
给你一个字符数组,每个单词长度一样,你从中选单词,组成的 二位数组中 横向和纵向 组成的一维数组都一样。
注意1: 单词可以重复被选择
注意2. 字符串数组可能非常的大,有1000 个
Input:
["area","lead","wall","lady","ball"]
Output:
[
[ "wall",
"area",
"lead",
"lady"
],
[ "ball",
"area",
"lead",
"lady"
]
]
分析一: 既然单词可以重复,那就是一个组合问题,每个节点上的下一个节点都可以分解成 数组里全部元素, 如果单词长度为5, array 里有1000个单词,那么 最后一层就有 1000^5个节点,很容易TLE。 dfs 树为:
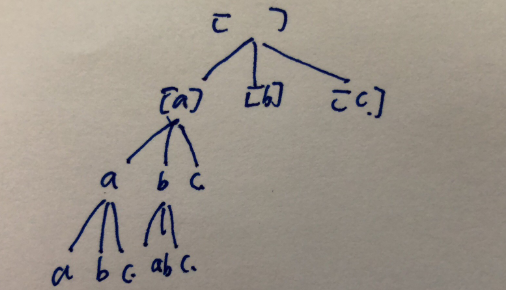
分析二: 假设单词当都为5, 第一个单词任意放, 第二个单词首字母 [1][0]位置 会被 第一个单词 [0][1] 位置所决定。
第三个word 前两个字母, [2][0], [2][1] 会被 [0][2],[1][2] 位置所决定, 以此内推。
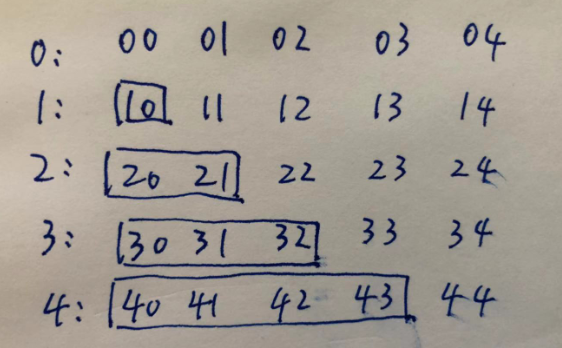
针对这个特性,可以有两个方案:
1. 在普通dfs 中, 放 第 i个word 时, 先判断 前 i-1个letters 是否合法,不合法则不放。
2. 用Trie , 每次主动选prefix 满足条件的单词来构建。比如构建 第3个单词时, 得看 20,21 位置作为prefix 来主动选择单词。
对于方案一,代码很容易,但当 array 里面数量很大,因为着每一层节点都很多时,会TLE, code 如下: 15/16, 16个tests 过了15个,最后一个会TLE。
class Solution { public List<List<String>> wordSquares(String[] words) { List<List<String>> result = new ArrayList<>(); dfs(new ArrayList<>(), result, words); return result; } private void dfs(List<String> curResult, List<List<String>> result, String[] words){ if(curResult.size() == words[0].length()){ result.add(new ArrayList<>(curResult)); return; } //if(depth >= words[0].length()) return; for(int i=0; i<words.length; i++){ if(!validPut(curResult,words[i])) continue; dfs(curResult,result,words); curResult.remove(curResult.size()-1); } } private boolean validPut(List<String> curResult, String word){ int size = curResult.size(); for(int i=0; i<size; i++){ if(word.charAt(i) != curResult.get(i).charAt(size) ) return false; } curResult.add(word); // System.out.println(curResult); return true; } }
为了不TLE, 只能选择用 Trie Tree 主动选择 构建 每层节点,这样随着层数的增加 越到后面节点越少。
每次dfs 需要先产生prefix, 并且去 Trie 里searchAll 包含prefix 的 单词。
class Solution { public List<List<String>> wordSquares(String[] words) { List<List<String>> result = new ArrayList<>(); Trie trie = new Trie(); for(String word: words){ trie.insert(word); } dfs(new ArrayList<>(), result, trie,words[0].length()); return result; } private void dfs(List<String> curResult, List<List<String>> result, Trie trie, int len){ if(curResult.size() == len){ result.add(new ArrayList<>(curResult)); return; } // for(int i=0; i<words.length; i++){ StringBuilder prefix = new StringBuilder(); int size = curResult.size(); for(int i=0; i<size; i++){ prefix.append(curResult.get(i).charAt(size)); } List<String> list = trie.searchAll(prefix.toString()); for(String str: list){ curResult.add(str); dfs(curResult,result,trie,len); curResult.remove(curResult.size()-1); } } } class Trie { /** Initialize your data structure here. */ TrieNode root; public Trie() { root = new TrieNode(); } /** Inserts a word into the trie. */ public void insert(String word) { TrieNode p = root; for(int i=0; i<word.length(); i++){ char c = word.charAt(i); if(p.children[c-'a'] != null){ p = p.children[c-'a']; } else { TrieNode node = new TrieNode(c); p.children[c-'a'] = node; p = node; } if(i == word.length()-1){ p.isLeaf = true; } } } public List<String> searchAll(String prefix){ TrieNode p = searchNode(prefix); List<String> result = new ArrayList<>(); if(p == null) return result; preOrder(p, result, prefix); return result; } private void preOrder(TrieNode root, List<String> result, String curResult){ if(root.isLeaf) { result.add(curResult.toString()); } for(int i=0; i<root.children.length; i++){ //curResult.append(root.children[i].c) if(root.children[i] != null){ //curResult.append(root.children[i].c); String new_curResult = curResult + root.children[i].c ; preOrder(root.children[i],result,new_curResult); } } } private TrieNode searchNode(String str){ TrieNode p = root; for(int i=0; i<str.length(); i++){ char c = str.charAt(i); if(p.children[c-'a'] == null) return null; else { p = p.children[c-'a']; } } return p; } class TrieNode{ char c; TrieNode[] children; boolean isLeaf; TrieNode(){ children = new TrieNode[26]; } TrieNode(char c){ this.c = c; children = new TrieNode[26]; } } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号