
性能监控之Telegraf+InfluxDB+Grafana实现结构化日志实时监控
性能监控之Telegraf+InfluxDB+Grafana实现结构化日志实时监控
https://blog.csdn.net/zuozewei/article/details/102584480
一、背景
由于我们的自研客户端压测工具的测试结果是结构化日志文件,而考虑到目前性能监控需要做到实时化和集中化,那么需要一种定时和批量采集结构化日志文件的采集 agent,而刚好 Telegraf Logparser插件可以满足这个需求。
二、Telegraf logparser
Logparser插件流式传输并解析给定的日志文件,目前支持解析 “grok” 模式和正则表达式模式。
1、Grok 解析器
熟悉 grok 解析器的最佳途径是参考 logstash文档:
https://www.elastic.co/guide/en/logstash/current/plugins-filters-grok.html
Telegraf 解析器使用经过稍微修改的 logstash “grok” 模式版本,其格式为
%{<capture_syntax>[:<semantic_name>][:<modifier>]}
1
capture_syntax :定义解析输入行的 grok 模式
semantic_name:用于命名字段或标记
modifier:扩展被解析项转换为的数据类型或其他特殊处理
默认情况下,所有命名的捕获都转换为字符串字段。如果模式没有语义名称,则不会捕获它。时间戳修饰符可用于将捕获转换为已解析度量的时间戳。如果未解析任何时间戳,则将使用当前时间创建度量。
注意:每行必须捕获至少一个字段。将所有捕获转换为标记的模式将导致无法写入到时序数据库的点。
Available modifiers:
string (default if nothing is specified)
int
float
duration (ie, 5.23ms gets converted to int nanoseconds)
tag (converts the field into a tag)
drop (drops the field completely)
Timestamp modifiers:
ts (This will auto-learn the timestamp format)
ts-ansic (“Mon Jan _2 15:04:05 2006”)
ts-unix (“Mon Jan _2 15:04:05 MST 2006”)
ts-ruby (“Mon Jan 02 15:04:05 -0700 2006”)
ts-rfc822 (“02 Jan 06 15:04 MST”)
ts-rfc822z (“02 Jan 06 15:04 -0700”)
ts-rfc850 (“Monday, 02-Jan-06 15:04:05 MST”)
ts-rfc1123 (“Mon, 02 Jan 2006 15:04:05 MST”)
ts-rfc1123z (“Mon, 02 Jan 2006 15:04:05 -0700”)
ts-rfc3339 (“2006-01-02T15:04:05Z07:00”)
ts-rfc3339nano (“2006-01-02T15:04:05.999999999Z07:00”)
ts-httpd (“02/Jan/2006:15:04:05 -0700”)
ts-epoch (seconds since unix epoch, may contain decimal)
ts-epochmilli (milliseconds since unix epoch, may contain decimal)
ts-epochnano (nanoseconds since unix epoch)
ts-syslog (“Jan 02 15:04:05”, parsed time is set to the current year)
ts-“CUSTOM”
自定义时间格式必须在引号内,并且必须是 “参考时间” 的表示形式 on Jan 2 15:04:05 -0700 MST 2006。
要匹配逗号小数点,可以使用句点。例如,%{TIMESTAMP:timestamp:ts-"2006-01-02 15:04:05.000"} 可以用来匹配 "2018-01-02 15:04:05,000" 要匹配逗号小数点,可以在模式字符串中使用句点。
有关更多详细信息,请参考:
https://golang.org/pkg/time/#Parse
Telegraf 具有许多自己的内置模式,并支持大多数 logstash 的内置模式。 Golang 正则表达式不支持向前或向后查找。不支持依赖于这些的logstash 模式。
如果需要构建模式以匹配日志的调试,使用 https://grokdebug.herokuapp.com 调试非常有用!
