
KAFKA 入门:【四】说一说你对 Replica 的理解
大家好,这是一个为了梦想而保持学习的博客。这个专题会记录我对于 KAFKA 的学习和实战经验,希望对大家有所帮助,目录形式依旧为问答的方式,相当于是模拟面试。
【概述】
从第二章我们知道 replica 的本质是对分区数据的一个冗余,那么为什么 KAFKA 中要设计这个数据冗余呢?咱们一点一点来看。
【能否说下 Replica 的主从设计?】
冗余,可以理解为一个动作,就是把一份数据多拷贝了几份出来。
而拷贝出来的数据我们就称之为副本,这也是 Replica 的真正含义,那么多副本之间就必然存在着数据同步的问题:
也就是不同副本之间,以哪个副本的数据为准,如何保持数据一致这两个主要问题。
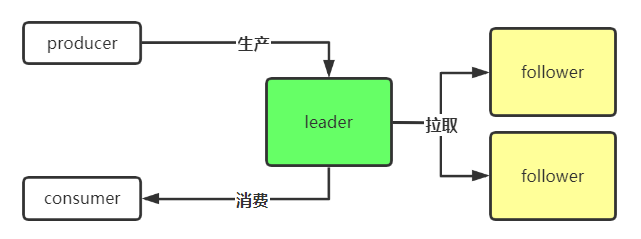
因此,副本之间就有了主从的一个设计,负责提供读写的副本是 leader,而其余的副本称之为 follower,follower 副本只需要从 leader 副本那里一直拉取数据就好了,正常情况下不需要提供读写。
看起来是这个样子的:
【能否说下 Replica 解决了什么问题?】
首先我们要明白一点 —— 某个 Partition 的数据副本,都是分布在不同的 broker 上的,也就是说是分布在不同机器上的,那么显而易见,Replica 是为了解决单点问题而设计的。
我们再考虑下会存在哪些单点问题?
1、当我们生产消息的时候,如果数据只写入了一个 broker 就返回了,那么一旦那个 broker 挂了,或者所在机器宕机了,是不是可能造成我刚才写入的消息就丢失了?
2、我们生产 / 消费都只针对 leader-replica 进行,那么是不是一旦 leader 所在的 broker 挂了,或者所在机器宕机了,就无法进行生产消费了?
以上就是主要存在的两个问题,在引入副本的设计后,解决这两个问题就很简单了:
1、由于存在多副本,因此我们可以设置写入所有副本后,才算写入消息成功;那么数据就会分散到多个节点上,从而避免了单点问题。这就是之前提到的实现了消息的高可靠。
2、由于存在多个副本,并且副本之间的数据一直在同步,一旦 leader 所在节点出现问题,那么我们就可以进行主备切换,让某个 follower 成为新的 leader 来继续提供读写,从而避免了整个服务不可用了。这就是之前提到的实现服务的高可用。
【总结】
到这里,基础的 Topic/Partition/Replica 的概念就已经全部过了一遍了,Kafka 的整个设计很优秀当然也很复杂,后续会慢慢深入讨论各自机制以及部分源码。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号