HttpRunner3.x 学习8-参数化数据驱动
HttpRunner v3.x开始,测试用例和测试用例集都可以实现参数化数据驱动,需要使用parameters关键字,定义参数名称并指定数据源取值方式。
如果让测试用例(testcase)的概念更纯粹,可以考虑将参数化的功能在testsuite中实现。
创建一个 testsuite,在 testsuite 中引用测试用例,并定义参数化配置。
参数配置概述
如需对某测试用例(testcase)实现参数化数据驱动,需要使用parameters关键字,定义参数名称并指定数据源取值方式。
参数名称的定义分为两种情况: * 独立参数单独进行定义; * 多个参数具有关联性的参数需要将其定义在一起,采用短横线(-)进行链接。
数据源三种方式
方式一:* 脚本中直接指定参数列表:该种方式最为简单易用,适合参数列表比较小的情况。 示例:

方式二:通过内置的parameterize(可简写为P)函数引用CSV文件:该种方式需要准备CSV数据文件,适合数据量比较大的情况。 示例:
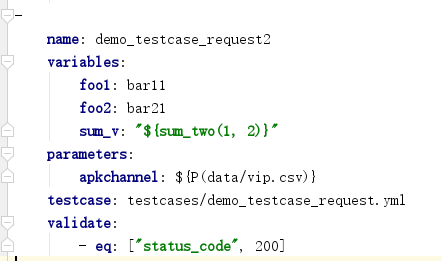
方式三:在debugtalk.py中自定义的函数生成参数列表:该种方式最为灵活,可通过自定义Python函数实现任意场景的数据驱动机制,当需要动态生成参数列表时也需要选择该种方式。 示例:
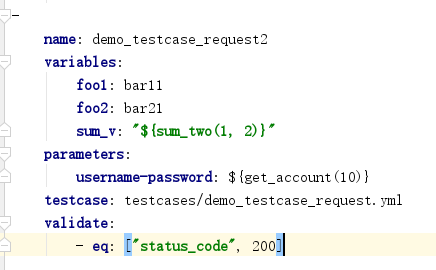
三种方式可根据实际项目需求进行灵活选择,同时支持多种方式的组合使用。加入测试用例中定义了多个参数,那么测试用例在运行时会对参数进行笛卡尔积组合,覆盖所有参数组合情况。
参数详细配置
将参数名称定义和数据源指定方式进行组合,共有6中形式。先分别针对每一类情况进行详细说明。
独立参数&直接指定参数列表
对于参数列表比较小的情况,组u ii简单的方式是直接在YAML/JSON中指定参数列表内容。
例如,对于独立参数uid,参数列表为[1001, 1002, 1003, 1004],那么就可以按照如下方式进行配置:

进行该配置后,测试用例在运行时就会对uid实现数据驱动,即分别使用[1001, 1002, 1003, 1004]四个值运行测试用例。
关联参数&直接指定参数列表
对于具有关联性的多个参数,比如username和password,那么可以按照如下方式进行配置:
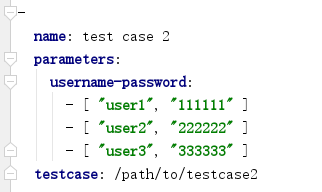
进行该配置后,测试用例在运行时就会对username和password实现数据驱动,即分别使用 {"username": "user1", "password": "111111"}、{"username": "user2", "password": "222222"}、{"username": "user3", "password": "333333"} 运行 3 次测试,并且保证参数值总是成对使用。
独立参数 & 引用CSV文件
对于已有参数列表,并且数据量比较大的情况,比较适合的方式是将参数列表值存储在 CSV 数据文件中。
对于 CSV 数据文件,需要遵循如下几项约定的规则:
- CSV 文件中的第一行必须为参数名称,从第二行开始为参数值,每个(组)值占一行;
- 若同一个 CSV 文件中具有多个参数,则参数名称和数值的间隔符需实用英文逗号;
- 在 YAML/JSON 文件引用 CSV 文件时,文件路径为基于项目根目录(debugtalk.py 所在路径)的相对路径。
例如,user_id 的参数取值范围为 1001~2000,那么我们就可以创建 user_id.csv,并且在文件中按照如下形式进行描述。
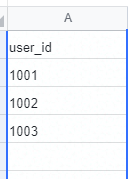
然后在 YAML/JSON 测试用例文件中,就可以通过内置的 parameterize(可简写为 P)函数引用 CSV 文件。
假设项目的根目录下有 data 文件夹,user_id.csv 位于其中,那么 user_id.csv 的引用描述如下:

即 P 函数的参数(CSV 文件路径)是相对于项目根目录的相对路径。当然,这里也可以使用 CSV 文件在系统中的绝对路径,不过这样的话在项目路径变动时就会出现问题,因此推荐使用相对路径的形式。
关联参数&引用CSV文件
对于具有关联性的多个参数,例如 username 和 password,那么就可以创建 account.csv,并在文件中按照如下形式进行描述。
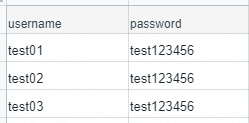
然后在 YAML/JSON 测试用例文件中,就可以通过内置的 parameterize(可简写为 P)函数引用 CSV 文件。
假设项目的根目录下有 data 文件夹,account.csv 位于其中,那么 account.csv 的引用描述如下:
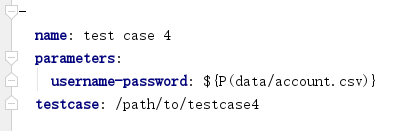
需要说明的是,在 parameters 中指定的参数名称必须与 CSV 文件中第一行的参数名称一致,顺序可以不一致,参数个数也可以不一致。
例如,在 account.csv 文件中可以包含多个参数,username、password、phone、age:
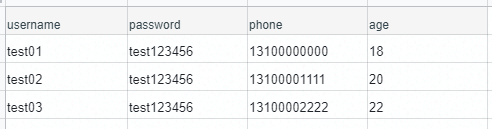
而在 YAML/JSON 测试用例文件中指定参数时,可以只使用部分参数,并且参数顺序无需与 CSV 文件中参数名称的顺序一致。

独立参数 & 引用自定义函数
对于没有现成参数列表,或者需要更灵活的方式动态生成参数的情况,可以通过在 debugtalk.py 中自定义函数生成参数列表,并在 YAML/JSON 引用自定义函数的方式。
例如,若需对 user_id 进行参数化数据驱动,参数取值范围为 1001~1004,那么就可以在 debugtalk.py 中定义一个函数,返回参数列表。

然后,在 YAML/JSON 的 parameters 中就可以通过调用自定义函数的形式来指定数据源。

另外,通过函数的传参机制,还可以实现更灵活的参数生成功能,在调用函数时指定需要生成的参数个数。
关联参数 & 引用自定义函数
对于具有关联性的多个参数,实现方式也类似。 例如,在debugtalk.py中定义函数get_account,生成指定数量的账号密码参数列表。

在YAML/JSON的parameters中就可以调用自定义函数生成指定数量的参数列表
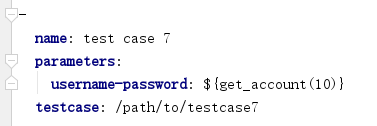
需要注意的是,在自定义函数中,生成的参数列表必须为 list of dict 的数据结构,该设计主要是为了与 CSV 文件的处理机制保持一致。
参数化运行
完成以上参数定义和数据源准备工作之后,参数化运行与普通测试用例的运行完全一致。 采用hrun命令运行自动化测试:
hrun tests/data/demo_parameters.yml
采用 locusts 命令运行性能测试:
locusts -f tests/data/demo_parameters.yml
区别在于,自动化测试时遍历一遍后会终止执行,性能测试时每个并发用户都会循环遍历所有参数。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号