :1.000 Min. :1.000 Min. :1.000 1st Qu.:2.000 1st Qu.:1.750 1st Qu.:1.000 1st Qu.:2.500 1st Qu.:1.000 Median :3.000 Median :4.000 Median :2.000 Median :4.000 Median :2.000 Mean :2.763 Mean :2.945 Mean :2.448 Mean :3.434 Mean :2.396 3rd Qu.:4.000 3rd Qu.:4.000 3rd Qu.:4.000 3rd Qu.:4.000 3rd Qu.:3.000 Max. :5.000 Max. :5.000 Max. :5.000 Max. :5.000 Max. :5.000 Q9 Q10 segment Min. :1.000 Min. :1.00 Conspicuous:200 1st Qu.:2.000 1st Qu.:1.00 Price :250 Median :4.000 Median :2.00 Quality :200 Mean :3.085 Mean :2.32 Style :350 3rd Qu.:4.000 3rd Qu.:3.00 Max. :5.000 Max. :5.00
方法二:K-近邻填补:如果一个样本在特征空间中的 k 个最相似即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。KNN 算法中,所选择的邻居都是已经正确分类的对象。该方法在分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
knnImpute <- preProcess(sim.data1,method="knnImpute",k=1)#k=1 sim.data1 <- predict(knnImpute,sim.data1) # 去除类别变量
方法三:袋状数填补
bagImpute <- preProcess(sim.data1,method = 'bagImpute')
sim.data1<- predict(bagImpute,sim.Dat1)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号