

引入ELK前需要知道的“坑”(上)
徐磊,去哪儿网平台事业部大数据中心开发工程师,2015年加入Qunar,负责实时日志相关的开发与运维工作,有多年的电信,云计算从业经验。
去哪儿网内部从2014年开始接触并逐步推广应用 ELK 技术栈,解决诸如日志检索,数据分析,运营后台等诸多业务。如今公司内部运行着超过100个 Elasticsearch 集群,其中最大的集群超过400个节点,数据量超过1.3PB。每天通过 Logstash 处理的数据量几十亿,大部分开发人员都已经在 Kibana 上检索着应用日志,分析问题。经过几年的使用和运维 ELK,我们也积累了许多经验,也在社区中帮助许多人解答了他们的疑问,发现许多人在刚接触 ELK 的时候,总会有一些共性问题,借着这个公众号的渠道,总结分享出来,让更多的人在引入 ELK 时少走一些弯路。
Elasticsearch篇适用场景
这应该是所有刚接入 Elasticsearch 的人问的最多的问题,Elasticsearch 究竟能在我的系统里承担什么样的功能。 我们要明确一个前提,Elasticsearch 是以检索+数据统计起家的,现在逐步向商业 BI 的能力靠近,所以其发展路线图就决定了不适合某些场景,比如拿 Elasticsearch 当成一个 schemaless的数据库用,还要让其提供交易系统中的事物隔离,这显然就是错用的一个典型场景。Elasticsearch 的 NRT 特性就无法保证数据写入立即可见,同时多个 doc 级联操作没有任何源生的原子性保障,更不用说默认写入时最终一致性。 但是如果用 Elasticsearch 作为一个数据库 binlog 的备份,支撑后台运营系统的多维度查询,检索等需求,那这是 Elasticsearch 最擅长的地方。所以引入 Elasticsearch 前一定要先考虑其优势和劣势,再决定上线。
Index vs Type
许多初次接触 Elasticsearch 的人,都会听到或者搜到这样一个信息,Elasticsearch 中的一些概念,是可以和关系型数据库映射的,我大致整理了下,如下图:

这里要明确指出的一个问题是,Elasticsearch 中的 Index/Type 在实现上,并非是关系型数据中的 Database Schema/Table 强隔离。如果按照关系型数据库的设计来反推 Elasticsearch,可能会导致严重的后果,在此列举几个: (1) 数据无法写入(MapperParsingExcep-tion); (2) 检索结果乱序(_score); (3) 低版本Elasticsearch数据膨胀(LUCENE-6863)。 深究其根本原因,Type 并非 Lucene 源生提供的,而是 Elasticsearch 自己在逻辑层实现了 Type,对文档默认插入 _type 字段,这实际上对初学者产生了概念上的误导。
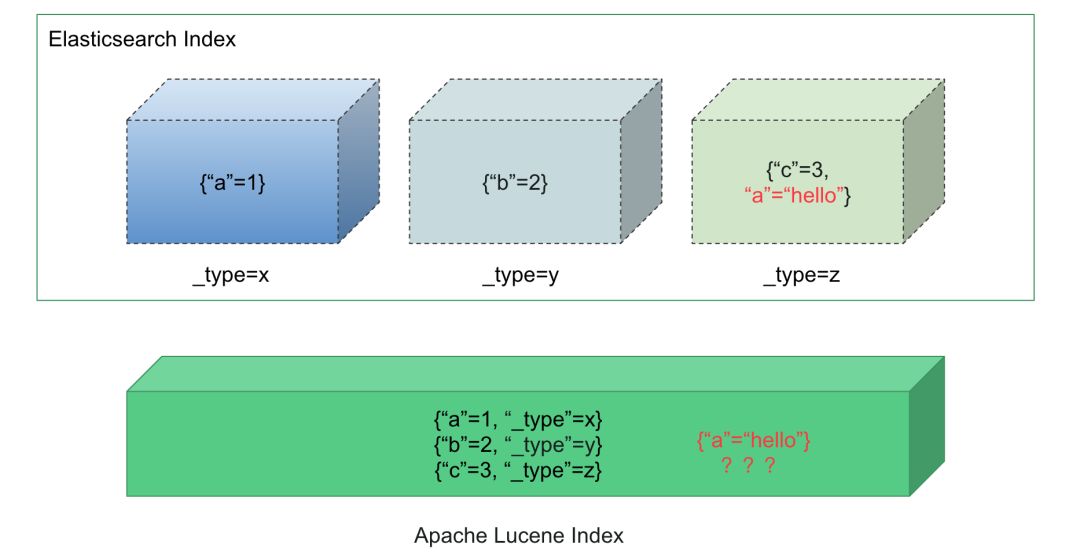
而一个好消息是,从 Elasticsearch 6.0/5.5 开始,将尽量屏蔽多 Type 带来的不稳定因素,7.0彻底移除 Type,所以如果你正在使用最新版本的 Elasticsearch,那么这个坑可以顺利绕过。 针对还在使用 1.x/2.x/5.x 的系统,由此衍生的一个常见问题就是——“我应该如何设计索引”,这个问题在各大论坛和讨论组经常被讨论,结合我们的实践,发现这个问题的答案很简单,遵守两条规则即可: (1)Index 用来对数据分类; (2)Type 用来对数据分区。 这么说可能比较抽象,我们以订单数据举个例子,比如整个 Qunar 的订单数据要存放到 Elasticsearch 中,那么比较推荐以下做法(单Type): (1)/ordercenter-2018.11.18/data/ (2)/ordercenter-2018.11.19/data/ (3)/ordercenter-2018.11.20/data/ 这样巨量的数据以天跨度分区,单个索引的数据量可以降低到一个可控的范围内,对后续的数据迁移和配置调整都留出了自由度,而且针对归档数据进行 close 或 snapshot 都可以独立进行,把影响隔离到最低。 如果每天订单数据量很小,那么也可以考虑合并成月/周索引,配合 Type 查询: (1)/ordercenter-2018.11/18/ (2)/ordercenter-2018.11/19/ (3)/order_center-2018.11/20/ 和第一种方法相比,索引的实践跨度增加了,许多变更都要等到下个月/周才能生效,对运维不利,而且归档周期拉长。
Document ID的选择
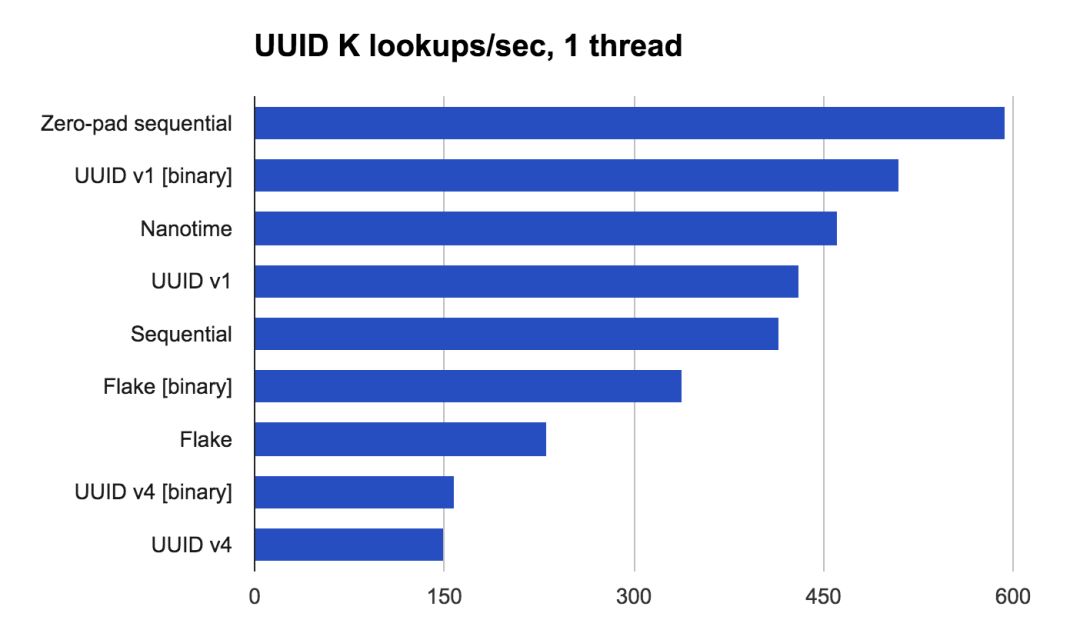
5.x 及以上版本且写入量大的集群,强烈推荐使用自生成文档 ID,这样可以避免 shard 内的唯一性检查,尤其是数据量越打越大的情况下,这对吞吐量来说是很大的提升。 如果出于业务的需要,需要手工设置文档 ID,那么更推荐同长度,带补齐的二进制数据,比如考虑左补零的自增数字,带来更高查询效率:
索引多 vs 数据多
还有一个问题就是一个 Elasticsearch 集群中,究竟可以支持多少个索引。这个结论我很难给一个量化的结果,毕竟不同的系统的索引情况都是不一样的,要具体情况具体分析,但是这里将给出一个分析的方法,尽早避免未来索引规模上涨带来的各种不稳定因素。 首先,索引数量变大,将直接影响 Master 节点的内存使用量,严重时会导致 Master 节点的持续 FGC,Cluster 级别的操作将大量超过,这个情况在生产系统是不可接受的。但是这并非一个充分必要条件,有一种情况也可以导致 Master 节点的 FGC,即单个 doc 的字段过多或嵌套层级太深。 其次,如果索引数量上涨带来了数据量的上涨,那么也将同时影响 Data 节点的内存,每个 Shard 都会加载倒排索引信息到内存,并且这部分内存是无法被 GC 掉的。一个长期有数据写入,但不做数据归档的集群,如果突然有一天发现 Data 节点开始持续的 GC 了,就要考虑下 Segment 是否占用了过多内存,然后做相应的处理。 讲到这里,其实分析方法已经很清晰了,看两个维度即可,索引数量和集群数据量,前者影响 Master 节点,后者影响 Data 节点。

