
elk
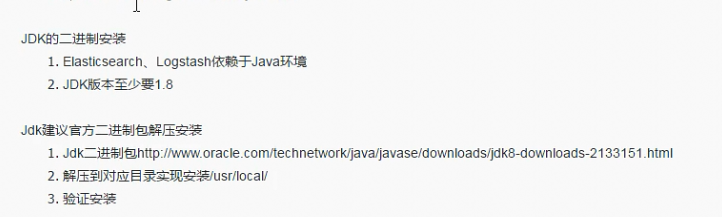

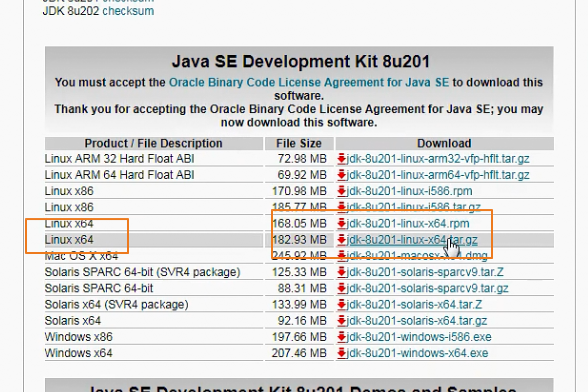
64位的jdk版本

我们在下面这台机器上192.168.43.113安装kibanna和eslasticsearch
Kibana安装脚本
cd /usr/local/src/
tar -zxf kibana-6.6.0-linux-x86_64.tar.gz
mv kibana-6.6.0-linux-x86_64 /usr/local/kibana-6.6.0
修改Kibana配置/usr/local/kibana-6.6.0/config/kibana.yml
server.port: 5601
server.host: "0.0.0.0"
#elasticsearch.url: "http://localhost:9200"
#elasticsearch.username: "user"
#elasticsearch.password: "pass"

这里需要注意的是我当前的操作系统是32位的
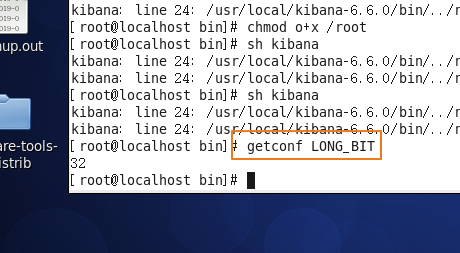
如果在32位linux系统中运行会报:/node/bin/node: cannot execute binary file问题
原因:kibana只提供了64位的kibana,由于kibana是基于node.js,而提供的二进制包中的node.js是64位的
解决方案:去IBM下载你的系统对应的node.js,笔者下载的是ibm-6.12.2.0-node-v6.12.2-linux-x86.bin,在linux系统中,进行如下操作: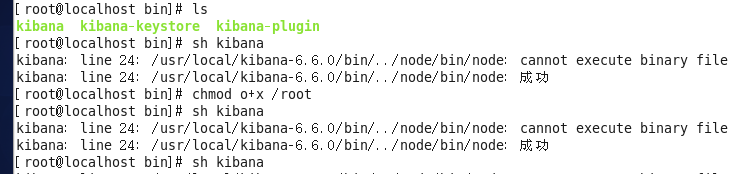

Kibana的启动和访问
- 前台启动Kibana:/usr/local/kibana-6.6.0/bin/kibana
- 后台启动Kibana:nohup /usr/local/kibana-6.6.0/bin/kibana >/tmp/kibana.log 2>/tmp/kibana.log &
- 访问Kibana,需要开放5601端口
Kibana的安全说明
- 默认无密码,也是谁都能够访问
- 如果使用云厂商,可以在安全组控制某个IP的访问
- 建议借用Nginx实现用户名密码登录
默认的Kibana
1. 任何人都能无密码访问Kibana
2. 借用Nginx实现登录认证
3. Nginx控制源IP访问、Nginx可以使用用户名密码的方式
Kibana借用Nginx来实现简单认证
4. Kibana监听在127.0.0.1
5. 部署Nginx,使用Nginx来转发
nginx的安装需要首先安装下面的依赖
Nginx编译安装
yum install -y lrzsz wget gcc gcc-c++ make pcre pcre-devel zlib zlib-devel
tar -zxvf nginx-1.14.2.tar.gz
cd nginx-1.14.2
./configure --prefix=/usr/local/nginx && make && make install

接下来修改环境变量
Nginx环境变量设置
vi /etc/profile文件末尾添加
export PATH=$PATH:/usr/local/nginx/sbin/
使用命令
source /etc/profile使得环境变量重新生效
这样nginx就安装成功了
Nginx两种限制
8. 限制源IP访问,比较安全,访问的IP得不变
9. 使用用户名密码的方式,通用

进入到/usr/local/nginx-1.14.2/conf目录执行vi nginx.conf操作
Nginx限制源IP访问
server { listen 80; location / { allow 127.0.0.1; deny all; proxy_pass http://127.0.0.1:5601; } }
只允许127.0.0.1这个IP地址访问,启动nginx使用nginx命令,重启nginx使用nginx -s reload命令
ES的安装脚本
cd /usr/local/src
tar -zxf elasticsearch-6.6.0.tar.gz
mv elasticsearch-6.6.0 /usr/local/
Elasticsearch配置/usr/local/elasticsearch-6.6.0/config/elasticsearch.yml
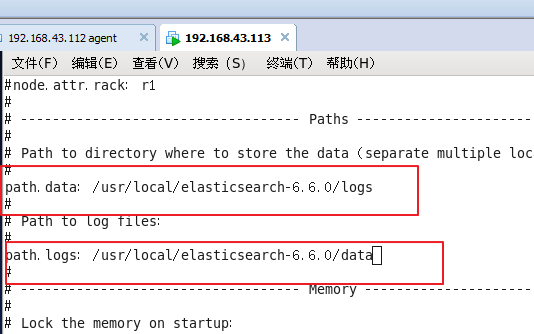
path.data: /usr/local/elasticsearch-6.6.0/data path.logs: /usr/local/elasticsearch-6.6.0/logs network.host: 127.0.0.1 http.port: 9200

