

k8s中对应的stateful有状态服务的讲解

Statefulset名称为web 三个Pod副本: web-0,web-1,web-2,volumeClaimTemplates名称为:www,那么自动创建出来的PVC名称为www-web[0-2],为每个Pod创建一个PVC。
Kubernetes StatefulSet 允许我们为 Pod 分配一个稳定的标识和持久化存储,Elasticsearch 需要稳定的存储来保证 Pod 在重新调度或者重启后的数据依然不变,所以需要使用 StatefulSet 来管理 Pod。

一、StatefulSet的设计原理
首先我们先来了解下Kubernetes的一个概念:有状态服务与无状态服务。
无状态服务(Stateless Service):该服务运行的实例不会在本地存储需要持久化的数据,并且多个实例对于同一个请求响应的结果是完全一致的。这种方式适用于服务间相互没有依赖关系,如Web应用,在Deployment控制器停止掉其中的一个Pod不会对其他Pod造成影响。
有状态服务(Stateful Service):服务运行的实例需要在本地存储持久化数据,比如数据库或者多个实例之间有依赖拓扑关系,比如:主从关系、主备关系。如果停止掉依赖中的一个Pod,就会导致数据丢失或者集群崩溃。这种实例之间有不对等关系,以及实例对外部数据有依赖关系的应用,就被称为“有状态应用”(Stateful Application)。
其中无状态服务在我们前面文章中使用的Deployment编排对象已经可以满足,因为无状态的应用不需要很多要求,只要保持服务正常运行就可以,Deployment删除掉任意中的Pod也不会影响服务的正常,但面对相对复杂的应用,比如有依赖关系或者需要存储数据,Deployment就无法满足条件了,Kubernetes项目也提供了另一个编排对象StatefulSet。
StatefulSet将有状态应用抽象为两种情况:
拓扑状态。这种情况意味着,应用的多个实例之间不是完全对等的关系。这些应用实例,必须按照某些顺序启动,比如应用的主节点 A 要先于从节点 B 启动。而如果你把 A 和 B 两个 Pod 删除掉,它们再次被创建出来时也必须严格按照这个顺序才行。并且,新创建出来的 Pod,必须和原来 Pod 的网络标识一样,这样原先的访问者才能使用同样的方法,访问到这个新 Pod。
存储状态。这种情况意味着,应用的多个实例分别绑定了不同的存储数据。对于这些应用实例来说,Pod A 第一次读取到的数据,和隔了十分钟之后再次读取到的数据,应该是同一份,哪怕在此期间 Pod A 被重新创建过。这种情况最典型的例子,就是一个数据库应用的多个存储实例。
StatefulSet 的核心功能,就是通过某种方式记录这些状态,然后在 Pod 被重新创建时,能够为新 Pod 恢复这些状态。它包含Deployment控制器ReplicaSet的所有功能,增加可以处理Pod的启动顺序,为保留每个Pod的状态设置唯一标识,同时具有以下功能:
稳定的、唯一的网络标识符
稳定的、持久化的存储
有序的、优雅的部署和缩放
二、有状态服务的拓扑状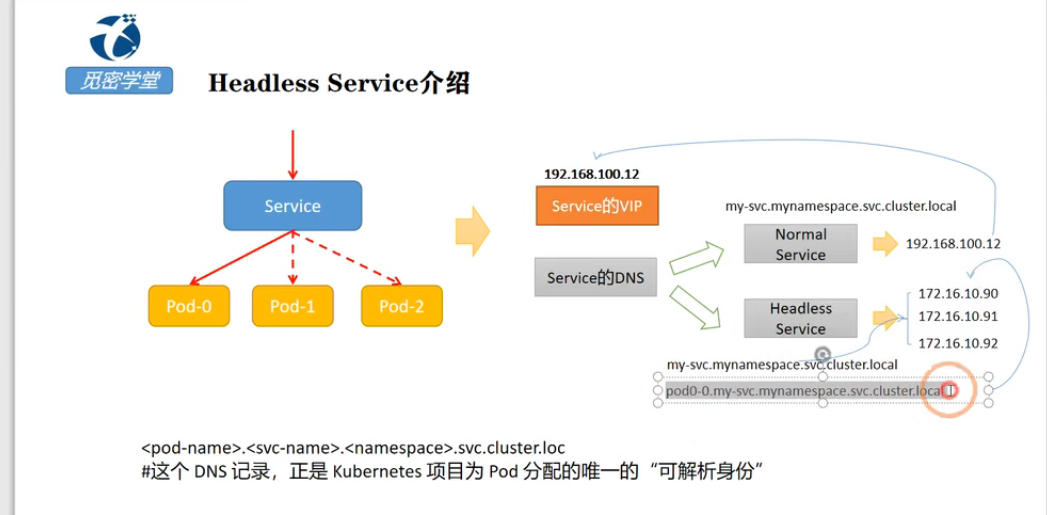

https://www.cnblogs.com/erlou96/p/13803188.html 查看博客https://www.cnblogs.com/erlou96/p/13803188.html
