kube-state-metrics常见监控指标
转载自博客:https://blog.csdn.net/qq_43751862/article/details/126410171
kube-state-metrics常见监控指标
pod
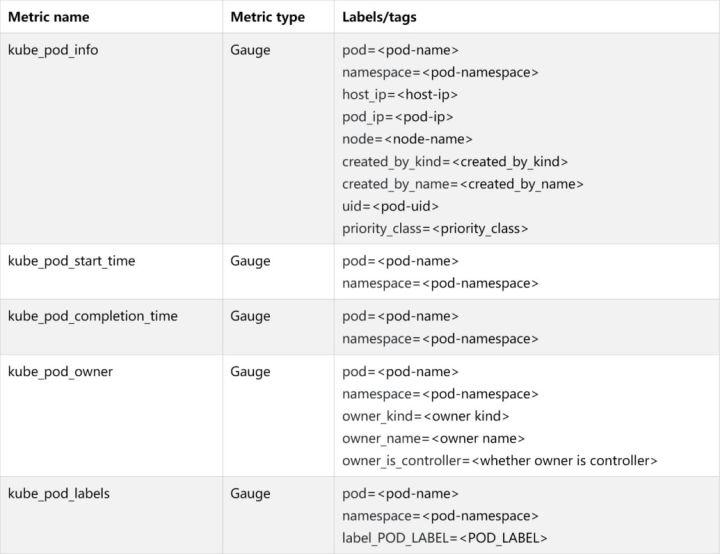
kube_pod_info # 有关pod的信息。 kube_pod_start_time # pod的unix时间戳记中的开始时间。 kube_pod_completion_time #pod的unix时间戳记中的完成时间。 kube_pod_owner # 有关Pod所有者的信息。 kube_pod_labels # Kubernetes标签转换为Prometheus标签。 kube_pod_status_phase # Pod当前阶段。 kube_pod_status_ready # 描述容器是否准备好处理请求。 kube_pod_status_scheduled # 描述pod的调度过程的状态。 kube_pod_container_info # 有关容器中container的信息。 kube_pod_container_status_waiting # 描述容器当前是否处于等待状态。 kube_pod_container_status_waiting_reason # 描述容器当前处于等待状态的原因。 kube_pod_container_status_running # 描述容器当前是否处于运行状态。 kube_pod_container_status_terminated # 描述容器当前是否处于终止状态。 kube_pod_container_status_terminated_reason # 描述容器当前处于终止状态的原因。 kube_pod_container_status_last_terminated_reason # 描述容器处于终止状态的最后原因。 kube_pod_container_status_ready # Describes whether the containers readiness check succeeded. kube_pod_container_status_restarts_total # 每个容器的容器重新启动次数。 kube_pod_container_resource_requests # 容器请求的请求资源数。 kube_pod_container_resource_limits # 容器请求的限制资源数量。 kube_pod_overhead kube_pod_created # Unix创建时间戳。 kube_pod_deletion_timestamp # Unix删除时间戳 kube_pod_restart_policy # 描述此pod使用的重新启动策略。 kube_pod_init_container_info # 有关Pod中init容器的信息。 kube_pod_init_container_status_waiting # ,描述初始化容器当前是否处于等待状态。 kube_pod_init_container_status_waiting_reason # Describes the reason the init container is currently in waiting state. kube_pod_init_container_status_running # 描述初始化容器当前是否处于运行状态。 kube_pod_init_container_status_terminated # 描述初始化容器当前是否处于终止状态。 kube_pod_init_container_status_terminated_reason # 描述初始化容器当前处于终止状态的原因。 kube_pod_init_container_status_last_terminated_reason # 描述初始化容器处于终止状态的最后原因。 kube_pod_init_container_status_ready # 描述初始化容器准备情况检查是否成功。 kube_pod_init_container_status_restarts_total #Counter类型,初始化容器的重新启动次数。 kube_pod_init_container_resource_limits # 初始化容器请求的限制资源数。 kube_pod_spec_volumes_persistentvolumeclaims_info # 有关Pod中持久卷声明卷的信息。 kube_pod_spec_volumes_persistentvolumeclaims_readonly # 描述是否以只读方式安装了持久卷声明。 kube_pod_status_reason # pod状态原因 kube_pod_status_scheduled_time # Pod移至计划状态时的Unix时间戳 kube_pod_status_unschedulable # 描述pod的unschedulable状态。
Deployment
kube_deployment_status_replicas #deployment包含的副本个数