es启动默认是1G的内存空间,我们可以在jvm.options修改es的内存
JVM的内存限制更改jvm.options
-Xms128M
-Xmx128M
es启动的时候不能是root用户,只能为普通用户
Elasticsearch的启动,得用普通用户启动
12. useradd -s /sbin/nologin elk
13. chown -R elk:elk /usr/local/elasticsearch-6.6.0/
14. su - elk -s /bin/bash
15. /usr/local/elasticsearch-6.6.0/bin/elasticsearch -d
验证启动是否成功
16. 观察日志
17. 观察Kibana网页
Elasticsearch启动注意
1. Elasticsearch如果启动在127.0.0.1的话,可以启动成功
2. Elasticsearch如果要跨机器通讯,需要监听在真实网卡上
3. 监听在真实网卡需要调整系统参数才能正常启动
Elasticsearch监听在非127.0.0.1
4. 监听在0.0.0.0或者内网地址
5. 以上两种监听都需要调整系统参数
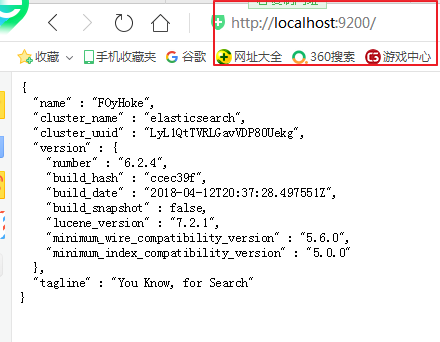
es默认只能使用http://localhost:9200/访问,如果要支持IP地址的形式访问,需要进行修改
现在我们把es启动监听的地址修改为0.0.0.0,那么要启动es成功我们需要修改内核的参数
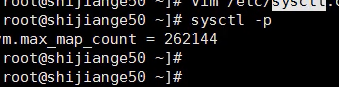
最大文件打开数调整/etc/security/limits.conf * - nofile 65536 最大打开进程数调整/etc/security/limits.d/20-nproc.conf * - nproc 10240 内核参数调整 vm.max_map_count = 262144
内核参数修改成功之后,必须使用sysctl -p命令使内核参数生效
这样启动es就可以成功,es的日志文件在
/usr/local/elasticsearch-6.6.0/logs/elasticsearch.log
Elasticsearch的概念
1. 索引 ->类似于Mysql中的数据库
2. 类型 ->类似于Mysql中的数据表
3. 文档 ->存储数据
Elasticsearch的数据操作
4. 手动curl操作Elasticsearch会比较难
5. 借用Kibana来操作Elasticsearch

索引操作
8. 创建索引: PUT /shijiange
9. 删除索引: DELETE /shijiange
10. 获取所有索引: GET /_cat/indices?v
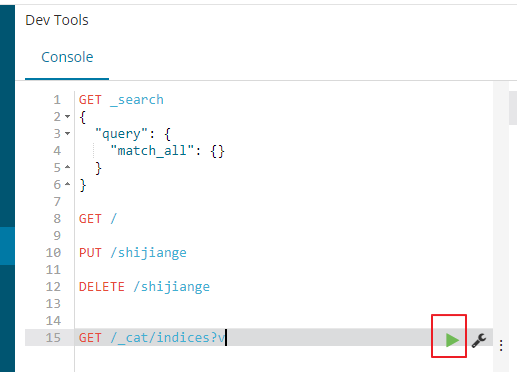
Elasticsearch增删改查
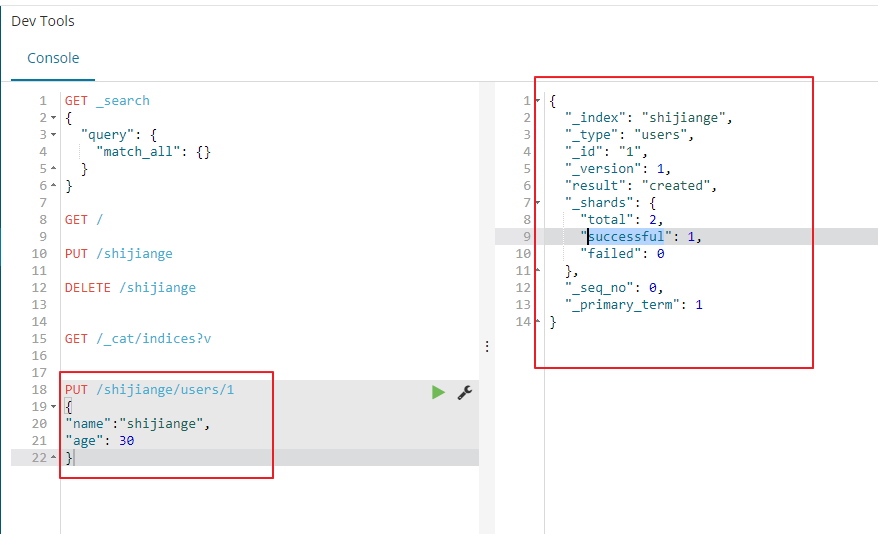
ES插入数据
PUT /shijiange/users/1
{
"name":"shijiange",
"age": 30
}
ES查询数据
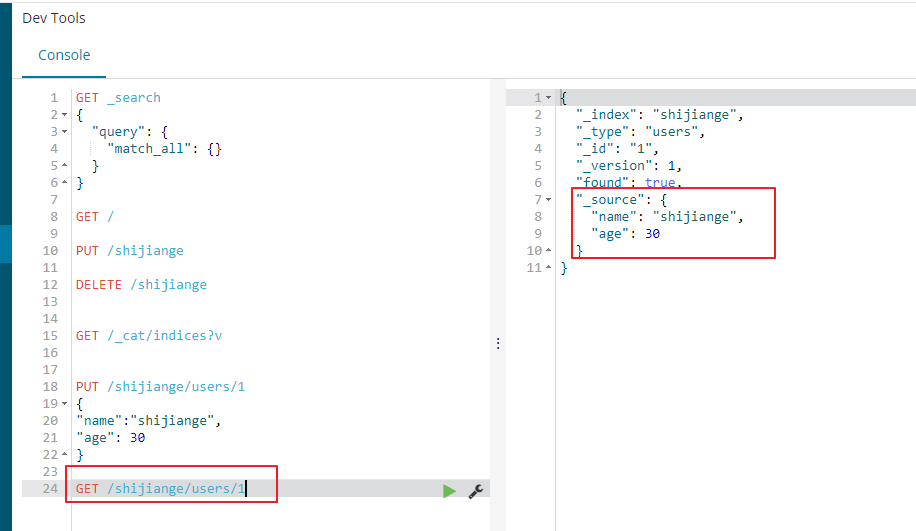
11. GET /shijiange/users/1
12. GET /shijiange/_search?q=*