一.准备基础环境
1.jdk
2.zookeeper 自行下载
3.将这些包都放在/opt/docker 目录下,这个目录后续作为Dockerfile的启动目录
二.安装docker
1安装docker
2 更改DOCKER 存储目录
因为后续还要制作别的镜像,根目录容量不够,需要修改docker的挂载路径
解决方法:参考https://blog.csdn.net/justlpf/article/details/103716138
根据docker服务的安装配置文件进行修改
在ExectStart=xxx 中添加属性

重新更新一下docker服务
三.下载基础镜像
1.下载centos7.2的基础镜像
2. 查看docker 镜像
四.制作zookeeper环境包
1.解压文件
2.创建一个启动zookeeper的脚本
这里一定要加上前台启动命令,否则docker会异常退出Docker容器启动web服务时,都指定了前台运行的参数,例如apache:
-
ENTRYPOINT [ "/usr/sbin/apache2" ]
-
CMD ["-D", "FOREGROUND"]
又例如nginx:
-
ENTRYPOINT [ "/usr/sbin/nginx", "-g", "daemon off;" ]
因为Docker容器仅在它的1号进程(PID为1)运行时,会保持运行。如果1号进程退出了,Docker容器也就退出了。
一定要注意daemon off ;分号不能去掉!否则失败!!
3.创建zookeeper data数据目录
4.创建zoo.cfg文件,进入zookeeper 目录
5.修改配置文件zoo.cfg的内容
6.将修改后的zookeeper文件重新打成tar包
将这个包放到/opt/docker目录下。 到此:zookeeper的基础包就制作好了
五.制作jdk环境包
1.安装jdk
默认的jdk安装路径为/usr/java/jdk1.8.0_211
2.将/usr/java/jdk1.8.0_211 文件复制到 /opt/docker 下并改名为jdk
3.将jdk打成tar包
将这个包放到/opt/docker目录下。到此:jdk的环境包准备好了
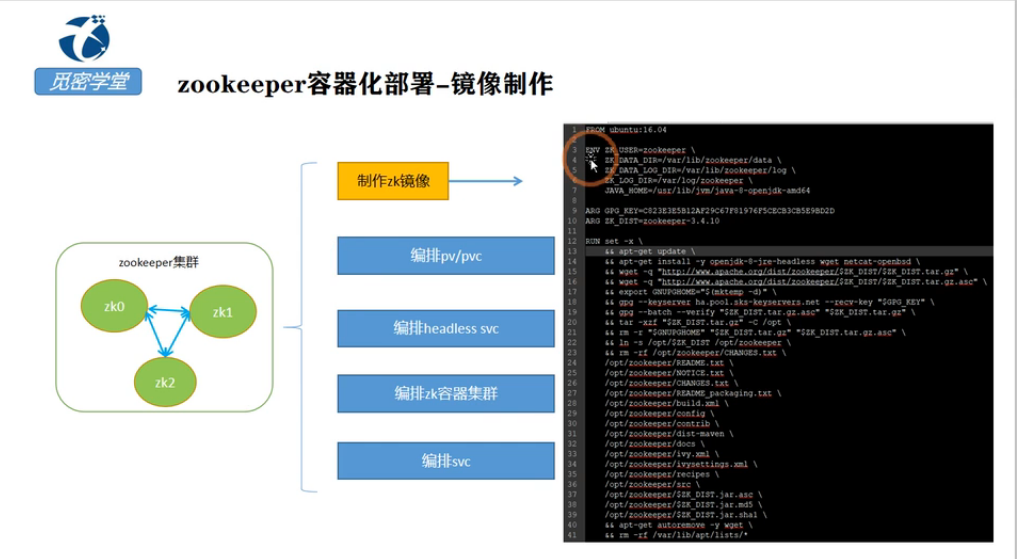
六.编写Dockerfile文件

1.创建dockerfile文件
# FROM命令 定义基础包 FROM docker.io/centos:centos7.2.1511 # ADD命令 将打包文件上传到镜像的根目录/ ,会自动解压 ADD zookeeper.tar /opt ADD jdk.tar /opt # WORKDIR命令 定义工作目录 WORKDIR /opt # ENV命令 设置环境 ENV JAVA_HOME /opt/jdk1.8.0_211 ENV CLASSPATH .:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar ENV PATH $JAVA_HOME/bin:$PATH # RUN命令 执行制作镜像过程,一个RUN对应一层 #RUN yum clean all \ RUN rm -vf /etc/localtime \ #&& cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime\ #&& rm -rfv /usr/share/backgrounds/* \ #&& rm -rfv /usr/share/doc/* \ #&& rm -rfv /usr/share/man/* \ #&& cd /usr/share/zoneinfo/ && ls |grep -v "Asia"|xargs rm -rfv \ #&& rm -rfv /var/cache/yum/* \ #&& rpm --rebuilddb \ && chmod 755 /opt/zookeeper/start.sh ENTRYPOINT /opt/zookeeper/start.sh
七.构建镜像
1.在/opt/docker目录下构建镜像
2.查看镜像

3.启动容器:映射端口,并且将Docker挂载本地目录及实现文件共享,这样重启容器,zk的数据不会丢失
八.验证zk是否启动成功
启动成功,问题解决
参加博客2:https://blog.csdn.net/cool_summer_moon/article/details/106490067
参加博客3:https://blog.csdn.net/Happy_Sunshine_Boy/article/details/107249542
1.Dockerfile
1.1 环境准备
apache-zookeeper-3.6.1-bin.tar.gz
jdk-8u121-linux-x64.tar.gz
zookeeper.DockerFile
# 基础镜像 生成的镜像作为基础镜像 FROM centos # 指定维护者的信息 MAINTAINER tanggaomeng<tanggaomeng@inspur.com> # 复制并解压 ADD jdk-8u121-linux-x64.tar.gz /usr/local/ ADD apache-zookeeper-3.6.1-bin.tar.gz /usr/local # 配置环境 RUN yum -y update RUN yum -y install vim net-tools telnet tree git wget curl ENV work_path /usr/local WORKDIR $work_path # java ENV JAVA_HOME /usr/local/jdk1.8.0_121 ENV JRE_HOME /usr/local/jdk1.8.0_121/jre ENV CLASSPATH .:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib # zookeeper ENV ZOOKEEPER_HOME /usr/local/apache-zookeeper-3.6.1-bin # 环境变量设置 ENV PATH $PATH:$JAVA_HOME/bin:$JRE_HOME/bin:$ZOOKEEPER_HOME/bin RUN cp $ZOOKEEPER_HOME/conf/zoo_sample.cfg $ZOOKEEPER_HOME/conf/zoo.cfg EXPOSE 2181 CMD $ZOOKEEPER_HOME/bin/zkServer.sh start-foreground
镜像说明: FROM centos是一个基础镜像,后面的操作等于我们登录到了centos操作系统上面执行后续的操作,
