机器学习:SVM实践:Libsvm的使用
引言
本文从应用的角度出发,使用Libsvm函数库解决SVM模型的分类与回归问题
首先说明一下实验数据,实验数据是Libsvm自带的heart_sacle,是个mat文件
加载数据集
将mat文件导入MATLAB后会有270*13的实例矩阵变量heart_scale_inst和270*1的标签矩阵heart_scale_label

分类
将数据集分为训练数据和测试数据
首先我们将实验数据分为训练数据和测试数据
load heart_scale;
train_data = heart_scale_inst(1:150,:);
train_label = heart_scale_label(1:150,:);
test_data = heart_scale_inst(151:270,:);
test_label = heart_scale_label(151:270,:);
利用训练数据集训练得到训练模型
然后我们就可以用训练数据得到训练模型
model=svmtrain(train_label,train_data);%%具体参数可以参见svmtrain.c
我们查看返回的model变量可以发现是如下形式

下面对返回模型的参数进行一些说明
model参数说明
首先是Parameters,其变量打开是以下五个数据

参数意义从上到下依次为:
-s svm类型:SVM设置类型(默认0)
-t 核函数类型:核函数设置类型(默认2)
-d degree:核函数中的degree设置(针对多项式核函数)(默认3)
-g r(gama):核函数中的gamma函数设置(针对多项式/rbf/sigmoid核函数) (默认类别数目的倒数)
-r coef0:核函数中的coef0设置(针对多项式/sigmoid核函数)((默认0)
然后是model.nr_class,这个变量表示数据集中有多少类别;= 2 for regression/one-class svm
接下来是model.Label,这个变量表示数据集中类别的标签都是什么
然后是model.totalSV,代表总共的支持向量的数目
model.nSV表示每类样本的支持向量的数目,有多少类就有多少个值
而对于model.ProbA和model.ProbB是要使用-b参数时才能用到,用于概率估计。
-b probability_estimates: whether to train a SVC or SVR model for probability estimates,0 or 1 (default 0)
可以参见《A note on Platt's probabilistic outputs for support vector machines》论文
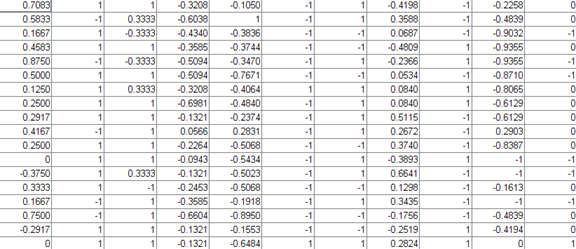
然后是model.sv_coef,这是一个totalSV*1的矩阵,承装的是totalSV个支持向量在决策函数中的系数
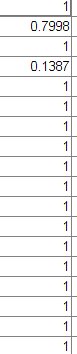
而model.SVs是一个totalSV×维度的稀疏矩阵,承装的是totalSV个支持向量

最后是model.rho是决策函数中的常数项的相反数
然后是利用测试数据集进行测试
[predict_label, accuracy, dec_values] = svmpredict(test_label, test_data, model);
得到三个参数,分别对参数说明如下
返回参数:
predict_label是预测标签向量
accuracy从上到下依次的意义分别是:
-分类准率(分类问题中用到的参数指标)
-平均平方误差(MSE (mean squared error))[回归问题中用到的参数指标]
-平方相关系数(r2 (squared correlation coefficient))[回归问题中用到的参数指标]
dec_values是一个包含decision值或概率估计(-b 1)的矩阵

最终的类别判断就是根据这个dec_value和阈值作比较得到的
另外多说一句如果k个类,对于decision值,每行包含k(k-1)/2个二分类问题的结果;对于概率,每列包含k个属于每类的概率值
回归
对于回归依旧是用svmtrain这个函数
但是对于回归来说选择的SVM类型有限制,svmtrain用-s这个选项指定的SVM的类型(default 0)
0 – C-SVC
1 – nu-SVC
2 – one-class SVM
3 – epsilon-SVR
4 – nu-SVR
对于回归来说,只能选3或者4,3表示epsilon-support vector regression, 4表示nu-support vector regression。-t是选择核函数,通常选用RBF核函数,原因在"A Practical Guide support vector classification"中已经简单介绍过了。-p尽量选个比较小的数字。需要仔细调整的重要参数是-c和-g。我们用以下代码来进行参数寻优
mse = 10^10;
for log2c = -10:10,
for log2g = -10:10,
cmd = ['-v 3 -c ', num2str(2^log2c), ' -g ', num2str(2^log2g) , ' -s 3 -p 0.4 -n 0.1'];
cv = svmtrain(train_Y,train_x,cmd);
if (cv < mse),
mse = cv; bestc = 2^log2c; bestg = 2^log2g;
end
end
end
-log2c是给出参数c的范围和步长
-log2g是给出参数g的范围和步长
-log2p是给出参数p的范围和步长

 浙公网安备 33010602011771号
浙公网安备 33010602011771号