

谷粒商城-分布式高级篇-ElasticSearch高级
116、全文检索-ElasticSearch-进阶-filter过滤[程序源码论坛www.cx1314.cn].mp4
117、全文检索-ElasticSearch-进阶-term查询[程序源码论坛www.cx1314.cn].mp4
不清楚的看视频


GET bank/_search { "query": { "match": { "address": "Mill" } }, "aggs": { "ageAgg": { "terms": { "field": "age", "size": 10 } }, "ageAvg": { "avg": { "field": "age" } }, "balanceAvg": { "avg": { "field": "balance" } } } } GET users/_search GET bank/_search { "query": { "match_all": {} }, "aggs": { "ageAgg": { "terms": { "field": "age", "size": 100 }, "aggs": { "ageAvg": { "avg": { "field": "balance" } } } } }, "size": 0 } GET bank/_search { "query": { "match_all": {} }, "aggs": { "ageAgg": { "terms": { "field": "age", "size": 100 }, "aggs": { "genderAgg": { "terms": { "field": "gender.keyword" }, "aggs": { "balanceAvg": { "avg": { "field": "balance" } } } }, "ageBalanceAvg": { "avg": { "field": "balance" } } } } }, "size": 0 } GET bank/_search { "query": { "match_all": { } }, "aggs": { "aggAge": { "terms": { "field": "age", "size": 100 }, "aggs": { "banlance": { "avg": { "field": "balance", "size": 10 } } } } } } PUT /my_index/_mapping { "properties": { "employee-id": { "type": "keyword", "index": false } } } PUT /newbank { "mappings": { "properties": { "account_number": { "type": "long" }, "address": { "type": "text" }, "age": { "type": "integer" }, "balance": { "type": "long" }, "city": { "type": "keyword" }, "email": { "type": "keyword" }, "employer": { "type": "keyword" }, "firstname": { "type": "text" }, "gender": { "type": "keyword" }, "lastname": { "type": "text", "fields": { "keyword": { "type": "keyword", "ignore_above": 256 } } }, "state": { "type": "keyword" } } } } GET /newbank/_search POST _reindex { "source": { "index": "bank", "type": "account" }, "dest": { "index": "newbank" } } GET /my_index PUT /my_index { "mappings": { "properties": { "age": { "type": "integer" }, "email": { "type": "keyword" }, "name": { "type": "text" }, "employee-id": { "type": "keyword", "index": false } } } } GET my_index/_search { "query": { "bool": { "must": [ { "match": { "user.first": "Alice" }}, { "match": { "user.last": "Smith" }} ] } } } GET bank/_mapping GET member/_mapping PUT my_index/_doc/1 { "group" : "fans", "user" : [ { "first" : "John", "last" : "Smith" }, { "first" : "Alice", "last" : "White" } ] } PUT product { "mappings":{ "properties": { "skuId":{ "type": "long" }, "spuId":{ "type": "keyword" }, "skuTitle": { "type": "text", "analyzer": "ik_smart" }, "skuPrice": { "type": "keyword" }, "skuImg":{ "type": "keyword", "index": false, "doc_values": false }, "saleCount":{ "type":"long" }, "hasStock": { "type": "boolean" }, "hotScore": { "type": "long" }, "brandId": { "type": "long" }, "catalogId": { "type": "long" }, "brandName": { "type": "keyword", "index": false, "doc_values": false }, "brandImg":{ "type": "keyword", "index": false, "doc_values": false }, "catalogName": { "type": "keyword", "index": false, "doc_values": false }, "attrs": { "type": "nested", "properties": { "attrId": { "type": "long" }, "attrName": { "type": "keyword", "index": false, "doc_values": false }, "attrValue": { "type": "keyword" } } } } } }
转载自博客:https://blog.csdn.net/hancoder/article/details/113922398
https://www.elastic.co/guide/en/elasticsearch/reference/7.x/getting-started-search.html
https://github.com/elastic/elasticsearch/blob/master/docs/src/test/resources/accounts.json
GET /bank/_search { "query": { "match_all": {} }, "sort": [ { "account_number": "asc" }, { "balance":"desc"} ] }
POSTMAN中get不能携带请求体,我们变为post也是一样的,我们post一个jsob风格的查询请求体到_search
需要了解,一旦搜索的结果被返回,es就完成了这次请求,不能切不会维护任何服务端的资源或者结果的cursor游标
3.2)DSL领域特定语言
这节教我们如何写复杂查询
Elasticsearch提供了一个可以执行查询的Json风格的DSL(domain-specific language领域特定语言)。这个被称为Query DSL,该查询语言非常全面。
(1)基本语法格式
一个查询语句的典型结构
示例 使用时不要加#注释内容 GET bank/_search { "query": { # 查询的字段 "match_all": {} }, "from": 0, # 从第几条文档开始查 "size": 5, "_source":["balance"], "sort": [ { "account_number": { # 返回结果按哪个列排序 "order": "desc" # 降序 } } ] } _source为要返回的字段
GET bank/_search { "query": { "match_all": {} }, "from": 0, "size": 5, "_source":["balance"], "sort": [ { "account_number": { "order": "desc" } } ] }
返回的结果为