kube_deployment_status_replicas_available #deployment的可用副本数
kube_deployment_status_replicas_unavailable #deployment中不可用副本的数量
kube_deployment_status_replicas_updated #deployment的更新副本数
kube_deployment_status_observed_generation #deployment控制器观察到的生成
kube_deployment_status_condition #部署的当前状态condition
kube_deployment_spec_replicas #deployment所需的Pod数
kube_deployment_spec_paused #deployment是否暂停,并且deployment控制器不会处理。
kube_deployment_spec_strategy_rollingupdate_max_surge #滚动更新deployment期间的最大不可用副本数。
kube_deployment_metadata_generation #代表期望状态的特定生成的序列号
kube_deployment_labels #Kubernetes标签转换为Prometheus标签
kube_deployment_created #Unix创建时间戳
StatefulSet
kube_statefulset_status_replicas # StatefulSet的副本数。 kube_statefulset_status_replicas_current # StatefulSet的当前副本数。 kube_statefulset_status_replicas_ready #StatefulSet的就绪副本数。 kube_statefulset_status_replicas_updated #StatefulSet的更新副本数。 kube_statefulset_status_observed_generation #StatefulSet控制器观察到的生成。 kube_statefulset_replicas #StatefulSet所需的pod数。 kube_statefulset_metadata_generation #表示StatefulSet所需状态的特定生成的序列号。 kube_statefulset_created #Unix创建时间戳。 kube_statefulset_labels #Kubernetes标签转换为Prometheus标签。 kube_statefulset_status_current_revision #指示用于按顺序[0,currentReplicas)生成Pod的StatefulSet的版本。 kube_statefulset_status_update_revision #指示用于按顺序[replicas-updatedReplicas,replicas]生成Pod的StatefulSet的版本
Endpoint
kube_endpoint_address_not_ready #endpoint中not ready的addresses数
kube_endpoint_address_available #endpoint中可用的addresses数
kube_endpoint_info #有关endpoint的信息
kube_endpoint_labels #Kubernetes标签转换为Prometheus标签
kube_endpoint_created #Unix创建时间戳
Node
kube_node_info # 有关群集节点的信息。
kube_node_labels # Kubernetes标签转换为Prometheus标签。
kube_node_role # 集群节点的角色。
kube_node_spec_unschedulable # 节点是否可以调度新的Pod。
kube_node_spec_taint # 群集节点的污点。
kube_node_status_capacity # 节点不同资源的容量。
kube_node_status_allocatable # 可用于调度的节点的不同资源的可分配资源。
kube_node_status_condition # 群集节点的状况。
kube_node_created # Unix创建时间戳。
Service
kube_service_info # 有关service的信息。
kube_service_labels # Kubernetes标签转换为Prometheus标签。
kube_service_created # Unix创建时间戳。
kube_service_spec_type # Type about service.
kube_service_spec_external_ip # 服务外部IP。 每个IP一个组。
kube_service_status_load_balancer_ingress # 服务负载均衡器入口状态
- 1
- 2
- 3
- 4
- 5
- 6
Secret
kube_secret_info # 有关secret的信息。
kube_secret_type # Type about secret.