ADD镜像拷贝,拷贝到centos的根目录上面根目录为/,add默认会有个自动解压的操作,copy不会默认自动解压。COPY命令用于将于Dockerfile所在目录中的文件在镜像构建阶段从宿主机拷贝到镜像中,对于文件而言可以直接将文件复制到镜像中,add除了copy的作用还有自动对tar进行解压
默认的workdir是centos的根目录,上面的dockfile中指定work_path为 /usr/local,命令
后续所有命令的执行都是在wordir目录pwd该目录下执行的,WORKDIR指令设置Dockerfile中的任何RUN,CMD,ENTRPOINT,COPY和ADD指令的工作目录。
单个Dockerfile可以使用多次WORKFDIR。如果提供一个相对路径,当前的工作目录将于上个WORKDIR指令相关。如:
WORKDIR /a
WORKDIR b
WORKDIR c
RUN pwd
pwd命令的输出/a/b/c
执行命令执行命令docker exec的时候,就会去读取容器的那个workdir,进入到该容器的worddir目录,这里一定要注意
ENV ZOOKEEPER_HOME 在centos中定义一个环境变量,等容器启动之后,你可以使用echo输出改环境变量的值
EXPOSE 2181定义容器启动之后容器的端口是2181
CMD $ZOOKEEPER_HOME/bin/zkServer.sh start-foreground cmd命令表示容器启动之后执行的命令,将zookeeper启动起来
RUN表示在centos镜像中执行的一系列命令操作,如果要执行多个命令需要使用&&,如下面所示

表示连续执行一系列上面的命令操作
接下来讲讲docker中cmd和EntryPoint的区别
参加博客:https://blog.csdn.net/f1ngf1ngy1ng/article/details/105546160
https://blog.csdn.net/thedarkclouds/article/details/81982338
相当的经典




我们知道,通过docker run 创建并启动一个容器时,命令的最后可以指定容器启动后在容器内立即要执行的指令,如:
docker run -i -t ubunu /bin/bash //表示容器启动时立即在容器内打开一个shell终端
docker run ubuntu /bin/ps //表示容器启动后立即运行 /bin/ps命令,显示容器的当前进程。
除了这种方式外,我们可以在dockerfile文件中通过CMD指令指定容器启动时要执行的命令。如:
#test
FROM ubuntu
MAINTAINER xxx
RUN echo hello1 > test1.txt
RUN echo hello2 > /test2.txt
EXPOSE 80
EXPOSE 81
CMD ["/bin/bash"]
上面dockerfile文件中最后一行CMD指令的参数是指定容器启动时要执行的命令,这里是bin/bash命令。
1、用docker run命令创建并启动容器(myimage 是用前面dockerfile创建的镜像的名称):
docker run -i -t myimage
上面命令是创建并启动容器,打开一个交互式shell。 而以前的写法是
docker run -i -t myimage /bin/bash
