

谷粒商城 分布式高级篇-全文检索-ElasticSearch-进阶-term查询 match查询的区别
转载自博客:https://blog.csdn.net/Weixiaohuai/article/details/108916014
一、简介
在elasticsearch中,查询主要使用到两个:term和match,本篇文章将总结一下两者的区别。
term:代表完全匹配,也就是精确查询,搜索前不会再对搜索词进行分词解析,直接对搜索词进行查找;
match:代表模糊匹配,搜索前会对搜索词进行分词解析,然后按搜索词匹配查找;
一般模糊查找的时候,多用match,而精确查找时可以使用term。
二、term精确匹配
term查询是直接通过倒排索引指定的词条进行查找的,所以,很显然,term查询效率肯定比match要高。
首先创建一个索引member,并插入几条测试数据,相关命令如下:

PUT /member/info/1 { "name": "张三", "age": 20 } PUT /member/info/2 { "name": "张无忌", "age": 50 } PUT /member/info/3 { "name": "李四", "age": 30 }
插入完成,观察索引里面的数据,如下图所示:

- 查询name中精确匹配"张"的数据
GET /member/info/_search { "query": { "term": { "name": "张" } } }

由上图可见,两条数据都能查询出来,只要name里包含"张"关键字的数据都查出来了 。
如果我们只想精确匹配"张三"这个词,来看看下面的例子。
- 查询name中精确匹配"张三"的数据
GET /member/info/_search { "query": { "term": { "name": "张三" } } }

我们发现,查询出来显示无数据,从概念上看,term属于精确匹配,只能查单个词。
如果我们想通过term匹配多个词的话,可以使用terms来实现:
GET /member/info/_search { "query": { "terms": { "name": ["张","三"] } } }

可以看到,两条数据都成功返回,因为terms里的[ ] 多个搜索词之间是or(或者)关系,只要满足其中一个词即可。
如果我们想要同时满足两个词精确匹配的话,就得使用bool的must来做,如下:
GET /member/info/_search { "query": { "bool": { "must": [ { "term": { "name": "张" } }, { "term": { "name": "三" } } ] } } }

可以看到,此时只会返回一条满足条件的记录。
由于前面我们创建索引库member时并没有指定字段的类型,都是es默认生成的类型。

可以看到,默认生成的name字段是text类型。
下面我们看看是如何进行分词处理的?
GET member/_analyze { "text" : "张三" }

分析出来的为"张"和"三"的两个词,而term只能完完整整的匹配上面的词,不做任何改变的匹配。
扩展: 两种数据类型:text和keyword
text:查询时会进行分词解析;
keyword:keyword类型的词不会被分词器进行解析,直接作为整体进行查询;
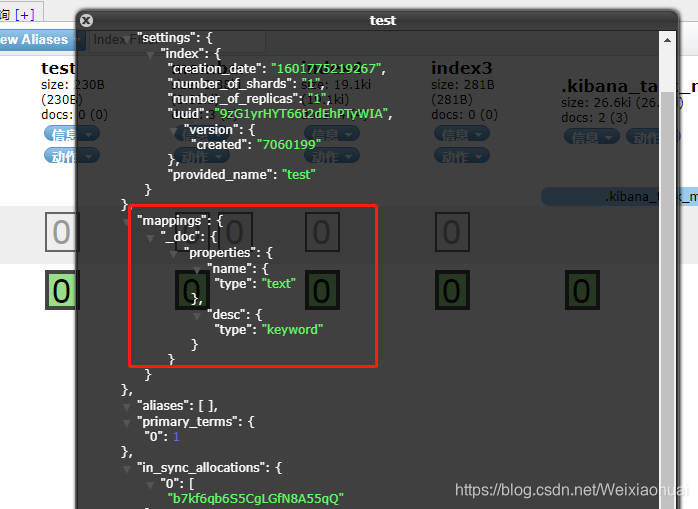
下面我们通过简单的示例说明一下text和keyword的区别。我们先创建一个test索引库:
PUT /test { "mappings": { "properties": { "name": { "type": "text" }, "desc": { "type": "keyword" } } } }

下面我们插入几条测试数据:
PUT /test/_doc/1 { "name":"马士兵java name", "desc": "马士兵java desc" } PUT /test/_doc/2 { "name":"马士兵java name", "desc": "马士兵java desc2" }

查看test索引库信息,可以看到我们指定的mappings,如下图:
- 通过keyword类型的分词器进行解析
GET _analyze { "analyzer": "keyword", "text":"马士兵java name" }

可以看到,因为name字段是text类型,查询时候会被分词器分析,所以两条记录都成功查询出来。
- 查询desc字段中含有"马士兵java desc"的记录
-

GET test/_search { "query": { "term": { "desc": "马士兵java desc" } } }

可以看到,只返回一条记录,原因是desc字段是keyword类型,查询时候不会被分词器进行解析,作为一个整体查询。
keyword类型的字段不会被分词器解析,text类型的字段会被分词拆分后才进行查询。
三、match模糊匹配
查询姓名中匹配含"张三"这个词的数据
GET member/info/_search { "query": { "match": { "name": "张三" } } }