kube_secret_labels # Kubernetes标签转换为Prometheus标签。
kube_secret_created # Unix创建时间戳。
kube_secret_metadata_resource_version # 代表secret特定版本的资源版本。
- 1
- 2
- 3
- 4
- 5
DaemonSet
kube_daemonset_created # Unix创建时间戳 kube_daemonset_status_current_number_scheduled # 运行至少一个且应该运行的守护程序容器的节点数。 kube_daemonset_status_desired_number_scheduled # 应该运行守护程序容器的节点数。 kube_daemonset_status_number_available # 应该运行守护程序容器并具有一个或多个守护程序容器正在运行并且可用的节点数 kube_daemonset_status_number_misscheduled # 运行守护程序容器但不应该运行的节点数。 kube_daemonset_status_number_ready # 应该运行守护程序容器并已运行一个或多个守护程序容器并准备就绪的节点数。 kube_daemonset_status_number_unavailable # 应该运行守护程序容器且没有任何守护程序容器正在运行并且可用的节点数 kube_daemonset_updated_number_scheduled # 正在运行更新的守护程序pod的节点总数 kube_daemonset_metadata_generation # 代表所需状态的特定生成的序列号。 kube_daemonset_labels # Kubernetes标签转换为Prometheus标签。
转载自博客2:https://segmentfault.com/a/1190000039800959
转自@twt社区,作者:李志伟
随着容器化、分布式的不断发展,业务系统的逻辑变得复杂,定位问题越来越困难,就需要从宿主机、容器管理平台和容器应用等多个层面进行监控,才可以定位性能问题、异常问题、安全问题等。本文介绍容器管理平台(k8s)的监控方法。
监控方式
容器类监控一般采用Prometheus进行监控,支持默认的pull模式获取数据,这也是官方推荐的方式。但是如果一些网络或防火墙等原因无法直接pull到数据的情况,就要借助Pushgateway让Prometheus转换为push方式获取数据;又比如我们将prometheus搭建在外网去监控内网应用的情况下,由于内网有诸多安全限制使得无法穿透,这时就要借助push模式来解决问题,还有就是监控的轮询监控大于被监控程序的执行时间,比如5秒pull一次数据,但是被监控程序1秒就执行完了。如下为pull和push的通用比较:
Pull
实时性取决于定时任务;客户端是有状态,需要知道拉取点,服务器端无状态,通常是短连接;难点实时性和流量的取舍。
Push
实时性较好;客户端无状态,服务器端有状态,需要了解每个客户端的推送点;通常是长链接;难点客户端能力和push能力不匹配问题。
K8s集群监控
使用系统命令查看kubectl top pod --all-namespaces
使用prometheus查询语句
`sum(kube_pod_container_resource_limits{resource="cpu", unit="core",
namespace="$Namespace"})`
CPU usage / available CPU in cluster
sum (rate (container_cpu_usage_seconds_total{namespace="$Namespace"}[1m])) / sum(machine_cpu_cores) * 100
Kube_namespaces_cpu_used_percent >80%
Kube_namespaces_memory_memused_bytes_percebt>80%
Kube_namespaces_requests_cpu_percent>80%
Kube_namespaces_requests_memory_percent>80%
Pod监控项
资源限制
spec:
containers:
imagePullPolicy: Always
name: kubernetes-serve-hostname
resources:
limits:
cpu: "1"
memory: 512Mi
requests:
cpu: "1"
memory: 512Mi
Pod Metrics



监控项举例:
Kube_pod_container_limit_cpu_cores>2
Node节点监控及告警
命令Kubectl get nodes
连续5分钟node状态是非ready,与master节点失联,最大告警2次
先检查状态
Systemctl status kubelet
Systemctl restart kubelet
守护进程(daemonset)监控
Kube_daemonset_statsu_number_unavailable>0 不可用pod数大于0