13。依据字段的某个值进行查询
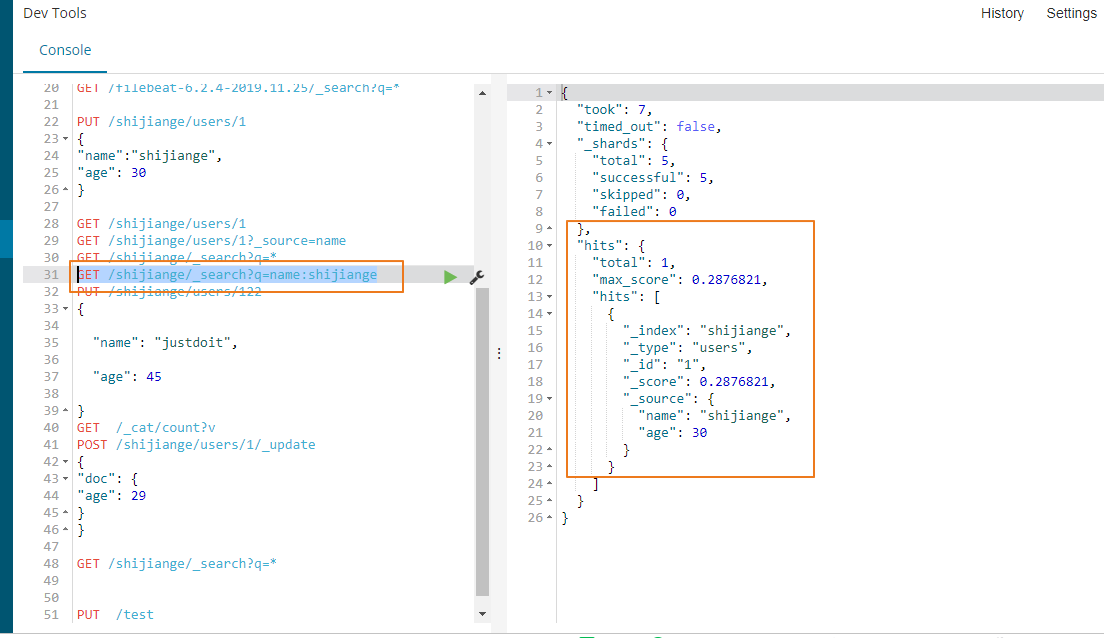
查询的时候指定_source只显示name字段

我们也可以使用mget进行批量操作
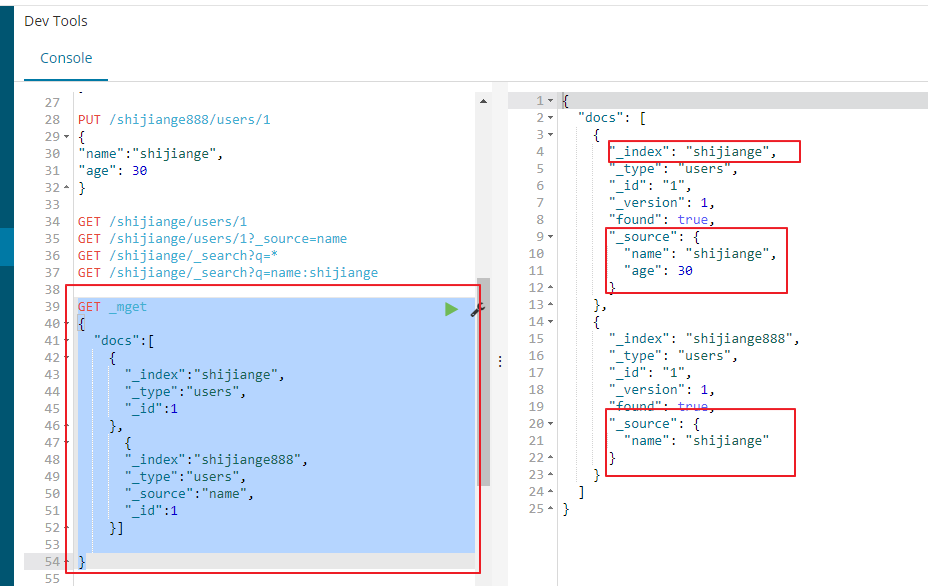
测试2:我们查询一个索引下的多条数据
先在索引里面添加几条数据
我们在elastic-head里面查看数据
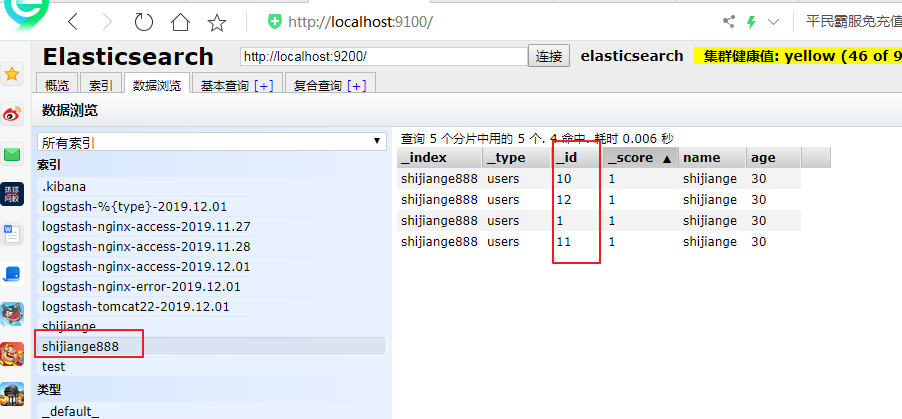
我们把上面的数据全部查询处理

