逻辑回归(二分法)
数据预处理(生成虚拟变量)
对于因变量为分类变量的情况,我们可以使用逻辑回归进行处理。 把y看成事件发生的概率,y>0.5表示发生;y<0.5表示不发生
线性概率模型(Linear Probability Model,简记LPM)直接用原来的回归模型进行回归

限制条件(两点分布--伯努利分布)

连接函数的取法


logistics回归实现原理

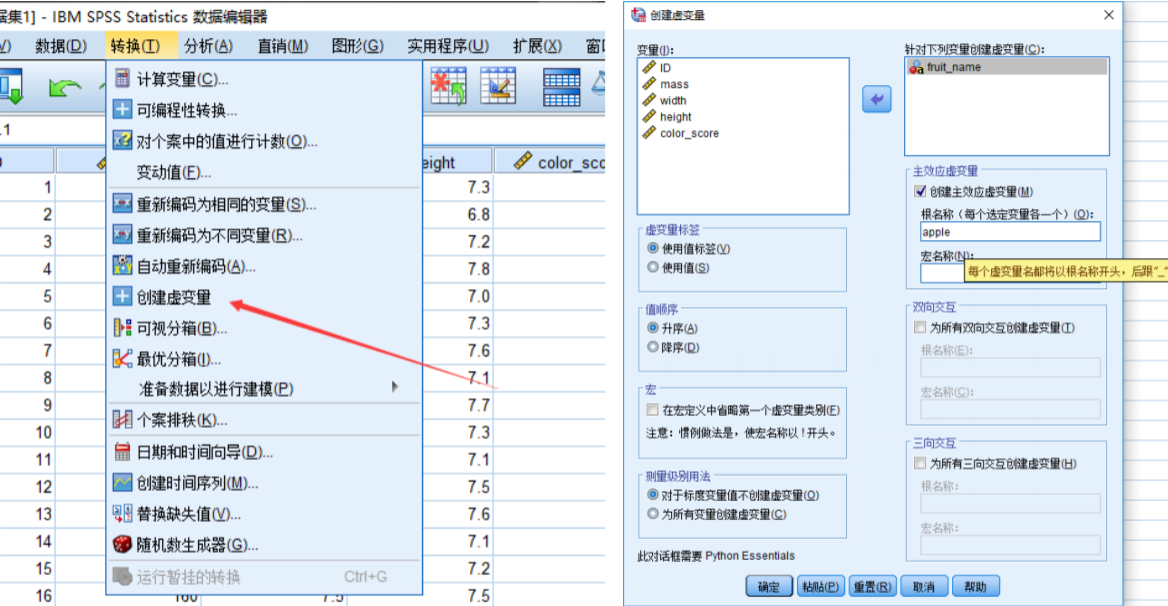