有了这两个分析角度,我们就可以对集群的实际情况做出分析,并对容量做一些预估,提前考虑扩容。 (1)控制 doc 的字段数量,尽量降低嵌套层级,提高集群可承载的索引数量上限,同时利用 JVM heap 监控反推容量,设置报警线。 (2)以时间粒度切分索引,定期针对历史索引 optimize(force_merge),减少索引文件碎片,此操作也能降低 segment 内存占用,如果能对索引进行 close 并归档,那效果更好。 (3)在前两步的基础上,优化 doc,例如非查询字段设置成 index:no,非检索类数据 norms:false 等,降低存储占用,优化内存。 (4)参考历史监控数据,整理内存使用量与总数据量的比例关系,为扩容提供分析支持。
大磁盘 vs 大内存
有了上一节的信息,我们就可以继续推算 Elasticsearch 的机器硬件参数,如机器的内存与磁盘配比,以目前 Qunar 的情况为例,最大的集群存储1TB数据大约消耗0.9GB左右的内存(这个比例请依据自己的实际情况计算),在这个配比下,假设你的机器数据盘15TB,那么极端情况下,这些数据大约占用13.5GB的堆内存,那单个 JVM 实例配合 -Xmx30g -Xms30g 即可搞定,并留了一部分内存用作 Cache/IndexBuffer/Bulk 等操作使用。那么机器的内存推荐64GB以上即可。 如果改用大容量磁盘,单机超过50TB的存储,那么通过以上的条件的简单计算,就发现30g堆内存的 JVM 已经无法搞定了,此时要么考虑单机双实例,要么采取更大的堆内存支撑这些数据,机器的内存响应也要扩大到128GB以上。 当然,如果公司有矿,全部清一色的256/512GB的内存+大容量SSD卡,可以暂时忽略以上的推算过程。
单盘 vs 多盘
如果有人准备从1.x升级到2.x,或者新引入5.x的 Elasticsearch,那么都会面临一个问题,机器应该使用分盘存储的方式,还是做个 raid 合并成一块盘存储数据。这个问题的根源其实是2.x针对数据完成性的一个优化,同一个 shard 的数据保证放到一个盘。 如果你的集群采取了集中式的索引管理,比如每天/每周/每月集中创建索引,那么剩余空间最大的磁盘就会被强制分配一批 shard(此时新索引数据量为0),待数据灌入时,会发现这个磁盘IO暴涨,最后影响整个集群的吞吐。所以从2.x开始,集中管理式的集群+提前创建索引的运维策略下,就不推荐继续使用分盘存储的方式。
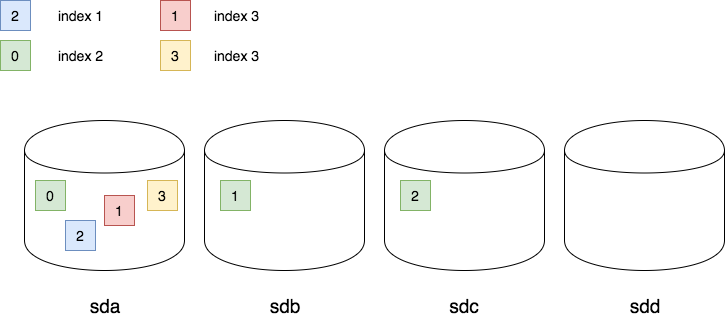
对于1.x升级到2.x的人来说,这就是个悲剧了,不但索引要重新构建,raid 都要重做了,这个就坑大了。 6.x是否重新针对此情况做了优化,我还没有看源码,并不确定,这个问题就留给各位读者自行验证了

posted on 2020-08-12 14:30 luzhouxiaoshuai 阅读(183) 评论(0) 编辑 收藏 举报


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
2018-08-12 java 加密与解密艺术二