query定义如何查询;
match_all查询类型【代表查询所有的索引】,es中可以在query中组合非常多的查询类型完成复杂查询;
除了query参数之外,我们可也传递其他的参数以改变查询结果,如sort,size;
from+size限定,完成分页功能;
sort排序,多字段排序,会在前序字段相等时后续字段内部排序,否则以前序为准;
(2)from返回部分字段
GET bank/_search { "query": { "match_all": {} }, "from": 0, "size": 5, "sort": [ { "account_number": { "order": "desc" } } ], "_source": ["balance","firstname"] }
返回结果
{ "took" : 3, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 1001, "relation" : "eq" }, "max_score" : null, "hits" : [ { "_index" : "bank", "_type" : "account", "_id" : "999", "_score" : null, "_source" : { "firstname" : "Dorothy", "balance" : 6087 }, "sort" : [ 999 ] }, { "_index" : "bank", "_type" : "account", "_id" : "998", "_score" : null, "_source" : { "firstname" : "Letha", "balance" : 16869 }, "sort" : [ 998 ] },
(3)query/match匹配查询
如果是非字符串,会进行精确匹配。如果是字符串,会进行全文检索
- 基本类型(非字符串),精确控制
首先看下bank索引的mapping结构
{ "bank" : { "mappings" : { "properties" : { "account_number" : { "type" : "long" }, "address" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, "age" : { "type" : "long" }, "balance" : { "type" : "long" }, "city" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, "email" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, "employer" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, "firstname" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, "gender" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, "lastname" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, "state" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } } } } } }
account_number非文本类型,精确查询
GET bank/_search { "query": { "match": { "account_number": "20" } } }
返回结果为
{ "took" : 4, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 1, "relation" : "eq" }, "max_score" : 1.0, "hits" : [ { "_index" : "bank", "_type" : "account", "_id" : "20", "_score" : 1.0, "_source" : { "account_number" : 20, "balance" : 16418, "firstname" : "Elinor", "lastname" : "Ratliff", "age" : 36, "gender" : "M", "address" : "282 Kings Place", "employer" : "Scentric", "email" : "elinorratliff@scentric.com", "city" : "Ribera", "state" : "WA" } } ] } }
字符串,全文检索,全文检索,最终会按照评分进行排序,会对检索条件进行分词匹配。 match会将检索条件进行分词操作去检索
GET bank/_search { "query": { "match": { "address": "kings" } } }
地址addres中包涵king的有多少条,返回的结果是4条
{ "took" : 3, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 2, "relation" : "eq" }, "max_score" : 5.991829, "hits" : [ { "_index" : "bank", "_type" : "account", "_id" : "20", "_score" : 5.991829, "_source" : { "account_number" : 20, "balance" : 16418, "firstname" : "Elinor", "lastname" : "Ratliff", "age" : 36, "gender" : "M", "address" : "282 Kings Place", "employer" : "Scentric", "email" : "elinorratliff@scentric.com", "city" : "Ribera", "state" : "WA" } }, { "_index" : "bank", "_type" : "account", "_id" : "722", "_score" : 5.991829, "_source" : { "account_number" : 722, "balance" : 27256, "firstname" : "Roberts", "lastname" : "Beasley", "age" : 34, "gender" : "F", "address" : "305 Kings Hwy", "employer" : "Quintity", "email" : "robertsbeasley@quintity.com", "city" : "Hayden", "state" : "PA" } } ] } }
地址addres中包涵king或者place的有多少条,返回的结果是128条,这里match会将检索调整进行分词操作,分词为king和place,只有内容中的文波分词后包涵一个king或者place就能够匹配,查询出来
GET bank/_search { "query": { "match": { "address": "kings place" } } }
查看的返回结果为128条