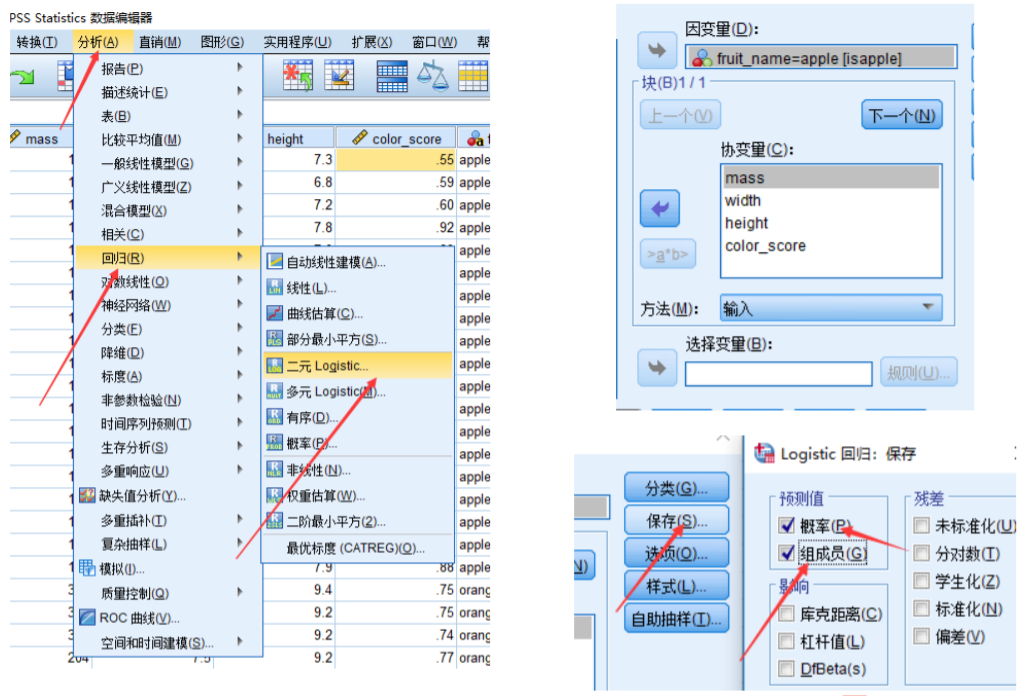
SPSS求解逻辑回归
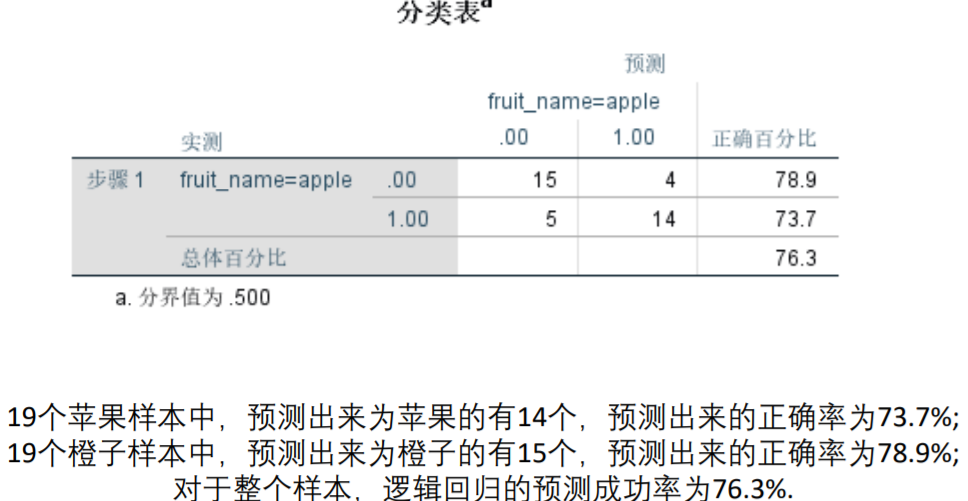
预测成功率
逻辑回归系数表
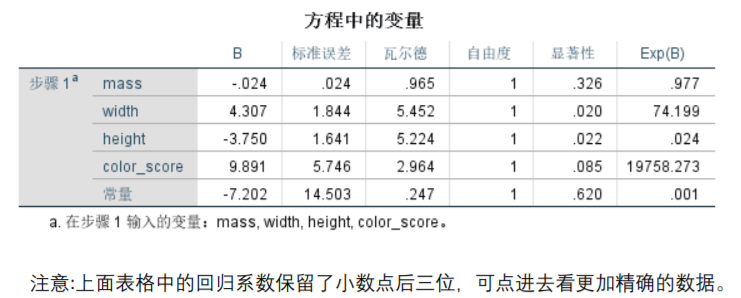
表格中新添的两列解读
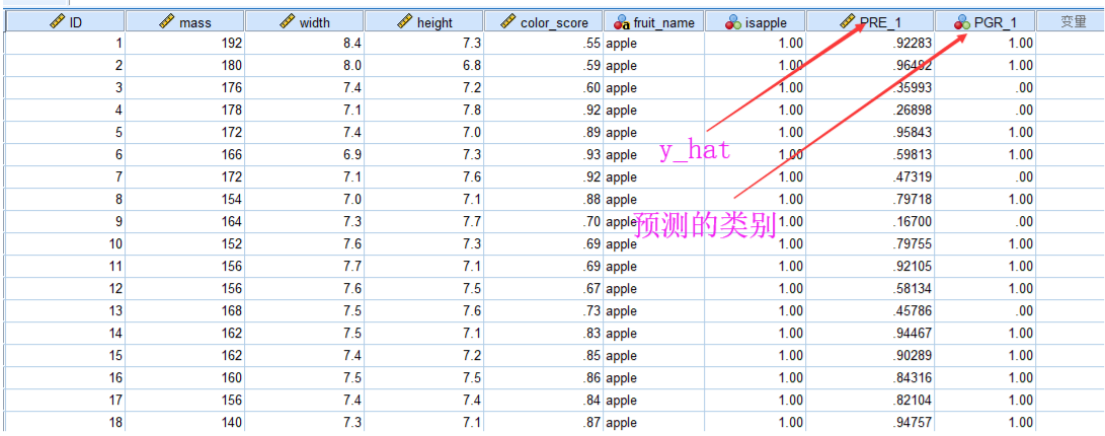
假如自变量有分类变量的解决办法
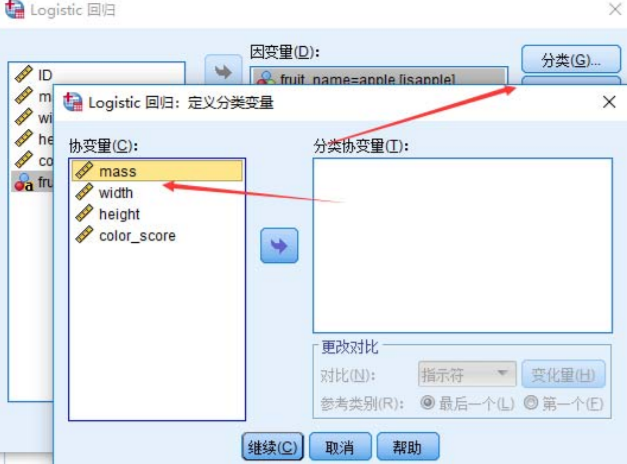