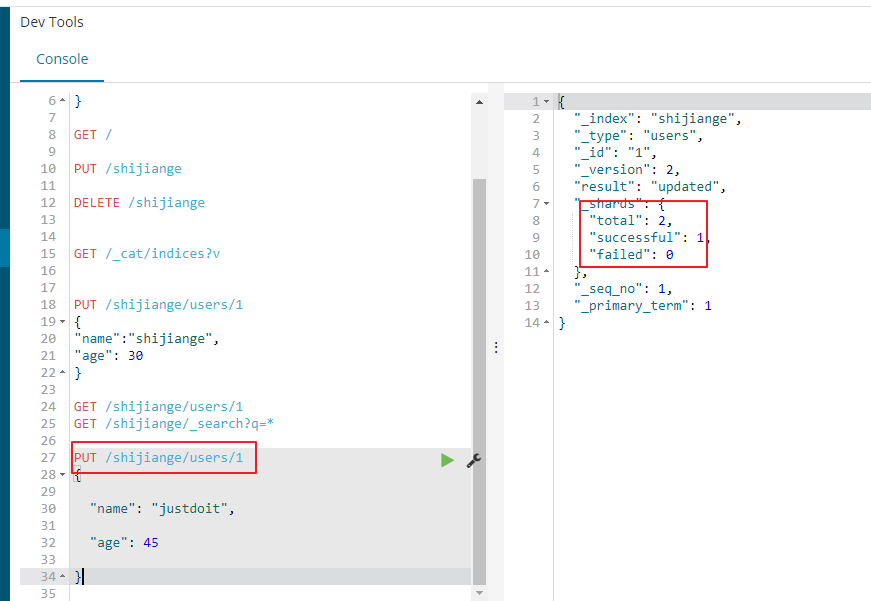
修改数据、覆盖
PUT /shijiange/users/1
{
"name": "justdoit",
"age": 45
}
ES删除数据
DELETE /shijiange/users/1
修改某个字段、不覆盖
POST /shijiange/users/1/_update
{
"doc": {
"age": 29
}
}
修改所有的数据
POST /shijiange/_update_by_query
{
"script": {
"source": "ctx._source['age']=30"
},
"query": {
"match_all": {}
}
}
增加一个字段
POST /shijiange/_update_by_query
{
"script":{
"source": "ctx._source['city']='hangzhou'"
},
"query":{
"match_all": {}
}
}
整个命令如下
GET _search { "query": { "match_all": {} } } GET / PUT /shijiange888 DELETE /logstash-nginx-access-2019.12.01 DELETE logstash-nginx-error-2019.12.01 DELETE /logstash-2019.11.25 DELETE /filebeat-6.2.4-2019.11.25 GET /_cat/indices?v GET /filebeat-6.2.4-2019.11.25/_search?q=* PUT /shijiange/users/1 { "name":"shijiange", "age": 30 } PUT /shijiange888/users/1 { "name":"shijiange", "age": 30 } GET /shijiange/users/1 GET /shijiange/users/1?_source=name GET /shijiange/_search?q=* GET /shijiange/_search?q=name:shijiange GET _mget { "docs":[ { "_index":"shijiange", "_type":"users", "_id":1 }, { "_index":"shijiange888", "_type":"users", "_source":"name", "_id":1 }] } PUT /shijiange/users/122 { "name": "justdoit", "age": 45 } GET /_cat/count?v POST /shijiange/users/1/_update { "doc": { "age": 29 } } GET /shijiange/_search?q=* PUT /test
ELK功能
1. Kibana用来展现数据
2. Elasticsearch用来存储数据
3. Logstash用来收集数据
Logstash的安装
4. 依赖于Java环境
5. 下载二进制安装文件
6. 解压到对应目录完成安装/usr/local/
Logstash的安装脚本
cd /usr/local/src
tar -zxf logstash-6.6.0.tar.gz
mv logstash-6.6.0 /usr/local/
Logstash的JVM配置文件更新/usr/local/logstash-6.6.0/config/jvm.options
-Xms200M
-Xmx200M
Logstash支持
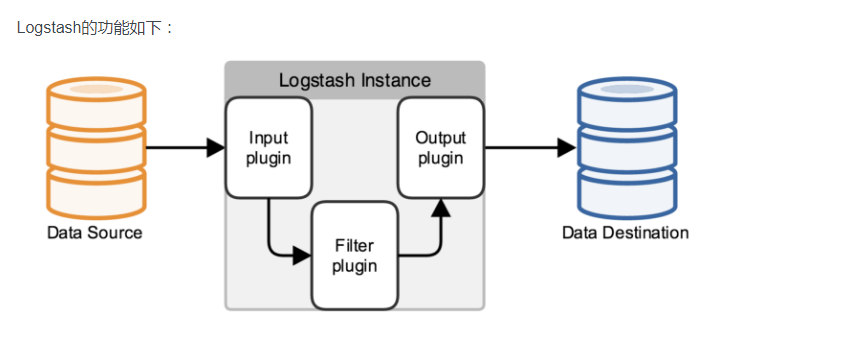
7. Logstash分为输入、输出
8. 输入:标准输入、日志等
9. 输出:标准输出、ES等
Logstash最简单配置/usr/local/logstash-6.6.0/config/logstash.conf
input{
stdin{}
}
output{
stdout{
codec=>rubydebug
}
}
Logstash的启动和测试
10. yum install haveged -y; systemctl enable haveged; systemctl start haveged