2、示例
我们可以使用 logparser 将 Telegraf 生成的日志行转换为指标。
为此,我们需要配置 Telegraf 以将日志写入文件。可以使用 agent.logfile 参数或配置 syslog 来完成。
2、示例
我们可以使用 logparser 将 Telegraf 生成的日志行转换为指标。
为此,我们需要配置 Telegraf 以将日志写入文件。可以使用 agent.logfile 参数或配置 syslog 来完成。
Logparser配置:
[[inputs.logparser]]
files = ["/var/log/telegraf/telegraf.log"]
[inputs.logparser.grok]
measurement = "telegraf_log"
patterns = ['^%{TIMESTAMP_ISO8601:timestamp:ts-rfc3339} %{TELEGRAF_LOG_LEVEL:level:tag}! %{GREEDYDATA:msg}']
custom_patterns = '''
TELEGRAF_LOG_LEVEL (?:[DIWE]+)
'''
log 内容:
2018-06-14T06:41:35Z I! Starting Telegraf v1.6.4
2018-06-14T06:41:35Z I! Agent Config: Interval:3s, Quiet:false, Hostname:"archer", Flush Interval:3s
2018-02-20T22:39:20Z E! Error in plugin [inputs.docker]: took longer to collect than collection interval (10s)
2018-06-01T10:34:05Z W! Skipping a scheduled flush because there is already a flush ongoing.
2018-06-14T07:33:33Z D! Output [file] buffer fullness: 0 / 10000 metrics.
InfluxDB 采集的数据:
telegraf_log,host=somehostname,level=I msg="Starting Telegraf v1.6.4" 1528958495000000000 telegraf_log,host=somehostname,level=I msg="Agent Config: Interval:3s, Quiet:false, Hostname:\"somehostname\", Flush Interval:3s" 1528958495001000000 telegraf_log,host=somehostname,level=E msg="Error in plugin [inputs.docker]: took longer to collect than collection interval (10s)" 1519166360000000000 telegraf_log,host=somehostname,level=W msg="Skipping a scheduled flush because there is already a flush ongoing." 1527849245000000000 telegraf_log,host=somehostname,level=D msg="Output [file] buffer fullness: 0 / 10000 metrics." 1528961613000000000
三、具体实践
1、日志格式
需要采集的结构化日志示例如下:
TestConfig1,5.0,2019/3/6 17:48:23,2019/3/6 17:48:30,demo_1,open,3,1,6.8270219,openscreen>validatestage TestConfig2,5.0,2019/3/6 17:48:33,2019/3/6 17:48:40,demo_2,open,3,2,6.9179322,openscreen>validatestage TestConfig3,5.0,2019/3/6 17:48:43,2019/3/6 17:50:23,demo_1,open,3,3,100.1237885,switchscreen>validatestag TestConfig3,5.0,2019/3/6 17:48:43,2019/3/6 17:50:23,demo_1,open,3,3,100.1237885,switchscreen>validatestag TestConfig3,5.0,2019/3/6 17:48:43,2019/3/6 17:50:23,demo_1,open,3,3,100.1237885,switchscreen>validatestag TestConfig3,5.0,2019/3/6 17:48:43,2019/3/6 17:50:23,demo_1,open,3,3,100.1237885,switchscreen>validatestag