⭐预测结果较差的解决办法
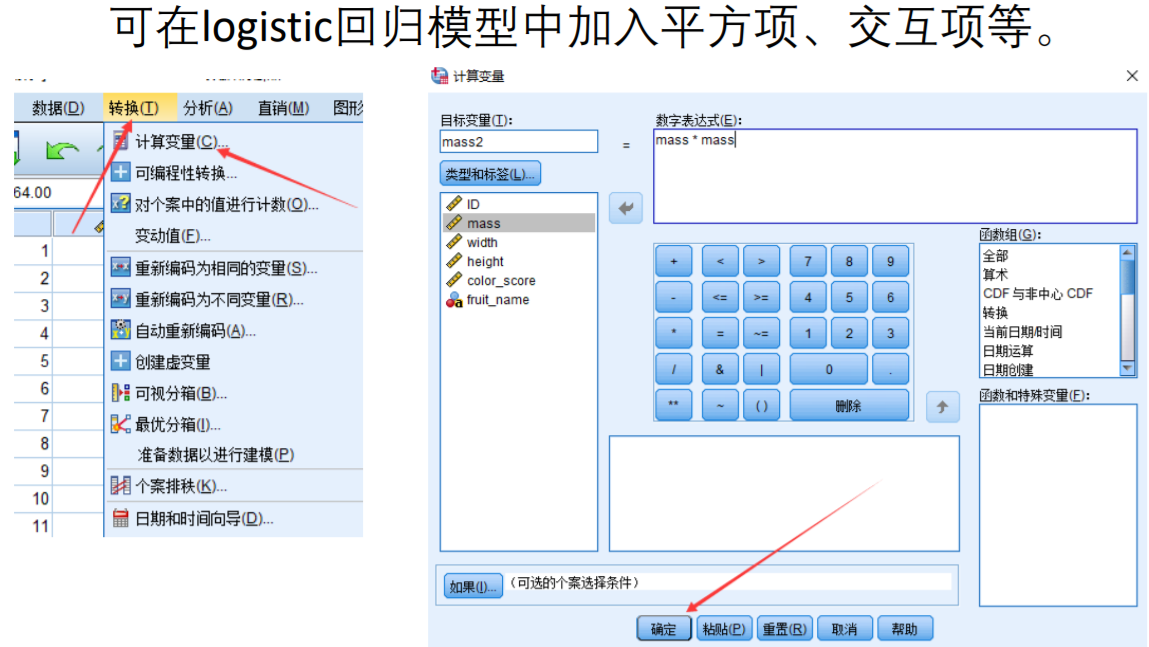
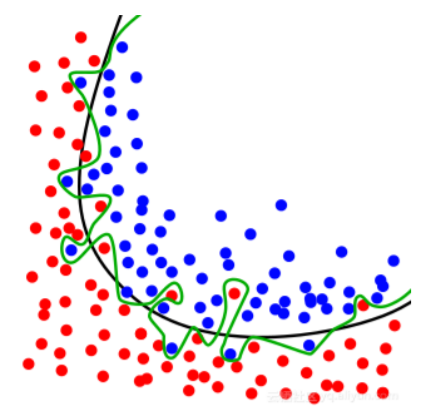
样本量过大会出现过拟合现象
虽然预测能力提高了,但是容易发生过拟合的现象。 对于样本数据的预测非常好,但是对于样本外 的数据的预测效果可能会很差。 (是不是和龙格现象有点相似)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号