这样就省去了在docker run中写命令了。
2、即使dockerfile中有CMD指令,我们仍然可以在docker run命令中带上容器启动时执行的命令,这会覆盖dockerfile中的CMD指令指定的命令。如:
docker run -i -t myimage /bin/ps
上面命令,因为/bin/ps覆盖了CMD指令,启动容器时会打印容器内的当前进程,但容器会立即停止,因为/bin/bash被覆盖了,无法打开交互式shell界面。
3、需要注意的是,dockerfile中可以有多条cmd命令,但只是最后一条有效。
4、CMD命令的参数格式,一般写成 字符串数组的方式,如上面的例子。如:
CMD ["echo","hello world"]
虽然也可写成CMD echo hello word 方式,但这样docker会在指定的命令前加 /bin/sh -c 执行,有时有可能会出问题。 所以推荐采用数据结构的方式来存放命令。
需要注意的是,Entrypoint的命令一定会被执行,不能被外面的命令覆盖,但是可以有多条cmd命令,但只是最后一条有效,并且cmd命令能够被dokcer run 后面自带的命令
覆盖dockerfile中定义的cmd命令。
1.2 构建镜像
docker build -f zookeeper.DockerFile -t zookeeper:3.6.1 .
1.3 创建并启动容器
docker run -d --name zookeeper -p 2181:2181 zookeeper:3.6.1
1.4 连接ZooKeeper容器
docker exec -it zookeeper /bin/bash
1.5 进入ZooKeeper的bin目录
cd apache-zookeeper-3.6.1/bin
1.6 客户端连接ZooKeeper服务器端
./zkCli.sh -server 127.0.0.1:2181
1.7 创建节点
[zk: 127.0.0.1:2181(CONNECTED) 1] create -e /test-node 123456
1.8 列出所有根节点
[zk: 127.0.0.1:2181(CONNECTED) 2] ls /
[test-node, zookeeper]
1.9 获取指定节点的值
[zk: 127.0.0.1:2181(CONNECTED) 3] get /test-node
1.10 断开客户端连接
[zk: 127.0.0.1:2181(CONNECTED) 4] quit
# FROM命令 定义基础包 FROM docker.io/centos:centos7.2.1511 # ADD命令 将打包文件上传到镜像的根目录/ ,会自动解压 ADD zookeeper.tar /opt
ADD jdk.tar /opt
# WORKDIR命令 定义工作目录
WORKDIR /opt
# ENV命令 设置环境
ENV JAVA_HOME /opt/jdk1.8.0_211
ENV CLASSPATH .:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
ENV PATH $JAVA_HOME/bin:$PATH
# RUN命令 执行制作镜像过程,一个RUN对应一层
#RUN yum clean all \