Kube_daemonset_current_number_normal==0 daemonset的pod与期望
Kube_daemonset_updated_number_normal==0 daemonset已更新与期望
守护进程监控项
无状态应用监控
Kube_deployment_status_replicas_unavailable>0 不可用副本数大于0
Kube_deployment_current_replicas_normal==0 当前副本数与期待副本数不一致
Kube_deployment_updated_replicas_normal==0 updateed副本数与期望副本数不一致。
Kubectl get deploy busybox
有状态应用监控
有状态核心告警
Kube_statefulset_replicas_ready_normal==0 副本是否与期望副本一致
Kube_statefulset_replicas_current_normal==0 当前副本与期望
查看未正常运行的pod的状态和事件,查看kubeclt deploy状态和事件
负载均衡器监控
应用访问通过ingress controller转发到ingress,再转发到具体的服务,最后转到具体的pod。因此ingress 监控至关重要。

URL、源IP、UserAgent、状态码、入流量、出流量、响应时间等,从这些信息中,我们能够分析出非常多的信息,例如:
1.网站访问的PV、UV;
2.网站访问的错误比例;
3.后端服务的响应延迟;
4.不同URL访问分布。
主要监控指标:


监控metric

事件监控
事件监控是Kubernetes中的另一种监控方式,可以弥补资源监控在实时性、准确性和场景上的缺欠。
Kubernetes的架构设计是基于状态机的,不同的状态之间进行转换则会生成相应的事件,正常的状态之间转
换会生成Normal等级的事件,正常状态与异常状态之间的转换会生成Warning等级的事件。通过获取事件,实时诊断集群的异常与问题。
Pod常见问题列表:
- ImagePullBackOff
- CrashLoopBackOff
- RunContainerError
- 处于Pending状态的Pod
- 处于未就绪状态的Pod
ImagePullBackOff
当Kubernetes无法获取到Pod中某个容器的镜像时,将出现此错误。
可能原因:
- 镜像名称无效,例如拼错镜像名称,或者镜像不存在。
- 您为image指定了不存在的标签。
- 您检索的镜像是私有registry,而Kubernetes没有凭据可以访问它。
解决方法:
- 前两种情况可以通过修改镜像名称和标记来解决该问题。
- 第三种情况,您需要将私有registry的访问凭证,通过Secret添加到Kubernetes中并在Pod中引用它。
CrashLoopBackOff
如果容器无法启动,则Kubernetes将显示错误状态为:CrashLoopBackOff。
可能原因:
- 应用程序中存在错误,导致无法启动。
- 未正确配置容器。
- Liveness探针失败太多次。
解决方法:
- 您可以尝试从该容器中检索日志以调查其失败的原因。如果容器重新启动太快而看不到日志,则可以使用命令:$ kubectl logs <pod-name>--previous。
RunContainerError
当容器无法启动时,出现此错误。
可能原因:
- 挂载不存在的卷,例如ConfigMap或Secrets。
- 将只读卷安装为可读写。
解决方法:
- 请使用kubectl describe pod命令收集和分析错误。
处于Pending状态的Pod
当创建应用时,在变更记录中该Pod一直Pending状态。
可能原因:
- 集群没有足够的资源(例如CPU和内存)来运行Pod。
- 当前的命名空间具有ResourceQuota对象,创建Pod将使命名空间超过配额。
- 该Pod绑定到一个处于pending状态的PersistentVolumeClaim。
解决方法:
- 检查$ kubectl describe pod<pod name>命令输出的“事件”部分内容或者在控制台查看应用事件。
- 对于因ResourceQuotas而导致的错误,可以使用$ kubectl get events--sort-by=.metadata.cre-ationTimestamp命令检查集群的日志。
处于未就绪状态的Pod
如果Pod正在运行但未就绪(not ready),则表示readiness就绪探针失败。
可能原因:
- 当“就绪”探针失败时,Pod未连接到服务,并且没有流量转发到该实例。
解决方法:
- 就绪探针失败是应用程序的特定错误,请检查$ kubectl describe pod<pod name>命令输出的“事件”部分内容,或者在控制台查看对应的应用事件。
监控指标阈值
推荐值

posted on 2023-07-19 20:39 luzhouxiaoshuai 阅读(5015) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号