4) query/match_phrase [不拆分匹配]
将需要匹配的值当成一整个单词(不分词)进行检索
match_phrase:不拆分字符串进行检索字段.keyword:必须全匹配上才检索成功
前面的是包含mill或road就查出来,我们现在要都包含才查出,将mill road在查询的时候作为一个整个短语去查询,不进行分词操作,只有address中的内容中分词后有mill road这个的内容才能匹配上,我们来看下面的这个操作
match_phrase 称为短语搜索,要求所有的分词必须同时出现在文档中,同时位置必须紧邻一致。
GET bank/_search { "query": { "match_phrase": { "address": "king street" } } }查询的结果只有一条,要求所有的分词必须同时出现在文档中,同时位置必须紧邻一致。
{ "took" : 2, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 1, "relation" : "eq" }, "max_score" : 7.457467, "hits" : [ { "_index" : "bank", "_type" : "account", "_id" : "700", "_score" : 7.457467, "_source" : { "account_number" : 700, "balance" : 19164, "firstname" : "Patel", "lastname" : "Durham", "age" : 21, "gender" : "F", "address" : "440 King Street", "employer" : "Icology", "email" : "pateldurham@icology.com", "city" : "Mammoth", "state" : "IL" } } ] } }
"440 King Street"文本分词之后为404 king street,并且分词之后
King 和Street必须相邻,才能被match_phase匹配到