RUN rm -vf /etc/localtime \
#&& cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime\
#&& rm -rfv /usr/share/backgrounds/* \
#&& rm -rfv /usr/share/doc/* \
#&& rm -rfv /usr/share/man/* \
#&& cd /usr/share/zoneinfo/ && ls |grep -v "Asia"|xargs rm -rfv \
#&& rm -rfv /var/cache/yum/* \
#&& rpm --rebuilddb \
&& chmod 755 /opt/zookeeper/start.sh
ENTRYPOINT /opt/zookeeper/start.sh

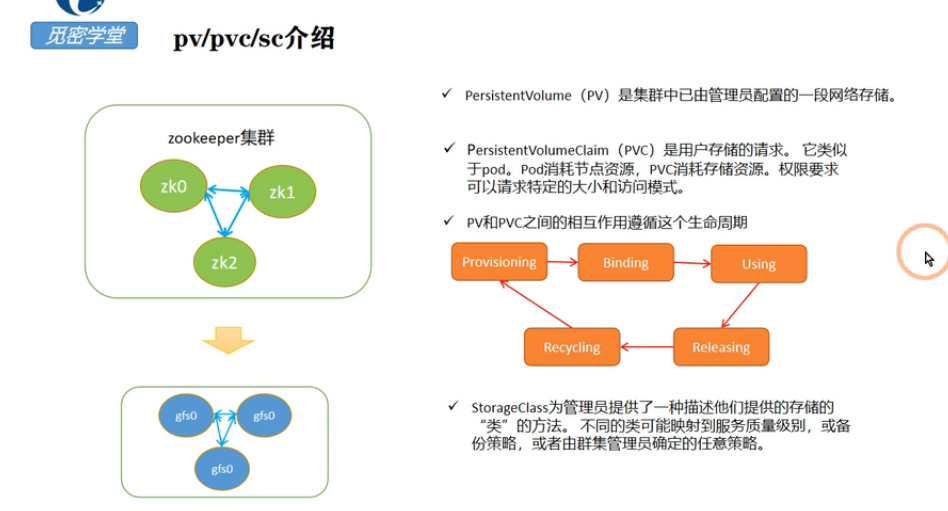
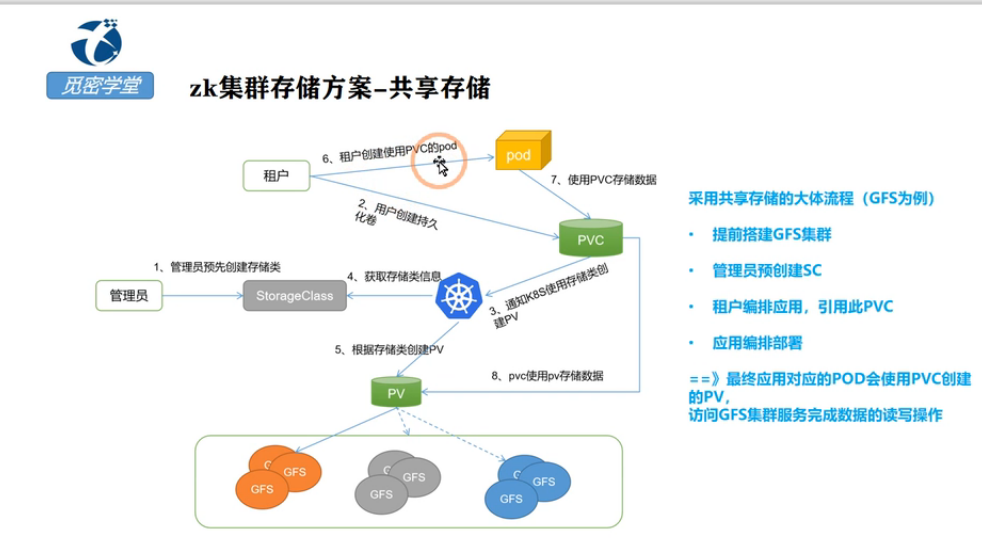
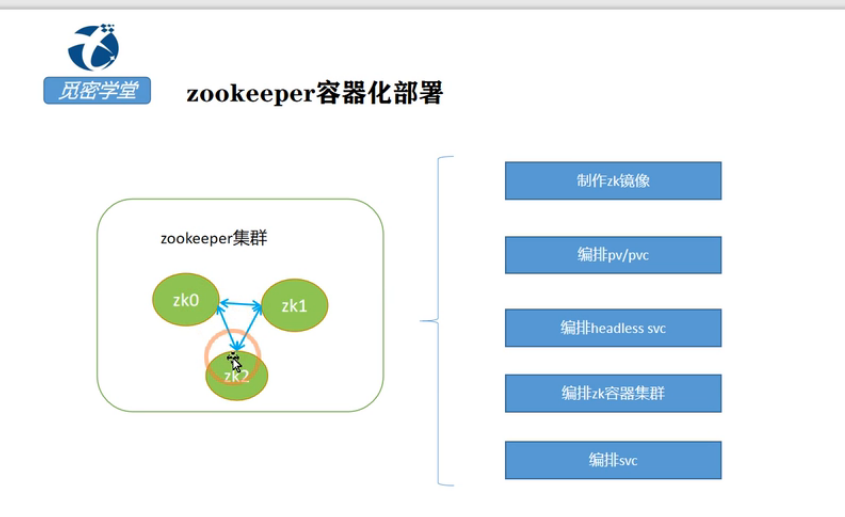
zk的存储使用外部的gfs集群存储,在第三节课中首先使用本地存储来创建pv,这里上面的zk镜像启动了三个pod,每一个pod都要存储对应的数据,这里就应该使用三个节点
在每个节点上面都创建一个pv的目录来存储pv,如k8s有三个节点,启动的三个zk的pod分别部署在三个节点上,pod分别使用三个节点上面的本地存储,需要给三个节点打上标签,分表是zk0、zk1,zk2

上面这个pv很经典呀,重点分析下
第一个创建一个pv-zk-test005-zookpeer-0的pv,给pv打上label标签也是pv-zk-test005-zookpeer-0
整个pv-zk-test005-zookpeer-0的磁盘大小是500M,这里模式是 volumeMode字段的默认值是Filesystem,但也支持配置为Block,这样就会把node节点的local volume作为容器的一个裸块设备挂载使用
这里accessMode设置为
RWO:ReadWriteOnce,仅允许单个节点挂载进行读写;
ROX:ReadOnlyMany,允许多个节点挂载且只读;
RWX:ReadWriteMany,允许多个节点挂载进行读写;
表示每个节点上面挂载的目录只需要当前的节点操作,意思就是zk0只能访问zk0上面的操作,pod-0部署在zk0这个节点上面,那么pod-0只能访问zk0上面挂载的目录,不能访问zk1节点上面的目录数据,这就是所谓的有状态操作
1、创建的pod的都是有名称的,创建的三个pod的名称列如分别都是pod-1,pod-2,pod-3,如果pod-1异常退出之后,statefu会创建一个新的pod,pod的名称和之前退出的pod名称一致都是叫pod-1,pod-1访问的也是之前zk1节点上面原来就存储好的数据保证数据的唯一性
hostpath指定当前挂载的目录是位于当前主机的那个目录
Retain表示pod异常退出之后对应的数据不会删除,还会继续保留,,如果pod-1异常退出之后,statefu会创建一个新的pod,pod的名称和之前退出的pod名称一致都是叫pod-1,pod-1访问的也是之前zk1节点上面原来就存储好的数据保证数据的唯一性,就是有状态