11. 前台启动:/usr/local/logstash-6.6.0/bin/logstash -f /usr/local/logstash-6.6.0/config/logstash.conf
12. 后台启动:nohup /usr/local/logstash-6.6.0/bin/logstash -f /usr/local/logstash-6.6.0/config/logstash.conf >/tmp/logstash.lo
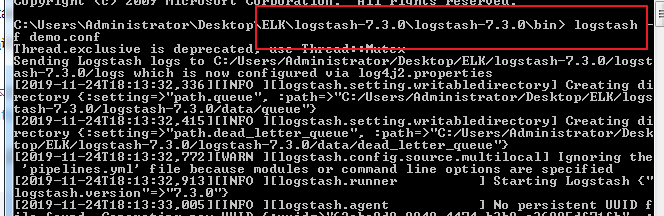
windows安装logstash6.2.3
1 下载地址:logstash
2 解压文件: D:\Program Files\elasticsearch-6.2.3\logstash-6.2.3
3 进入bin目录,新建文件 logstash_default.conf
input {
stdin{
}
}
output {
stdout{
}
}
4 在bin目录,新文件文件 run_default.bat
logstash -f logstash_default.conf
这里特别需要强调的是目录一定不能存在中午名称,否则会出现下面的错误
Logstash读取日志/usr/local/logstash-6.6.0/config/logstash.conf
input {
file {
path => "/var/log/secure"
}
}
output{
stdout{
codec=>rubydebug
}
}
Logstash 在window系统中读取文件的坑
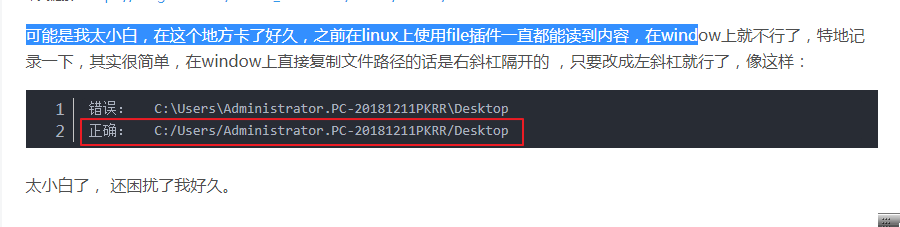
input { file { path => "C:/Users/Administrator/Desktop/ELK/logstash-7.3.0/logstash-7.3.0/bin/filelogdemo.log" } } output{ stdout{ codec=>rubydebug } }
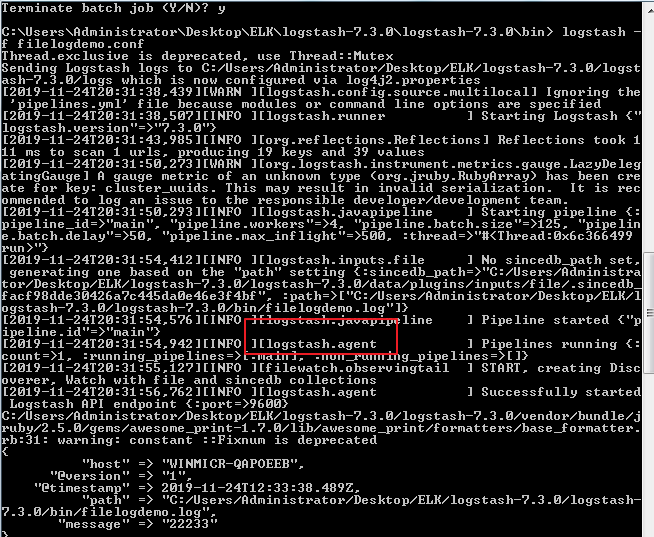
logstash收集日志存在一个agent用来收集日志,logstash存在巨大的问题就是性能消耗太多,占用太多的cpu和内存
08_Logstash读取日志发送到ES.docx
Logstash和ES结合说明
3. Logstash支持读取日志发送到ES
4. 但Logstash用来收集日志比较重,后面将对这个进行优化
Logstash配置发送日志到ES数据库/usr/local/logstash-6.6.0/config/logstash.conf
input {
file {
path => "/usr/local/nginx/logs/access.log"
}
}
output {
elasticsearch {
hosts => ["http://192.168.237.50:9200"]
}
}
windows下的配置文件为
input { file { path => "C:/Users/Administrator/Desktop/ELK/logstash-7.3.0/logstash-7.3.0/bin/filelogdemo.log" } } output { elasticsearch { hosts => ["http://localhost:9200"] } }
Logstash收集日志必要点
7. 日志文件需要有新日志产生。例如当前存在filelogdemo.log已经存在了10M内容,logstash是不能读取10M的历史数据的,只有数据发生了变化logstash才能更新
8. Logstash跟Elasticsearch要能通讯
当日志文件发生改变的时候,在kibana中会产生logstash-2019.11.24 名称的索引,其中2019.11.24是当前的日期,索引名称会随着日期的改变而改变
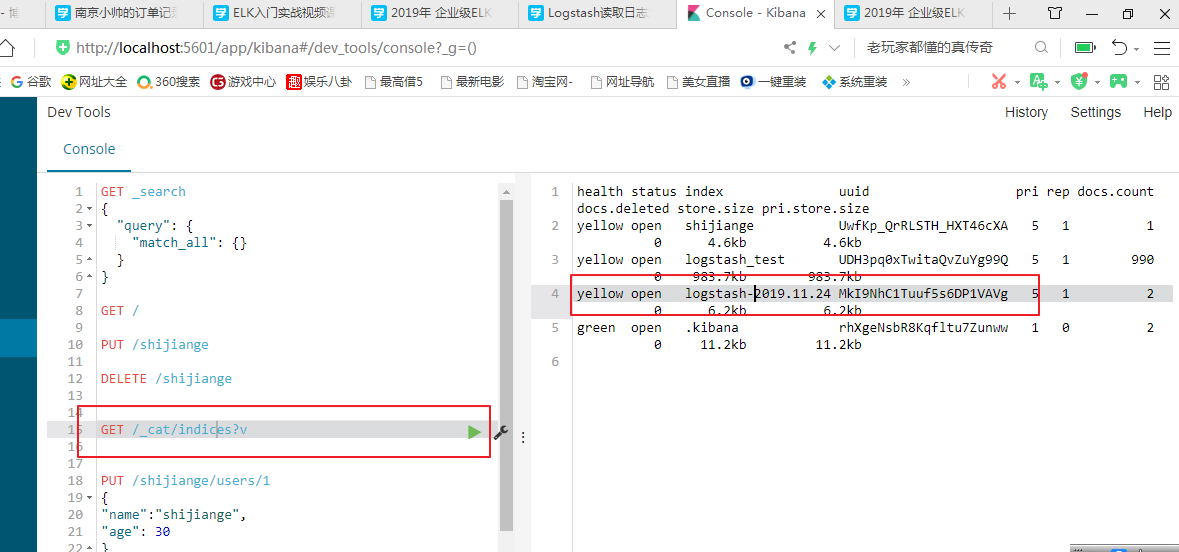
Kibana上查询数据
9.GET /logstash-2019.11.24/_search?q=*
10.Kibana上创建索引直接查看日志
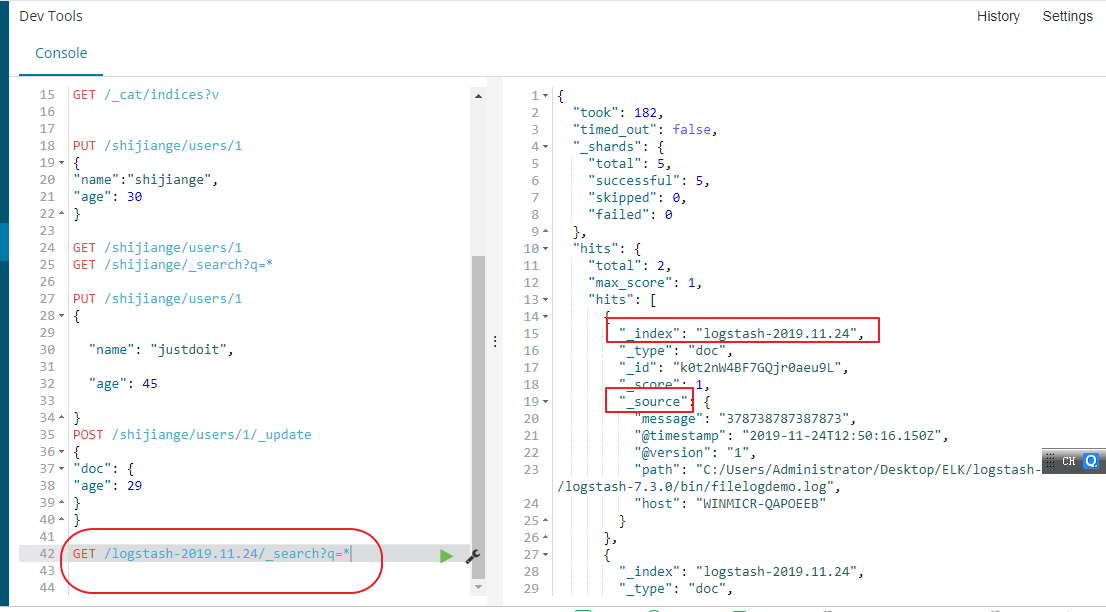
接下来我们讲解在kibana面板中查看上面变更的日志,点击管理