GET bank/_search { "query": { "match_phrase": { "address": "mill road" # 就是说不要匹配只有mill或只有road的,要匹配mill road一整个子串 } } }
查处address中包含mill road的所有记录,并给出相关性得分
查看结果:
{ "took" : 2, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 1, "relation" : "eq" }, "max_score" : 8.928605, "hits" : [ { "_index" : "bank", "_type" : "account", "_id" : "970", "_score" : 8.928605, "_source" : { "account_number" : 970, "balance" : 19648, "firstname" : "Forbes", "lastname" : "Wallace", "age" : 28, "gender" : "M", "address" : "990 Mill Road", "employer" : "Pheast", "email" : "forbeswallace@pheast.com", "city" : "Lopezo", "state" : "AK" } } ] } }
文本字段的匹配,使用keyword,匹配的条件就是要显示字段的全部值,要进行精确匹配的。
match_phrase是做短语匹配,只要文本中包含匹配条件,就能匹配到。
我们来看下面的这个案例
match_phrase和match的区别,观察如下实例:
GET bank/_search { "query": { "match_phrase": { "address": "990 Mill" } } }
查询结果为:
{ "took" : 2, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 1, "relation" : "eq" }, "max_score" : 10.808405, "hits" : [ { "_index" : "bank", "_type" : "account", "_id" : "970", "_score" : 10.808405, "_source" : { "account_number" : 970, "balance" : 19648, "firstname" : "Forbes", "lastname" : "Wallace", "age" : 28, "gender" : "M", "address" : "990 Mill Road", "employer" : "Pheast", "email" : "forbeswallace@pheast.com", "city" : "Lopezo", "state" : "AK" } } ] } }
使用match的keyword
GET bank/_search { "query": { "match": { "address.keyword": "990 Mill" } } }
查询结果,一条也未匹配到
{ "took" : 1, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 0, "relation" : "eq" }, "max_score" : null, "hits" : [ ] } }
修改匹配条件为“990 Mill Road”
GET bank/_search { "query": { "match": { "address.keyword": "990 Mill Road" } } }
返回的查询结果为:
{ "took" : 1, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 1, "relation" : "eq" }, "max_score" : 6.5042877, "hits" : [ { "_index" : "bank", "_type" : "account", "_id" : "970", "_score" : 6.5042877, "_source" : { "account_number" : 970, "balance" : 19648, "firstname" : "Forbes", "lastname" : "Wallace", "age" : 28, "gender" : "M", "address" : "990 Mill Road", "employer" : "Pheast", "email" : "forbeswallace@pheast.com", "city" : "Lopezo", "state" : "AK" } } ] } }
文本字段的匹配,使用keyword,匹配的条件就是要显示字段的全部值,要进行精确匹配的。
match_phrase是做短语匹配,只要文本中包含匹配条件,就能匹配到。
(5)query/multi_math【多字段匹配】
state或者address中包含mill,并且在查询过程中,会对于查询条件进行分词。
GET bank/_search { "query": { "multi_match": { # 前面的match仅指定了一个字段。 "query": "mill", "fields": [ # state和address有mill子串 不要求都有 "state", "address" ] } } }
查询结果:
{ "took" : 28, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 4, "relation" : "eq" }, "max_score" : 5.4032025, "hits" : [ { "_index" : "bank", "_type" : "account", "_id" : "970", "_score" : 5.4032025, "_source" : { "account_number" : 970, "balance" : 19648, "firstname" : "Forbes", "lastname" : "Wallace", "age" : 28, "gender" : "M", "address" : "990 Mill Road", # 有mill "employer" : "Pheast", "email" : "forbeswallace@pheast.com", "city" : "Lopezo", "state" : "AK" # 没有mill } }, { "_index" : "bank", "_type" : "account", "_id" : "136", "_score" : 5.4032025, "_source" : { "account_number" : 136, "balance" : 45801, "firstname" : "Winnie", "lastname" : "Holland", "age" : 38, "gender" : "M", "address" : "198 Mill Lane", # mill "employer" : "Neteria", "email" : "winnieholland@neteria.com", "city" : "Urie", "state" : "IL" # 没有mill } }, { "_index" : "bank", "_type" : "account", "_id" : "345", "_score" : 5.4032025, "_source" : { "account_number" : 345, "balance" : 9812, "firstname" : "Parker", "lastname" : "Hines", "age" : 38, "gender" : "M", "address" : "715 Mill Avenue", # "employer" : "Baluba", "email" : "parkerhines@baluba.com", "city" : "Blackgum", "state" : "KY" # 没有mill } }, { "_index" : "bank", "_type" : "account", "_id" : "472", "_score" : 5.4032025, "_source" : { "account_number" : 472, "balance" : 25571, "firstname" : "Lee", "lastname" : "Long", "age" : 32, "gender" : "F", "address" : "288 Mill Street", # "employer" : "Comverges", "email" : "leelong@comverges.com", "city" : "Movico", "state" : "MT" # 没有mill } } ] } }
(6)query/bool/must复合查询
复合语句可以合并,任何其他查询语句,包括符合语句。这也就意味着,复合语句之间可以互相嵌套,可以表达非常复杂的逻辑。