TestConfig3,5.0,2019/3/6 17:48:43,2019/3/6 17:50:23,demo_1,open,3,3,100.1237885,switchscreen>validatestag TestConfig3,5.0,2019/3/6 17:48:43,2019/3/6 17:50:23,demo_1,open,3,3,100.1237885,switchscreen>validatestag
注意:这个日志是批量生成的,每一次客户端压测当前目录都会生成一个 *.log 的文件。数据采集的时候需要为对应列指定列名。
2、Telegraf 配置
配置 Telegraf.conf
[[inputs.logparser]] ## Log files to parse. ## These accept standard unix glob matching rules, but with the addition of ## ** as a "super asterisk". ie: ## /var/log/**.log -> recursively find all .log files in /var/log ## /var/log/*/*.log -> find all .log files with a parent dir in /var/log ## /var/log/apache.log -> only tail the apache log file files = ["C:\\Release\\TestConfigLog\\*.log"] ## Read files that currently exist from the beginning. Files that are created ## while telegraf is running (and that match the "files" globs) will always ## be read from the beginning. from_beginning = false ## Method used to watch for file updates. Can be either "inotify" or "poll". watch_method = "poll" ## Parse logstash-style "grok" patterns: ## Telegraf built-in parsing patterns: https://goo.gl/dkay10 [inputs.logparser.grok] ## This is a list of patterns to check the given log file(s) for. ## Note that adding patterns here increases processing time. The most ## efficient configuration is to have one pattern per logparser. ## Other common built-in patterns are: ## %{COMMON_LOG_FORMAT} (plain apache & nginx access logs) ## %{COMBINED_LOG_FORMAT} (access logs + referrer & agent) patterns = ['%{WORD:scene},%{NUMBER:version:float},%{TS_WIN:begtime},%{TS_WIN:endtime},%{WORD:canvasName},%{WORD:canvasCase},%{NUMBER:totaltimes:int},%{NUMBER:current:int},%{NUMBER:time_consuming:float}'] ## Name of the outputted measurement name. measurement = "bigscreen" ## Full path(s) to custom pattern files. ## custom_pattern_files = [] ## Custom patterns can also be defined here. Put one pattern per line. custom_patterns = 'TS_WIN %{YEAR}/%{MONTHNUM}/%{MONTHDAY}[T ]%{HOUR}:?%{MINUTE}(?::?%{SECOND})?' ## Timezone allows you to provide an override for timestamps that ## don't already include an offset ## e.g. 04/06/2016 12:41:45 data one two 5.43µs ## ## Default: "" which renders UTC ## Options are as follows: ## 1. Local -- interpret based on