Python之文件操作
格式化
-
字符串格式化:将字符串按照一定规格和式样进行规范
"{}{}{}".format()
-
数据格式化:将一组数据按照一定规格和式样进行规范:表示、存储、运算等
1. 文件的使用
1.1 何为文件?
-
文件是数据的抽象和集合
-
文件是存储在辅助存储器上的数据序列
-
文件是数据存储的一种形式
-
文件的展现形态:文本文件和二进制文件
- 文本文件和二进制文件只是文件的展示方式
- 本质上,所有文件都是二进制形式存储
- 形式上,所有文件采用两种方式展示
-
文本文件
- 由单一特定编码组成的文件,如 UTF-8 编码
- 由于存在编码,也被看成是存储着的长字符串
- 适用于例如: .txt 文件、.py 文件
-
二进制文件
- 直接由比特0和1组成,没有同意字符编码
- 一般存在二进制0和1的组织结构,即文件格式
- 使用于例如: .png 文件、.avi 文件等
例如:“中国是个伟大的国家!”
- 文本形式: 中国是个伟大的国家
- 二进制形式:
b' \xd6\xdo\xb9\xfalxca\xc7\xb8\xf6\xce\xb0\xb4\xf3 \xb5\xc4\xb9\xfalxbc\xd2\xa3\xa1'
1.2 文件的打开和关闭
Python语言文件处理的步骤:打开-操作-关闭
对一个文件,如果不对它进行处理的时候,它体现的是一种文件的存储状态,文件在计算机的硬盘中存储。
如果一个程序想处理一个文件,首先要使这个文件变成占用状态。在占用转态中,一个程序可以唯一地、排他地对文件进行相关处理。
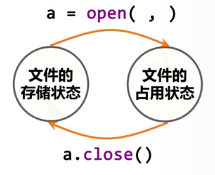
在打开文件后,可以对文件进行数据读入和数据输出,简称为“读文件”和“写文件”。
下面试Python提供的3个常用的读文件函数和3个写文件函数:
# 3个常用的读文件函数
a.read(size)
a.readline(size)
a.readlines(hint)
# 3个常用的写文件函数
a.write(s)
a.awritelines(lines)
a.seek(offset)
文件的打开
<变量名> = open(<文件名>,<打开模式>)
变量名:文件句柄
文件名:文件路径和名称,源文件同目录可省路径
打开模式:文本模式 or 二进制模式
文件路径问题:
windows中文件路径如 D:\python\f.txt 用的是反斜杠 "",我们在输入文件的路径的使用要将它换成 "/",即 D:/python/f.txt;或者增加一个反斜杠进行转义,即D:\python\f.txt。
无论使用绝对路径还是相对路径,我们最终的目的是要让Python找到这个文件。
文件的打开模式
| 描述 | 文件打开模式 |
|---|---|
| 'r' | 只读模式,默认值,如果文件不存在,返回 FileNotFoundError |
| 'w' | 覆盖写模式,文件不存在则创建,存在则完全覆盖 |
| 'x' | 创建写模式,文件不存在则创建,存在则返回 FileExistsError |
| 'a' | 追加写模式,文件不存在则创建,存在则在文件最后追加内容 |
| 'b' | 二进制文件模式 |
| 't' | 文本文件模式,默认值 |
| '+' | 与 r/w/x/a 一同使用,在原功能基础上增加同时读写功能 |
现在用一个名为 f.txt 的文件保存:“中国是个伟大的国家!”,然后用文本形式打开这个文件。
tf = open("f.txt","rt",encoding="UTF-8")
print(tf.readline())
tf.close()
文件关闭
<变量名>.close()
如果写的程序中没有关闭文件的操作,在程序执行过程中,文件始终处于打开状态。当程序退出,文件会自动关闭。
1.3 文件内容的读取
Python语言文件读取的3个常用方法:
| 操作方法 | 描述 |
|---|---|
| f.read(size=-1) | 读入全部内容,如果给出参数,读入前size长度。 |
| f.readline(size=-1) | 读入一行内容,如果给出参数,读入该行前size长度 |
| f.readlines(hint=-1) | 读入文件所有行,以每行为元素形成列表,如果给出参数,读入前 hint 行 |
例如:
>>> s = f.read(2)
中国
>>> s = f.readline()
中国是一个伟大的国家!
>>> s = f.readlines()
['中国是一个伟大的国家!']
1.4 文件的全文本操作
全文本处理:
遍历全文本:方法一
fname = input("请输入要打开的文件的路径:")
fo = open(fname,"r")
txt = fo.read()
fo.close()
优点:一次性读入,统一处理
缺点:如果文件特别大,一次性将文件读入内存将会耗费非常大的时间和资源
----------------------------------------------------------------------------
遍历全文本:方法二
fname = input("请输入要打开的文件的路径:")
fo = open(fname,"r",encoding="UTF-8")
# fo.read(2)参数2表示从文件中读入两个字节
txt = fo.read(2)
while txt != "":
# 对txt进行处理
txt = fo.read(2)
fo.close()
优点:分阶段按数量读入,逐步处理。对于处理大文件更加可行和有效
逐行处理:
文本文件一般都是分行存储,每一行结尾都会有一个回车到下一行。
对于分行存储的文件,采用逐行遍历的方法更常见:
逐行遍历文件:方法一
fname = input("请输入要打开的文件的路径:")
fo = open(fname,"r",encoding="UTF-8")
for line in fo.readlines():
print(line)
fo.close()
优点:分行读入,逐行处理
1.5 数据的文件写入
| 操作方法 | 描述 |
|---|---|
| f.write(s) | 向文件写入一个字符串或者字节流 |
| f.writelines(lines) | 将一个元素为字符串的列表写入文件 |
| f.seek(offset) | 改变当前文件操作指针的位置,offset含义如下: 0-文件开头;1-当前位置;2-文件结尾 |
例如:
>>> f.write("中国是一个伟大的国家")
>>> ls = ["中国","法国","美国"]
>>> f.writelines(ls)
中国法国美国
>>> f.seek(0) #回到文件开头
f.seek()函数的应用:
fo = open("output.txt","w+",encoding="UTF-8")
ls= ["中国","法国","美国"]
fo.writelines(ls)
for line in fo:
print(line)
fo.close()
当我们运行上述代码,预期可能会输出“中国法国美国”,但是我们没有看到任何输出信息。现在在上面代码中增加一行:
fo = open("output.txt","w+",encoding="UTF-8")
ls= ["中国","法国","美国"]
fo.writelines(ls)
fo.seek(0)
for line in fo:
print(line)
fo.close()
当我们将信息写入到文件的时候,当前处理文件的指针在文件的最后面。也就是写过信息后,指针指向了文件的最后面,指向下一次可能写入信息的位置。
此时我们再调用 for in 的方式去遍历一行并且打印输出的时候,它指的是从当前位置指向文件的结尾处,取出其中的每一行并且打印出来。在这个时候我们已经写入的信息在指针的上方而不在指针的下方,因此我们之前的6行代码,并不能输出我们已经写过的信息。为了将我们写过的信息输出,需要调整当前写入后的指针回到文件的初始位置。从初始位置开始再进行逐行遍历,这样就能够把文件的全部信息打印输出。
所以加入 fo.seek(0) 表示写入文件之后将指针返回到文件的最开始,从最开始的位置进行文件全文的遍历打印。程序执行完就可以看到“中国法国美国”了
以上内容资料均来源于中国大学MOOC网-北京理工大学Python语言程序设计课程
课程地址:https://www.icourse163.org/course/BIT-268001

 浙公网安备 33010602011771号
浙公网安备 33010602011771号