must:必须达到must所列举的所有条件
must_not:必须不匹配must_not所列举的所有条件。
should:应该满足should所列举的条件。满足条件最好,不满足也可以,满足得分更高
实例:查询gender=m,并且address=mill的数据
GET bank/_search { "query":{ "bool":{ # "must":[ # 必须有这些字段 {"match":{"address":"mill"}}, {"match":{"gender":"M"}} ] } } }
{ "took" : 1, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 3, "relation" : "eq" }, "max_score" : 6.0824604, "hits" : [ { "_index" : "bank", "_type" : "account", "_id" : "970", "_score" : 6.0824604, "_source" : { "account_number" : 970, "balance" : 19648, "firstname" : "Forbes", "lastname" : "Wallace", "age" : 28, "gender" : "M", # M "address" : "990 Mill Road", # mill "employer" : "Pheast", "email" : "forbeswallace@pheast.com", "city" : "Lopezo", "state" : "AK" } }, { "_index" : "bank", "_type" : "account", "_id" : "136", "_score" : 6.0824604, "_source" : { "account_number" : 136, "balance" : 45801, "firstname" : "Winnie", "lastname" : "Holland", "age" : 38, "gender" : "M", # "address" : "198 Mill Lane", # "employer" : "Neteria", "email" : "winnieholland@neteria.com", "city" : "Urie", "state" : "IL" } }, { "_index" : "bank", "_type" : "account", "_id" : "345", "_score" : 6.0824604, "_source" : { "account_number" : 345, "balance" : 9812, "firstname" : "Parker", "lastname" : "Hines", "age" : 38, "gender" : "M", # "address" : "715 Mill Avenue", # "employer" : "Baluba", "email" : "parkerhines@baluba.com", "city" : "Blackgum", "state" : "KY" } } ] } }
must_not:必须不是指定的情况
实例:查询gender=m,并且address=mill的数据,但是age不等于38的
should:应该达到should列举的条件,如果到达会增加相关文档的评分,并不会改变查询的结果。如果query中只有should且只有一种匹配规则,那么should的条件就会被作为默认匹配条件二区改变查询结果。
实例:匹配lastName应该等于Wallace的数据
GET bank/_search { "query": { "bool": { "must": [ { "match": { "gender": "M" } }, { "match": { "address": "mill" } } ], "must_not": [ { "match": { "age": "18" } } ], "should": [ { "match": { "lastname": "Wallace" } } ] } } }
查询结果:
{ "took" : 5, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 3, "relation" : "eq" }, "max_score" : 12.585751, "hits" : [ { "_index" : "bank", "_type" : "account", "_id" : "970", "_score" : 12.585751, "_source" : { "account_number" : 970, "balance" : 19648, "firstname" : "Forbes", "lastname" : "Wallace", # 因为匹配了should,所以得分第一 "age" : 28, # 不是18 "gender" : "M", # "address" : "990 Mill Road", # "employer" : "Pheast", "email" : "forbeswallace@pheast.com", "city" : "Lopezo", "state" : "AK" } }, { "_index" : "bank", "_type" : "account", "_id" : "136", "_score" : 6.0824604, "_source" : { "account_number" : 136, "balance" : 45801, "firstname" : "Winnie", "lastname" : "Holland", "age" : 38, "gender" : "M", "address" : "198 Mill Lane", "employer" : "Neteria", "email" : "winnieholland@neteria.com", "city" : "Urie", "state" : "IL" } }, { "_index" : "bank", "_type" : "account", "_id" : "345", "_score" : 6.0824604, "_source" : { "account_number" : 345, "balance" : 9812, "firstname" : "Parker", "lastname" : "Hines", "age" : 38, "gender" : "M", "address" : "715 Mill Avenue", "employer" : "Baluba", "email" : "parkerhines@baluba.com", "city" : "Blackgum", "state" : "KY" } } ] } }
7)query/filter【结果过滤】
must 贡献得分
should 贡献得分
must_not 不贡献得分
filter 不贡献得分
上面的must和should影响相关性得分,而must_not仅仅是一个filter ,不贡献得分
must改为filter就使must不贡献得分
如果只有filter条件的话,我们会发现得分都是0
一个key多个值可以用terms
并不是所有的查询都需要产生分数,特别是哪些仅用于filtering过滤的文档。为了不计算分数,elasticsearch会自动检查场景并且优化查询的执行。
不参与评分更快
GET bank/_search { "query": { "bool": { "must": [ { "match": {"address": "mill" } } ], "filter": { # query.bool.filter "range": { "balance": { # 哪个字段 "gte": "10000", "lte": "20000" } } } } } }
这里先是查询所有匹配address=mill的文档,然后再根据10000<=balance<=20000进行过滤查询结果
查询结果:
{ "took" : 2, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 1, "relation" : "eq" }, "max_score" : 5.4042025, "hits" : [ { "_index" : "bank", "_type" : "account", "_id" : "970", "_score" : 5.4042025, "_source" : { "account_number" : 970, "balance" : 19648, "firstname" : "Forbes", "lastname" : "Wallace", "age" : 28, "gender" : "M", "address" : "990 Mill Road", "employer" : "Pheast", "email" : "forbeswallace@pheast.com", "city" : "Lopezo", "state" : "AK" } } ] } }