machine localtime ## 2. "Canada/Eastern" -- Unix TZ values like those found in https://en.wikipedia.org/wiki/List_of_tz_database_time_zones ## 3. UTC -- or blank/unspecified, will return timestamp in UTC timezone = "Local"
注意:
files = [" *.log"],解决了当前目录多文件对象匹配的需求
watch_method = "poll",设置轮训获取文件更新
custom_patterns,自定义一个时间格式化模式匹配
InfluxDB 生成的指标数据如下:
> select * from bigscreen limit 5 name: bigscreen time begtime canvasCase canvasName current endtime host path scene time_consuming totaltimes version ---- ------- ---------- ---------- ------- ------- ---- ---- ----- -------------- ---------- ------- 1552296231630588200 2019/3/6 17:48:43 open demo_1 3 2019/3/6 17:50:23 DESKTOP-MLD0KTS C:\Users\htsd\Desktop\VBI5\Release\TestConfigLog\1.log TestConfig3 100.1237885 3 5 1552296231630588201 2019/3/6 17:48:43 open demo_1 3 2019/3/6 17:50:23 DESKTOP-MLD0KTS C:\Users\htsd\Desktop\VBI5\Release\TestConfigLog\1.log TestConfig3 100.1237885 3 5 1552296231630588202 2019/3/6 17:48:43 open demo_1 3 2019/3/6 17:50:23 DESKTOP-MLD0KTS C:\Users\htsd\Desktop\VBI5\Release\TestConfigLog\1.log TestConfig3 100.1237885 3 5 1552296231631587700 2019/3/6 