通过上图,我们可以看到两条记录都被查询出来的,因为match进行搜索的时候,会先进行分词拆分,拆完后,再来匹配。
"张三"被拆分解析为"张"和"三"两个词,所以只要name字段中包含"张"或者"三"的数据都能够匹配上。
如果想 "张"和"三"同时匹配到的话,那么可以使用 match_phrase,来看下面的例子:
match_phrase 称为短语搜索,要求所有的分词必须同时出现在文档中,同时位置必须紧邻一致。

可以看到,此时只会匹配出一条满足条件的记录。
三、总结
本文主要介绍了es中常用的两种查询方式:term和match。
term:代表完全匹配,也就是精确查询,搜索前不会再对搜索词进行分词解析,直接对搜索词进行查找;
match:代表模糊匹配,搜索前会对搜索词进行分词解析,然后按分词匹配查找;
term主要用于精确搜索,match则主要用于模糊搜索;
term精确搜索相较match模糊查询而言,效率较高;
同时总结了两种数据类型:text和keyword。
text:查询时会进行分词解析;
keyword:keyword类型的词不会被分词器进行解析,直接作为整体进行查询;
由于笔者水平有限,如文中有不对之处,还望指正,相互学习,一起进步!
第二个总结:
1、term查询的时候查询关键字是精确匹配,查询的关键字不会做分词处理,所以term一般用户查询age number等非text类型的精确匹配,text类型的查询一般使用match

2、match_phrase和keyword精确查询的区别
GET member/info/_search { "query": { "match_phrase": { "name": "张无" } } }
是一个短语查询,查出的一条结果数据为
#! Deprecation: [types removal] Specifying types in search requests is deprecated. { "took" : 2, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 1, "relation" : "eq" }, "max_score" : 1.2990016, "hits" : [ { "_index" : "member", "_type" : "info", "_id" : "2", "_score" : 1.2990016, "_source" : { "name" : "张无忌", "age" : 50 } } ] } }
GET member/_analyze { "text" : "张无忌" }
分词的结果为
{ "tokens" : [ { "token" : "张", "start_offset" : 0, "end_offset" : 1, "type" : "<IDEOGRAPHIC>", "position" : 0 }, { "token" : "无", "start_offset" : 1, "end_offset" : 2, "type" : "<IDEOGRAPHIC>", "position" : 1 }, { "token" : "忌", "start_offset" : 2, "end_offset" : 3, "type" : "<IDEOGRAPHIC>", "position" : 2 } ] }
match_phrase 称为短语搜索,要求所有的分词必须同时出现在文档中,同时位置必须紧邻一致。上面分词之后“张”和“三”都出现在相邻的位置上面
name.keyword属性2
GET member/info/_search { "query": { "match": { "name.keyword": "张无" } } }
查询的结果为null
下面
GET member/info/_search { "query": { "match": { "name.keyword": "张无忌" } } }
#! Deprecation: [types removal] Specifying types in search requests is deprecated. { "took" : 6, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 1, "relation" : "eq" }, "max_score" : 0.9808291, "hits" : [ { "_index" : "member", "_type" : "info", "_id" : "2", "_score" : 0.9808291, "_source" : { "name" : "张无忌", "age" : 50 } } ] } }
name": "张无忌",去查询的时候,name会分词,结果中只要包涵了"张",“无”,“忌”中的一个词都会结构都会被查询出来
name.keyword": "张无忌",去查询的时候,name会分词,结果中只要包涵了"张",“无”,“忌”中的一个词都会结构都会被查询出来,数据查询出来之后,因为加了keyword关键字,会对查询出来的结果进行过来,数据结果中必须name的值必须和keyword中的
张无忌三个字值一样的结果才显示出来,name的值如果为张无,但是keyword为张无忌,是不会显示出来的。这就是为啥"name.keyword": "张无"没有结果的原因。
keyword属性用于精确匹配,我们可以查看索引的mapping结构来查看
GET member/_mapping
{ "member" : { "mappings" : { "properties" : { "age" : { "type" : "long" }, "name" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } } } } } }
上面就name属性有一个子属性keyword,keyword就是为了精确查询,精确匹配
上面表示有个字段name,name字段为text类型,name字段下面还有其他属性,其中一个子属性的名称为keyword,keyword的type类型部署text类型,而是keyword类型。
keyword类型存储的就是该字段本身的值,不进行分词存储
上面就是表示,查询的时候name.keyword的对于的keyword属性的值必须是张无忌,用于精确匹配
GET member/info/_search
{
"query": {
"match": {
"name.keyword": "张无忌"
}
}
}
这里再创建索引的时候,我们可以指定字段的类型为keyword,这样在存储的时候就不会进行分词存储,在查询的时候必须进行精确匹配,比如邮箱


posted on 2022-07-14 13:48 luzhouxiaoshuai 阅读(340) 评论(0) 编辑 收藏 举报


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
2019-07-14 尚硅谷 dubbo学习视频