must should会计算score得分,filter作为结果过滤不会参与score的计算,must_not作为一个特殊的fliter,也不会参与socre得分计算
filter在使用过程中,并不会计算相关性得分:
(8)query/term
和match一样。匹配某个属性的值。
term:代表完全匹配,也就是精确查询,搜索前不会再对搜索词进行分词解析,直接对搜索词进行查找;
match:代表模糊匹配,搜索前会对搜索词进行分词解析,然后按搜索词匹配查找;
一般模糊查找的时候,多用match,而精确查找时可以使用term。
GET bank/_search { "query": { "term": { "address": "mill Road" } } }

我们使用下面的几个场景来进行查询,address是text类型,使用term和match 、match_phase mtach对于的keyword来进行查询
使用term匹配查询
GET bank/_search { "query": { "term": { "address": "mill Road" } } }
返回结果为null
{ "took" : 2, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 0, "relation" : "eq" }, "max_score" : null, "hits" : [ ] } }
使用term查询,字段带上keyword查询
GET bank/_search { "query": { "term": { "address": "990 Mill Road" } } }
查询的结果也是为null,因为term是精确匹配,"address": "990 Mill Road"分词之后,分词为900 、Mill 、Road三个词语,没有分成完整的990 Mill Road这个分词,所以term去查询的时候,查询不到
但是match_phase短语查询,能够查询得到返回,分词为900 、Mill 、Road三个词语,但是只有这个三个分词是相邻的作为一个相邻的短语,match_phase就能够查询得到,我们来看下返回结果
GET bank/_search { "query": { "match_phrase": { "address": "990 Mill Road" } } }
返回的结果为
{ "took" : 1, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 1, "relation" : "eq" }, "max_score" : 14.332808, "hits" : [ { "_index" : "bank", "_type" : "account", "_id" : "970", "_score" : 14.332808, "_source" : { "account_number" : 970, "balance" : 19648, "firstname" : "Forbes", "lastname" : "Wallace", "age" : 28, "gender" : "M", "address" : "990 Mill Road", "employer" : "Pheast", "email" : "forbeswallace@pheast.com", "city" : "Lopezo", "state" : "AK" } } ] } }
所以这里一定要注意
案例2:
erm查询是直接通过倒排索引指定的词条进行查找的,所以,很显然,term查询效率肯定比match要高。
首先创建一个索引member,并插入几条测试数据,相关命令如下:
PUT /member/info/1 { "name": "张三", "age": 20 } PUT /member/info/2 { "name": "张无忌", "age": 50 } PUT /member/info/3 { "name": "李四", "age": 30 }
插入完成,观察索引里面的数据,如下图所示:

- 查询name中精确匹配"张"的数据
GET /member/info/_search { "query": { "term": { "name": "张" } } }

由上图可见,两条数据都能查询出来,只要name里包含"张"关键字的数据都查出来了 。因为张三分词为张、三,张无忌分词为张、无、忌。所以能够查询出来
如果我们只想精确匹配"张三"这个词,来看看下面的例子。
- 查询name中精确匹配"张三"的数据
GET /member/info/_search { "query": { "term": { "name": "张三" } } }

我们发现,查询出来显示无数据,从概念上看,term属于精确匹配,分词的结果中张三分词为张和三两种类型,没有张三,term是精确查询,只有分词结果包括张三才有结果返回,所以这里为null
如果我们想通过term匹配多个词的话,可以使用terms来实现:
GET /member/info/_search
{
"query": {
"terms": {
"name": ["张","三"]
}
}
}

可以看到,两条数据都成功返回,因为terms里的[ ] 多个搜索词之间是or(或者)关系,只要满足其中一个词即可。
如果我们想要同时满足两个词精确匹配的话,就得使用bool的must来做,如下:
GET /member/info/_search { "query": { "bool": { "must": [ { "term": { "name": "张" } }, { "term": { "name": "三" } } ] } } }