选择创建索引,填写索引的表达式

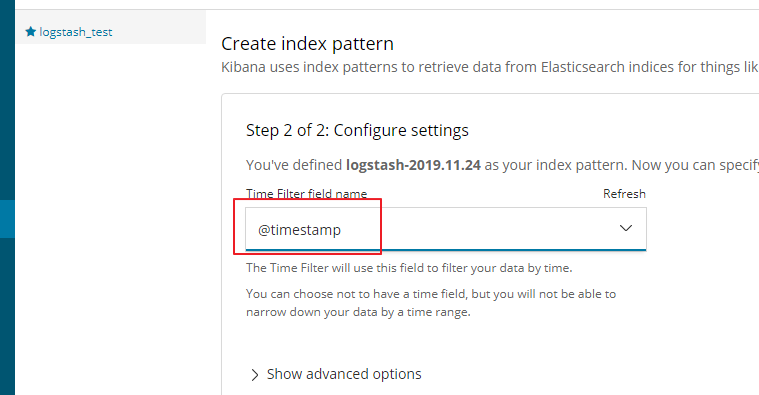
这里一定要选择时间窗口
这里就创建好了,接下来在主页面板就可以看见我们创建的数据了
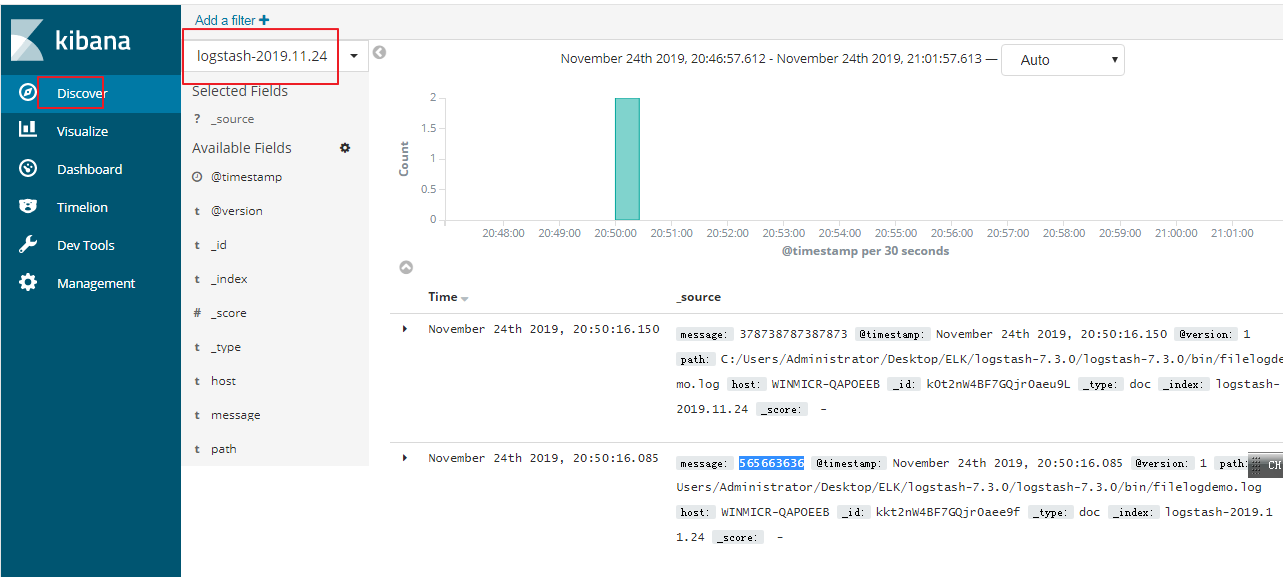
Kibana简单查询
11.根据字段查询:message: "_msearch"
12.根据字段查询:选中查询
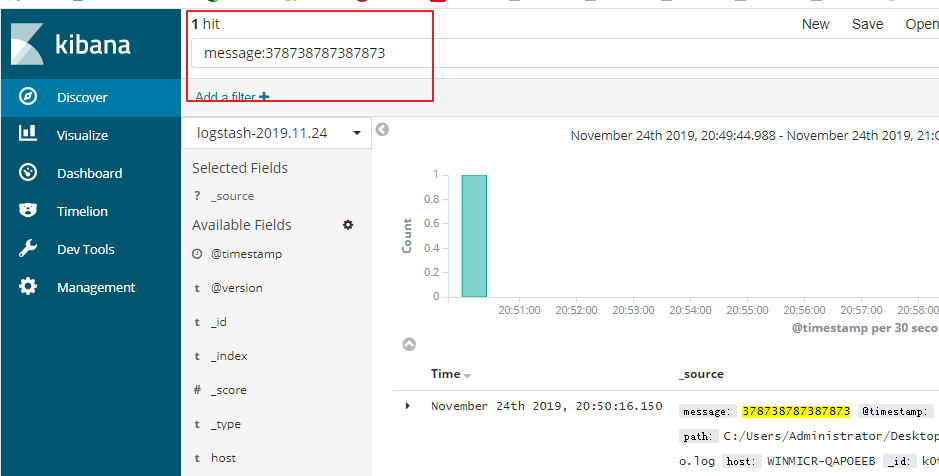
现在我们只在kibana上面只能某一条日志如何实现了,我们可以依据这样记录的_id,做一个过滤就可以了
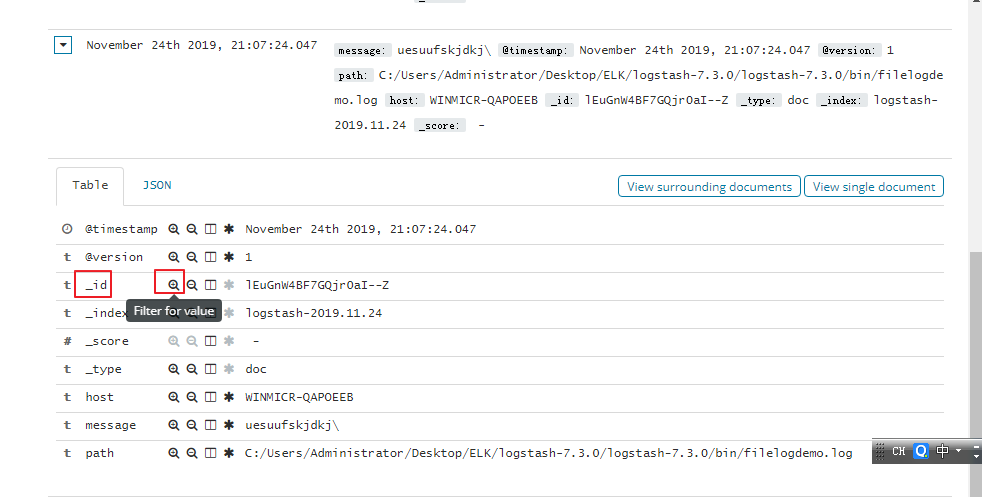
点击加号,这样我们就为_id创建了一个过滤器,对应的值是唯一的,只显示一条记录
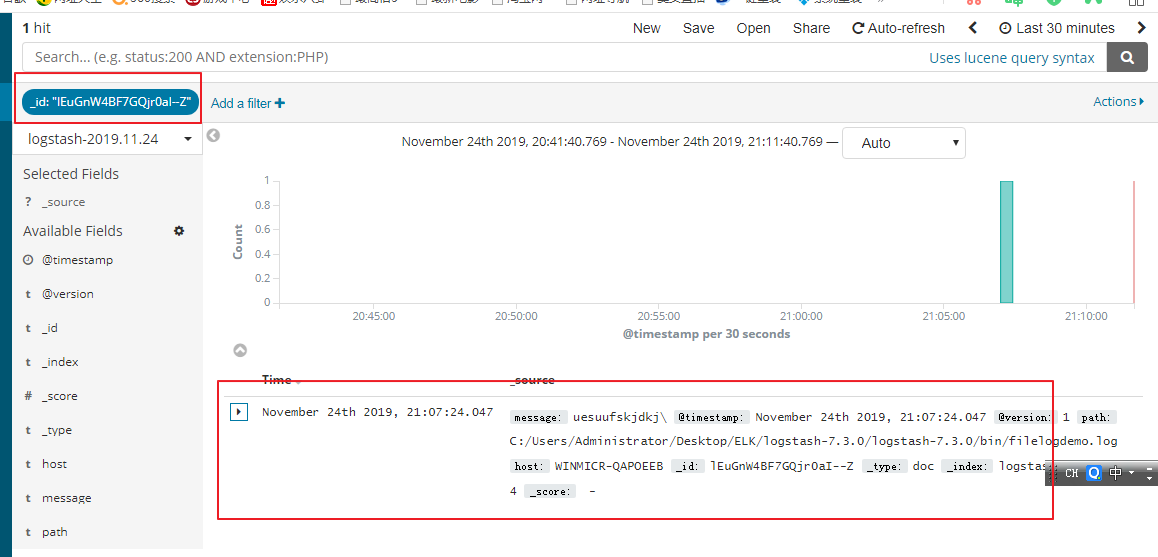
选择编辑,我们还可以对过滤器的条件进行编辑操作
发送整行日志存在的问题 1. 整行message一般我们并不关心 2. 需要对message进行段拆分,需要用到正则表达式 正则表达式 3. 使用给定好的符号去表示某个含义 4. 例如.代表任意字符 5. 正则符号当普通符号使用需要加反斜杠 正则的发展 6. 普通正则表达式 7. 扩展正则表达式 普通正则表达式 . 任意一个字符 * 前面一个字符出现0次或者多次 [abc] 中括号内任意一个字符 [^abc] 非中括号内的字符 [0-9] 表示一个数字 [a-z] 小写字母 [A-Z] 大写字母 [a-zA-Z] 所有字母 [a-zA-Z0-9] 所有字母+数字 [^0-9] 非数字 ^xx 以xx开头 xx$ 以xx结尾 \d 任何一个数字 \s 任何一个空白字符 扩展正则表达式,在普通正则符号再进行了扩展 ? 前面字符出现0或者1次 + 前面字符出现1或者多次 {n} 前面字符匹配n次 {a,b} 前面字符匹配a到b次 {,b} 前面字符匹配0次到b次 {a,} 前面字符匹配a或a+次 (string1|string2) string1或string2 简单提取IP 8. 1.1.1.1 114.114.114.114 255.277.277.277 9. 1-3个数字.1-3个数字.1-3个数字.1-3个数字 10. [0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3} 11. 多提取
[0-9]{1,3}\.其中[0-9][1,3]表示0到9的数字前面的数值匹配1到3次,可以是9、18、192这种类型,接下来是点,在正则表达式中点具有特殊的意义.表示任意一个字符,现在我们要使用点需要进行转义
前面加上一个\
10_Logstash正则分析Nginx日志.docx
首先我们要安装nginx

