
和39. Combination Sum 不同的是,377 可以把不同排列的解认为是不同解,例如 [1,1,2] 和 [2,1,1] 是不同解,并且只需要求出解的个数。
例如
nums = [1, 2, 3] target = 4 The possible combination ways are: (1, 1, 1, 1) (1, 1, 2) (1, 2, 1) (1, 3) (2, 1, 1) (2, 2) (3, 1)
返回解的个数7即可。
写成如下解法结果正确,但会TLE,并且在递归中返回解的个数,每次 return 1 就好,不能是count++
class Solution { public int combinationSum4(int[] nums, int target) { return dfs( nums,target, 0); } private int dfs( int[] nums, int target, int sum){ int count = 0; if(sum > target) return 0; if(sum == target) { //count++; return 1; } for(int i=0; i<nums.length; i++){ sum+= nums[i]; count += dfs( nums,target, sum); sum-= nums[i]; } return count; } }
这里拿backtraing 每次把sum += nums[i] 再去掉 上一次的 sum -= num[i]
但不是一个好的写法,好的写法是定义 remain ,而不是sum, code 如下,但依然会TLE
class Solution { public int combinationSum4(int[] nums, int target) { return dfs( nums,target); } private int dfs( int[] nums, int remain){ int count = 0; if(remain < 0) return 0; if(remain == 0) { return 1; } for(int i=0; i<nums.length; i++){ count += dfs(nums, remain - nums[i]); } return count; } }
优化的方法是用记忆化搜索:
因此中间存在大量重复结果, 比如 remain 为2 时,之前可能已经计算过 remain 为2 的结果了,直接从map 里返回即可。
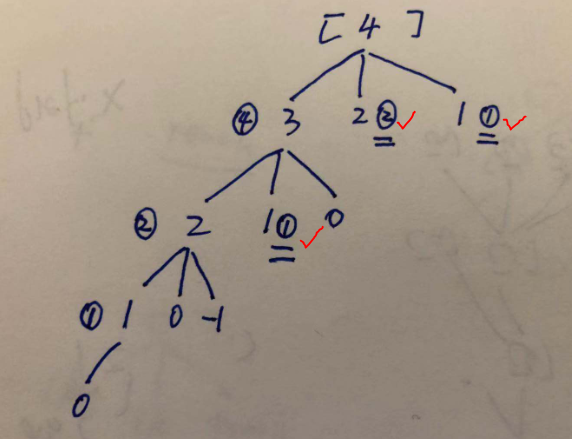
以 target = 4, nums = [1,2,3] 为例画出递归树, 红色勾部分表示剪枝的部分,已经从 map 里得到之前运算的结果了。
class Solution { private int addWays(Map<Integer,Integer> cache, int [] nums, int remaining){ if(cache.containsKey(remaining)){ return cache.get(remaining); } if(remaining==0)return 1; else if(remaining<0)return 0; int count = 0; for(int i=0; i<nums.length;++i){ count+=addWays(cache,nums,remaining-nums[i]); } //System.out.println("remain "+remaining+ " count "+ count); cache.put(remaining,count); return count; } public int combinationSum4(int[] nums, int target) { return addWays(new HashMap<>(),nums,target); } }
140. 通过字典里的单词去构建字符串s,返回所有可能的构建结果,并且字典里的单词可以重复使用。
s = "catsanddog" wordDict =["cat", "cats", "and", "sand", "dog"]Output:[ "cats and dog", "cat sand dog" ]
这道题本质上和 377 一样, 求得sum 相当于最后构建的字符串 s, 字典相当于给定的nums array, 并且字典和nums 里的数字都可以重复使用,所以二者本质上一样。
一开始只当成一个普通的back trakcing 来做,写了如下的code ,结果TLE了。
注意这里for 循环的写法: for(int end = start+1; end<=s.length(); end++){
比如给定 s = "aaaaaaaaaaaa" dict = {"a", "aa", "aaa", "aaaaa"} ,这样所有的prefix 都可以匹配上, worst case 是 n^n, 显然会TLE。
class Solution { public List<String> wordBreak(String s, List<String> wordDict) { Set<String> dict = new HashSet<>(); for(String word: wordDict){ dict.add(word); } List<String> result = new ArrayList<>(); dfs(new ArrayList<>(), result,s,0,dict); return result; } private void dfs(List<String> curResult, List<String> result, String s,int start, Set<String> dict){ if(start == s.length()){ StringBuilder sb = new StringBuilder(curResult.get(0)); for(int i=1; i<curResult.size(); i++){ sb.append(" "+curResult.get(i)); } result.add(sb.toString()); } for(int end = start+1; end<=s.length(); end++){ String substr = s.substring(start,end); if(dict.contains(substr)){ curResult.add(substr); dfs(curResult,result,s,end,dict); curResult.remove(curResult.size()-1); } } } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号