可以看到,此时只会返回一条满足条件的记录。
由于前面我们创建索引库member时并没有指定字段的类型,都是es默认生成的类型。

可以看到,默认生成的name字段是text类型。
下面我们看看是如何进行分词处理的?
GET member/_analyze { "text" : "张三" }

分析出来的为"张"和"三"的两个词,而term只能完完整整的匹配上面的词,不做任何改变的匹配。
text:查询时会进行分词解析;
keyword:keyword类型的词不会被分词器进行解析,直接作为整体进行查询;
下面我们通过简单的示例说明一下text和keyword的区别。我们先创建一个test索引库:
PUT /test { "mappings": { "properties": { "name": { "type": "text" }, "desc": { "type": "keyword" } } } }

下面我们插入几条测试数据:

PUT /test/_doc/1 { "name":"马士兵java name", "desc": "马士兵java desc" } PUT /test/_doc/2 { "name":"马士兵java name", "desc": "马士兵java desc2" }

查看test索引库信息,可以看到我们指定的mappings,如下图:
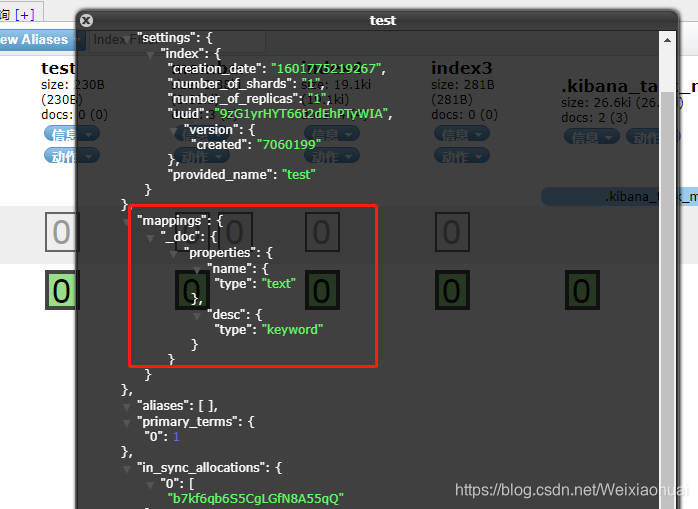
- 通过keyword类型的分词器进行解析
GET _analyze { "analyzer": "keyword", "text":"马士兵java name" }

GET test/_search { "query": { "term": { "desc": "马士兵java desc" } } }
查询返回的结果为:
{ "took" : 2, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 1, "relation" : "eq" }, "max_score" : 0.6931471, "hits" : [ { "_index" : "test", "_type" : "_doc", "_id" : "1", "_score" : 0.6931471, "_source" : { "name" : "马士兵java name", "desc" : "马士兵java desc" } } ] } }
可以看到,只返回一条记录,原因是desc字段是keyword类型,查询时候不会被分词器进行解析,作为一个整体查询。
keyword类型的字段不会被分词器解析,text类型的字段会被分词拆分后才进行查询。
{ "took" : 1, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 3, "relation" : "eq" }, "max_score" : 6.0824604, "hits" : [ { "_index" : "bank", "_type" : "account", "_id" : "970", "_score" : 6.0824604, "_source" : { "account_number" : 970, "balance" : 19648, "firstname" : "Forbes", "lastname" : "Wallace", "age" : 28, "gender" : "M", # M "address" : "990 Mill Road", # mill "employer" : "Pheast", "email" : "forbeswallace@pheast.com", "city" : "Lopezo", "state" : "AK" } }, { "_index" : "bank", "_type" : "account", "_id" : "136", "_score" : 6.0824604, "_source" : { "account_number" : 136, "balance" : 45801, "firstname" : "Winnie", "lastname" : "Holland", "age" : 38, "gender" : "M", # "address" : "198 Mill Lane", # "employer" : "Neteria", "email" : "winnieholland@neteria.com", "city" : "Urie", "state" : "IL" } }, { "_index" : "bank", "_type" : "account", "_id" : "345", "_score" : 6.0824604, "_source" : { "account_number" : 345, "balance" : 9812, "firstname" : "Parker", "lastname" : "Hines", "age" : 38, "gender" : "M", # "address" : "715 Mill Avenue", # "employer" : "Baluba", "email" : "parkerhines@baluba.com", "city" : "Blackgum", "state" : "KY" } } ] }}

posted on 2023-04-05 18:05 luzhouxiaoshuai 阅读(62) 评论(0) 编辑 收藏 举报


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!