nginx的相关操作如下
windows 批量杀nginx进程 输入taskkill /fi "imagename eq nginx.EXE" /f,可以杀死名字为 nginx.EXE的所有进程 3、windows上面启动nginx进程 在Windows下操作nginx,需要打开cmd 进入到nginx的安装目录下 1.启动nginx: start nginx 或 nginx.exe 2.停止nginx(stop是快速停止nginx,可能并不保存相关信息;quit是完整有序的停止nginx,并保存相关信息) nginx.exe -s stop 或 nginx.exe -s quit 3.检查 重启: nginx -t 修改nginx配置后执行检查配置是否正确
我们修改logstash的配置文件如下
input { file { path => "C:/Users/Administrator/Desktop/ELK/nginx-1.15.5/nginx-1.15.5/logs/access.log" } } output { elasticsearch { hosts => ["http://localhost:9200"] } }
我们监听nginx的请求日志,当浏览器访问nginx的时候,access.log就会发生变化,kibana就能够展示
Nginx日志说明 1. 192.168.237.1 - - [24/Feb/2019:17:48:47 +0800] "GET /shijiange HTTP/1.1" 404 571 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36" 2. 访问IP地址 3. 访问时间 4. 请求方式(GET/POST) 5. 请求URL 6. 状态码 7. 响应body大小 8. Referer 9. User Agent Logstash正则提取日志 10. 需要懂得正则,Logstash支持普通正则和扩展正则 11. 需要了解Grok,利用Kibana的Grok学习Logstash正则提取日志 Grok提取Nginx日志 12. Grok使用(?<xxx>提取内容)来提取xxx字段 13. 提取客户端IP: (?<clientip>[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}) 14. 提取时间: \[(?<requesttime>[^ ]+ \+[0-9]+)\]
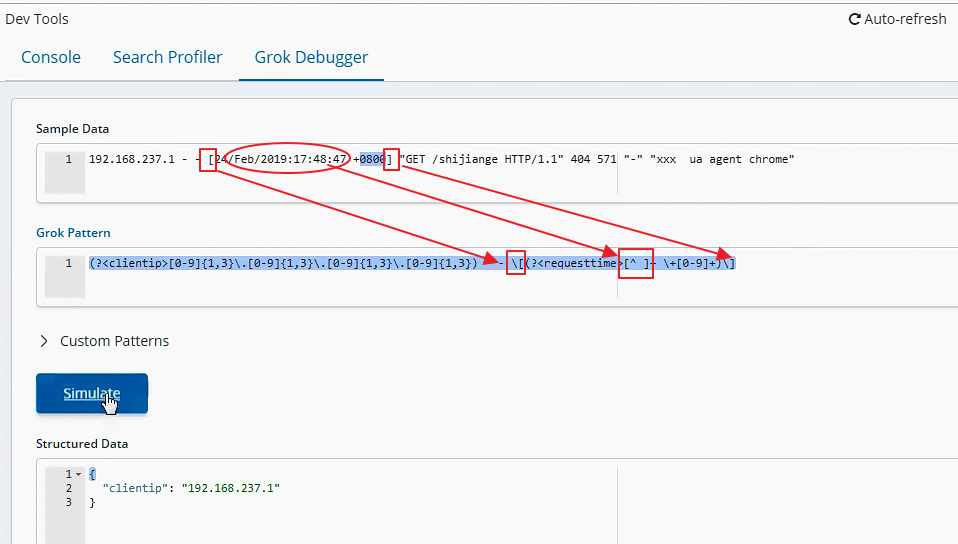
\[(?<requesttime>[^ ]+ \+[0-9]+)\]
[24/Feb/2019:17:48:47 +0800]首先最外层的大括号要显示大阔号最外层需要添加上转义字符,接下来要提取24/Feb/2019:17:48:47,这就是非空格的字符
[^ ]+,其中[^ ]就是提取非空格的字符([^abc] 非中括号内的字符),+表示非空格的字符可以出现多少次(+ 前面字符出现1或者多次)
接下来要提取+0800
\+[0-9]+,第一要要显示加号,需要进行转义,[0-9]+表示0到9的数字可以出现多次
Grok提取Nginx日志
15. (?<clientip>[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}) - - \[(?<requesttime>[^ ]+ \+[0-9]+)\] "(?<requesttype>[A-Z]+) (?<requesturl>[^ ]+) HTTP/\d.\d" (?<status>[0-9]+) (?<bodysize>[0-9]+) "[^"]+" "(?<ua>[^"]+)"
16. 提取Tomcat等日志使用类似的方法
Logstash正则提取Nginx日志
input {
file {
path => "/usr/local/nginx/logs/access.log"
}
}
filter {
grok {
match => {
"message" => '(?<clientip>[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}) - - \[(?<requesttime>[^ ]+ \+[0-9]+)\] "(?<requesttype>[A-Z]+) (?<requesturl>[^ ]+) HTTP/\d.\d" (?<status>[0-9]+) (?<bodysize>[0-9]+) "[^"]+" "(?<ua>[^"]+)"'
}
}
}
output {
elasticsearch {
hosts => ["http://192.168.237.50:9200"]
}
}
整个配置文件内容如下
input { file { path => "C:/Users/Administrator/Desktop/ELK/nginx-1.15.5/nginx-1.15.5/logs/access.log" } } filter { grok { match => { "message" => '(?<clientip>[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}) - - \[(?<requesttime>[^ ]+ \+[0-9]+)\] "(?<requesttype>[A-Z]+) (?<requesturl>[^ ]+) HTTP/\d.\d" (?<status>[0-9]+) (?<bodysize>[0-9]+) "[^"]+" "(?<ua>[^"]+)"' } } } output { elasticsearch { hosts => ["http://localhost:9200"] } }