这里要指定pv的亲和性,pv保存到那个节点上,pv-zk-test005-zookpeer-0这个pv只能存储在打了zk0标签的k8s集群的node节点上面
接下来我们来看pvc的定义
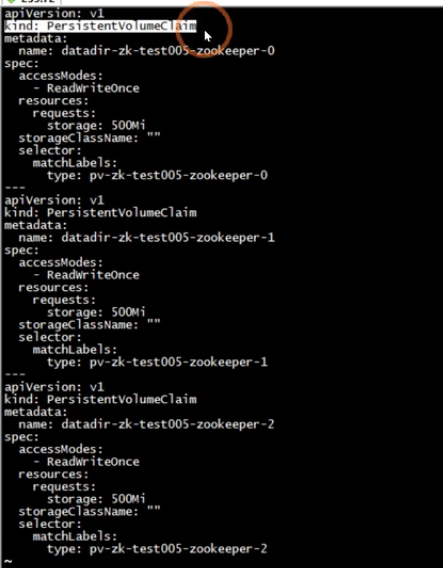
pvc就是通过上面的selector要选择对应的pv
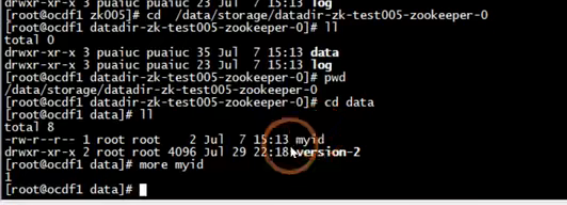
在上面的目录下一般存储的zk的data数据和log数据,data中存储的是zk的myid

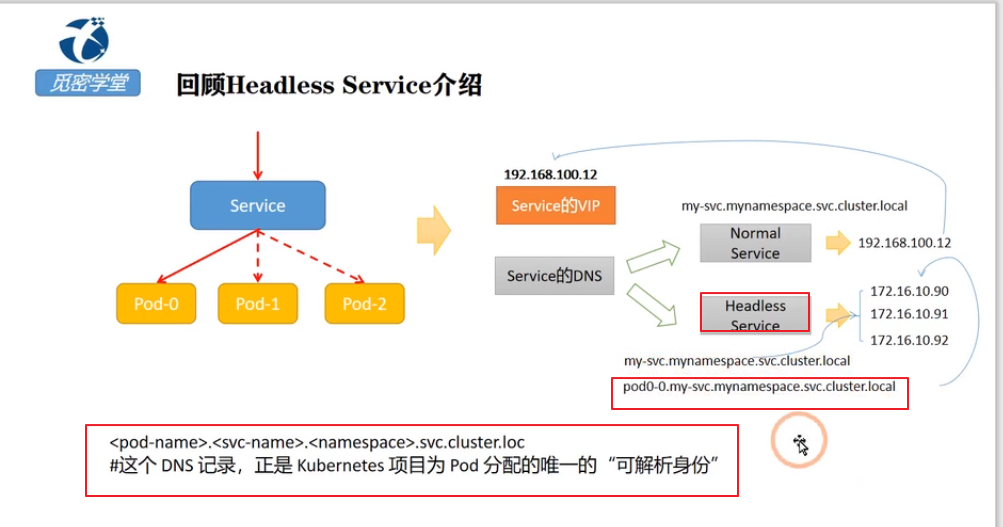
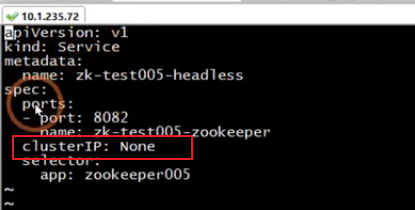
headless service 需要将 spec.clusterIP 设置成 None。
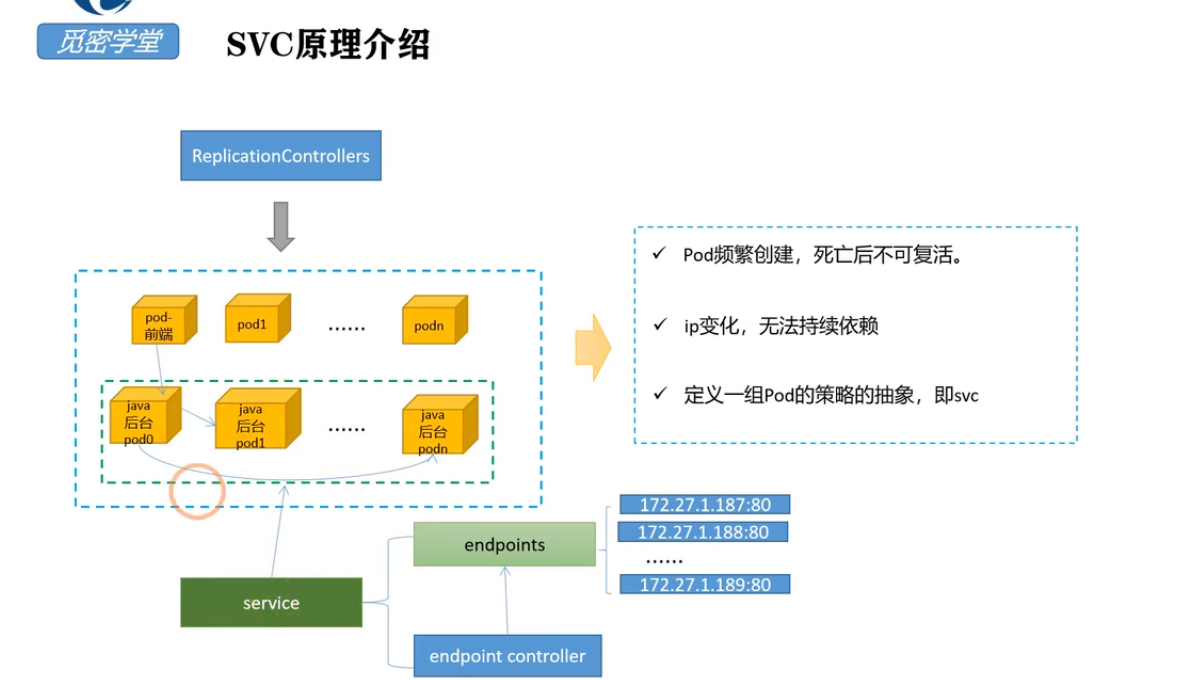
因为没有ClusterIP,kube-proxy 并不处理此类服务,因为没有load balancing或 proxy 代理设置,在访问服务的时候回返回后端的全部的Pods IP地址,主要用于开发者自己根据pods进行负载均衡器的开发(设置了selector)。
我们来看一个案例
首先创建一个nginx的编排文件
$cat deployment.yaml apiVersion: extensions/v1beta1 kind: Deployment metadata: name: nginx-deployment spec: replicas: 2 # tells deployment to run 2 pods matching the template template: # create pods using pod definition in this template metadata: # unlike pod-nginx.yaml, the name is not included in the meta data as a unique name is # generated from the deployment name labels: app: nginx_test spec: containers: - name: nginx image: nginx:1.7.9 ports: - containerPort: 80
接下来窗口headless service文件
$ cat headless_service.yaml kind: Service apiVersion: v1 metadata: name: nginx-service spec: selector: app: nginx_test ports: - protocol: TCP port: 80 targetPort: 80 clusterIP: None
通过dns访问,会返回后端pods的列表
登录到Cluster的内部pod,解析service的域名返回的就是后端pod的列表
nslookup nginx-service nslookup: can't resolve '(null)': Name does not resolve Name: nginx-service Address 1: 10.10.23.36 Address 2: 10.10.23.39
通过headless service 可以轻松找到statefulSet 的所有节点。