17:48:43 open demo_1 3 2019/3/6 17:50:23 DESKTOP-MLD0KTS C:\Users\htsd\Desktop\VBI5\Release\TestConfigLog\1.log TestConfig3 100.1237885 3 5 1552297570005076300 2019/3/6 17:48:23 open demo_1 1 2019/3/6 17:48:30 DESKTOP-MLD0KTS C:\Users\htsd\Desktop\VBI5\Release\TestConfigLog\12.log TestConfig1 6.8270219 3 5
列名都是我们自定义的。
四、Grafana设置
整体的考虑是使用一个表格进行数据展示,支持按个别字段筛选。
四、Grafana设置
整体的考虑是使用一个表格进行数据展示,支持按个别字段筛选。
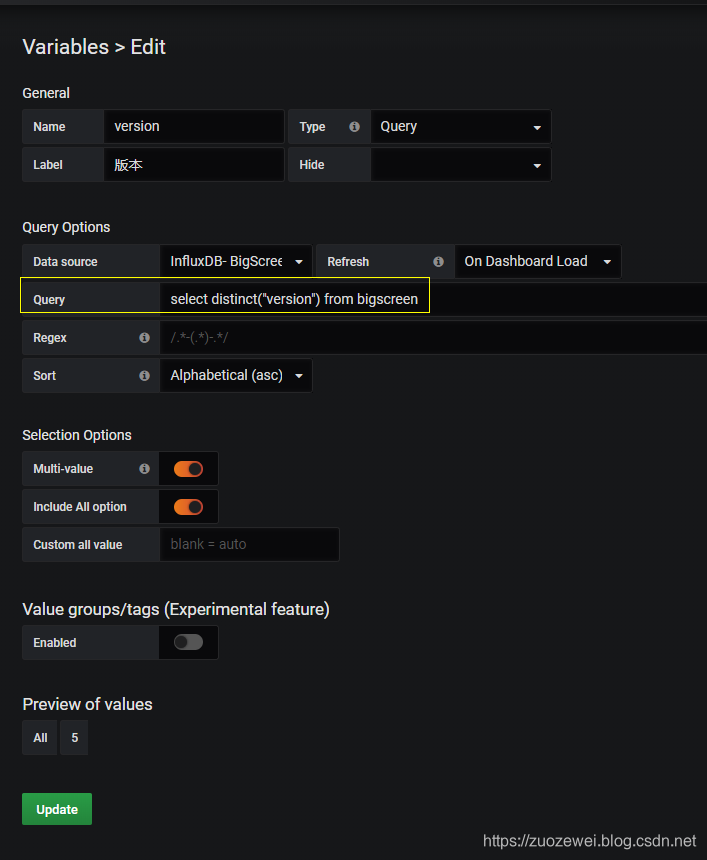
设置筛选变量,满足字段过滤筛选要求:


设置筛选变量,满足字段过滤筛选要求:
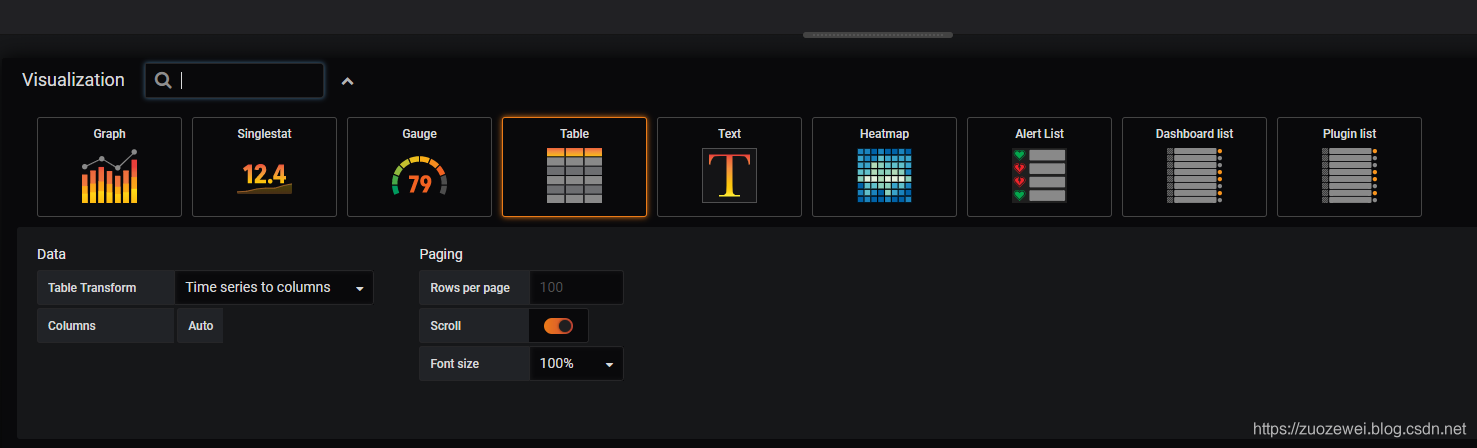
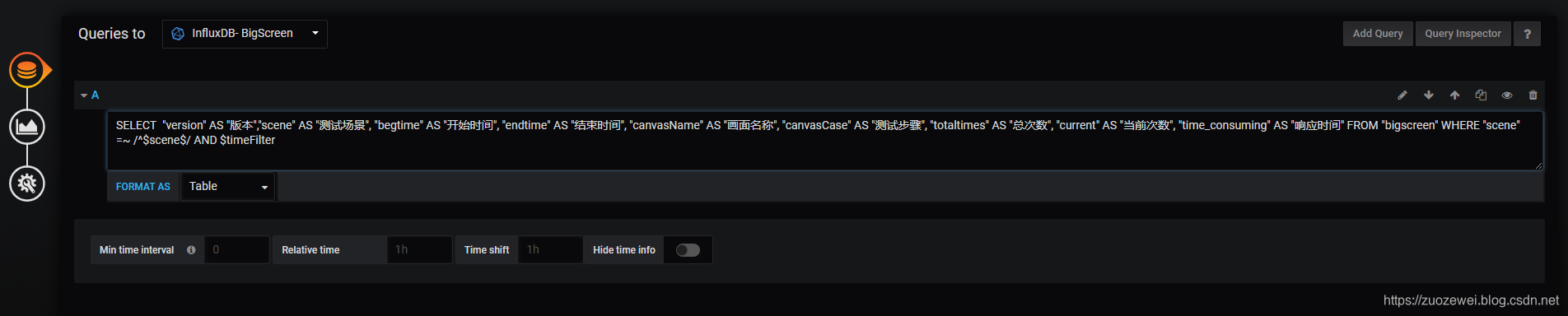
创建Dashboard,并选择表格组件:
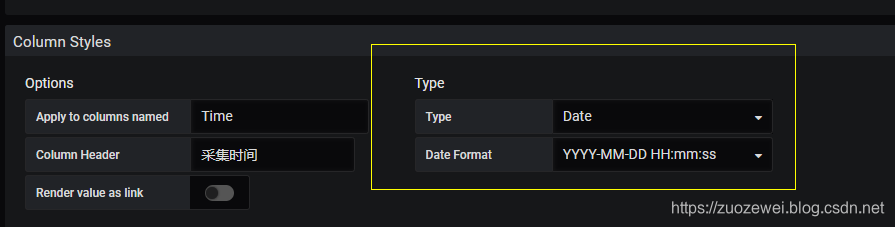
对响应时间字段进行不同级别高亮设置(绿,黄,红三个颜色)

实际的动态效果如下:
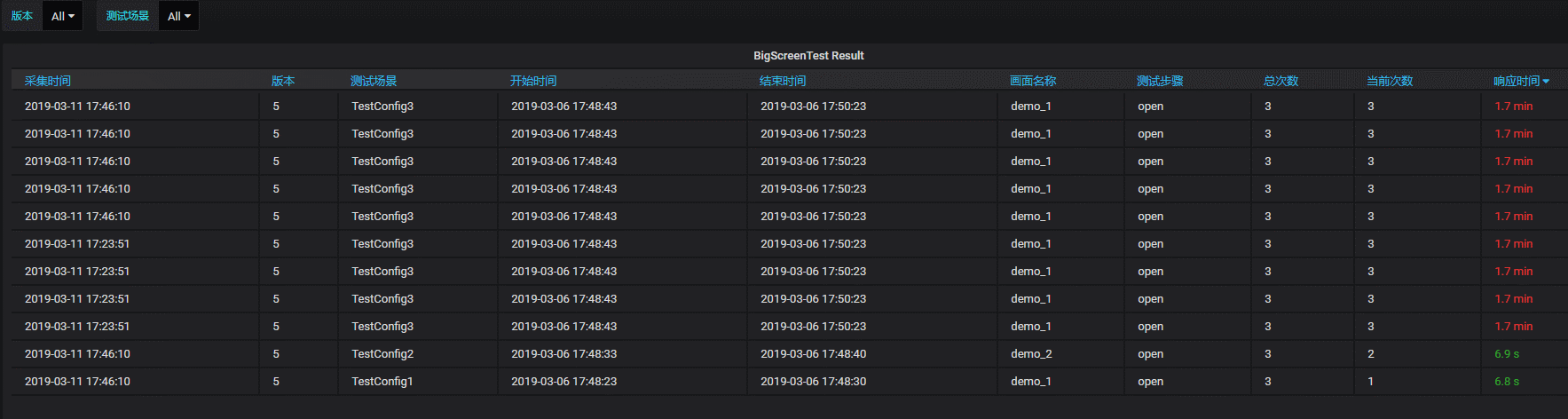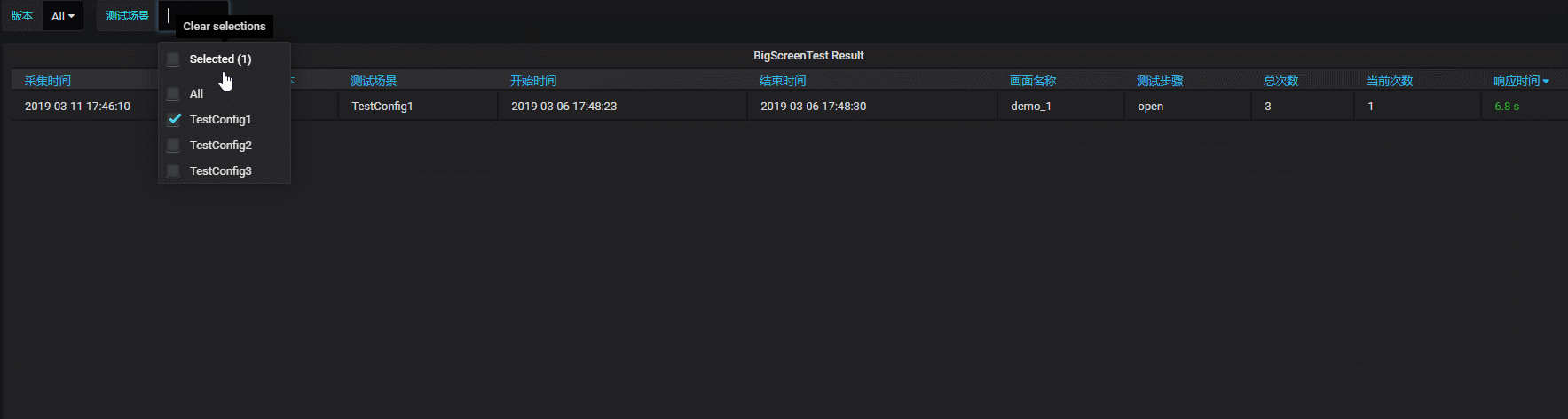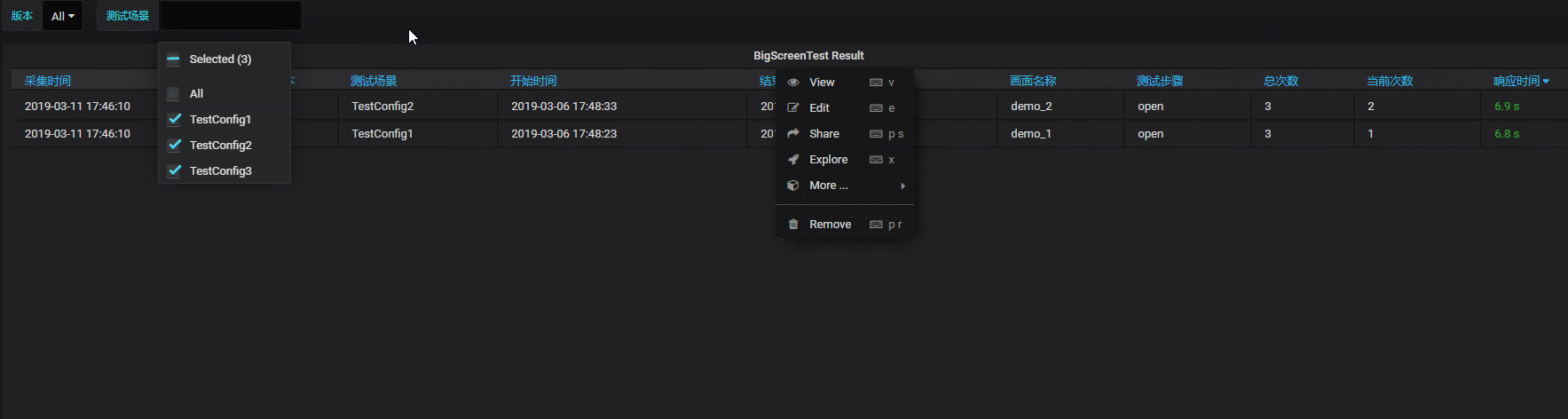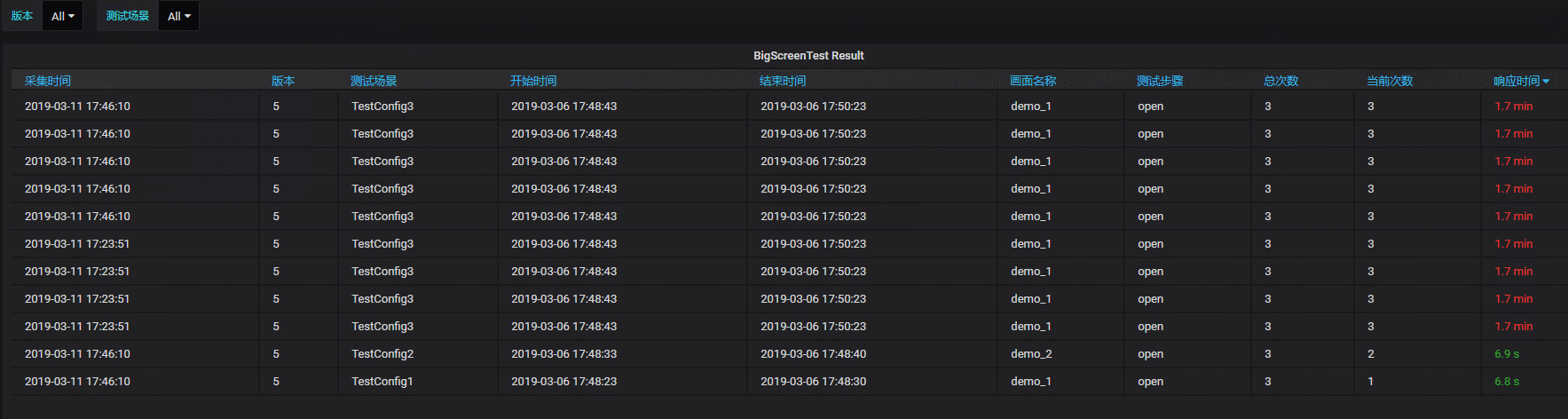
五、小结
本文通过一个简单的示例展示了 Telegraf+InfluxDB+Grafana 如何对结构化日志进行实时监控,当然也支持非结构化日志采集,大家有兴趣的话也可以自己动手实践。
相关资料:
https://github.com/zuozewei/blog-example/tree/master/Performance-testing/03-performance-monitoring/telegraf-Influxdb-grafana-jmx
posted on 2024-07-24 23:03 luzhouxiaoshuai 阅读(29) 评论(0) 编辑 收藏 举报