特别是在部署集群的时候,很多服务需要配置节点信息来创建集群。
statefulSet.spec.serviceName
当serviceName 配置成与headless service的Name 相同的时候
可以通过 {PodName}.{headless service}.{namespace}.svc.cluster.local 解析出pod节点IP。
PodName 由 {statefulSet name}-{编号} 组成。
如上,web为我们创建的StatefulSets,对应的pod的域名为web-0,web-1,他们之间可以互相访问,这样对于一些集群类型的应用就可以解决互相之间身份识别的问题了。
https://www.jianshu.com/p/a6d8b28c88a2
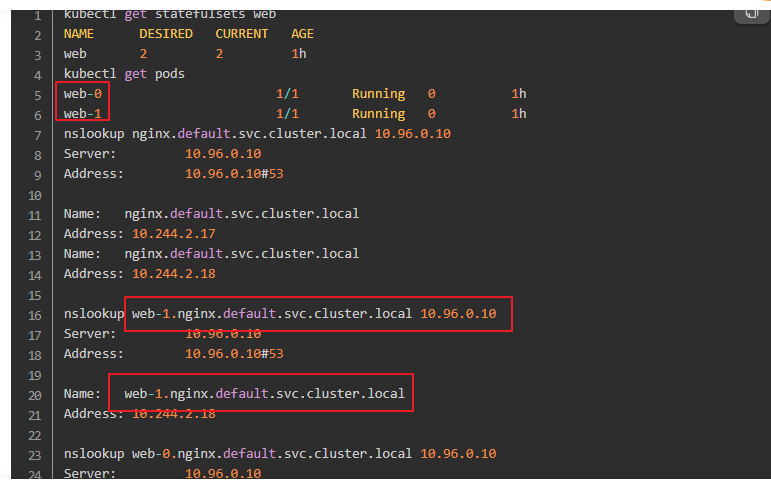
statefulless启动的pod名称是web,启动两个pod,pod的编号是有顺序的分别是web-0,web1
上web-1是pod的名称,nginx是headless对应的service的名称,default是namespace,svc.cluster.local是默认的值,使用
dns解析web-1.nginx.default.svc.cluster.local得到的就是web-1这个pod的IP
curl web-1.nginx.default.svc.cluster.local最终访问的就是web-1这个pod
如上,web为我们创建的StatefulSets,对应的pod的域名为web-0,web-1,他们之间可以互相访问,这样对于一些集群类型的应用就可以解决互相之间身份识别的问题了。
完整示例:
apiVersion: v1 kind: Service metadata: name: nginx labels: app: nginx spec: ports: - port: 80 name: web clusterIP: None selector: app: nginx --- apiVersion: apps/v1beta1 kind: StatefulSet metadata: name: web spec: serviceName: "nginx" replicas: 1 template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:1.11 ports: - containerPort: 80 name: web volumeMounts: - name: www mountPath: /usr/share/nginx/html nodeSelector: node: kube-node3 volumes: - name: www hostPath: path: /mydir
使用StatefulSet部署有两个需要特别注意:
创建headless的使用要指定 clusterIP: None
在创建pod的时候一定要指定headless中service的名字,spec:
serviceName: "nginx"
svc.cluster.local
start-foreground
posted on 2021-08-15 22:44 luzhouxiaoshuai 阅读(1174) 评论(0) 编辑 收藏 举报