如果集成成功,访问了nginx,执行方法GET /_cat/indices?v对于的索引值大小会发生变化
在有效的字段下面会增加下面的字段信息

点击字段,可以看到字段具体的信息
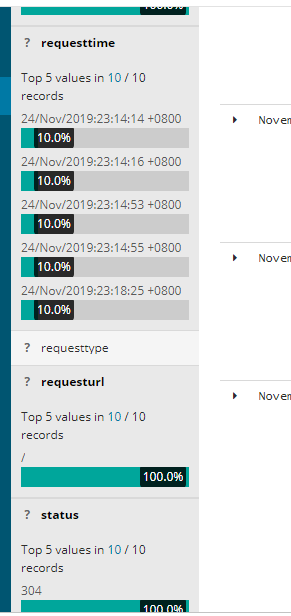
注意正则提取失败的情况时候。我们在access.log中添加一条不规则的数据,提取失败我们不应该把数据保存到es中

Logstash正则提取出错就不输出到ES
output{
if "_grokparsefailure" not in [tags] and "_dateparsefailure" not in [tags] {
elasticsearch {
hosts => ["http://192.168.237.50:9200"]
}
}
}
具体配置文件如下
input { file { path => "C:/Users/Administrator/Desktop/ELK/nginx-1.15.5/nginx-1.15.5/logs/access.log" } } filter { grok { match => { "message" => '(?<clientip>[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}) - - \[(?<requesttime>[^ ]+ \+[0-9]+)\] "(?<requesttype>[A-Z]+) (?<requesturl>[^ ]+) HTTP/\d.\d" (?<status>[0-9]+) (?<bodysize>[0-9]+) "[^"]+" "(?<ua>[^"]+)"' } } } output{ if "_grokparsefailure" not in [tags] and "_dateparsefailure" not in [tags] { elasticsearch { hosts => ["http://localhost:9200"] } } }
11_Logstash去除不需要的字段.docx
去除字段注意
1. 只能去除_source里的
2. 非_source里的去除不了
Logstash配置去除不需要的字段
filter {
grok {
match => {
"message" => '(?<clientip>[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}) - - \[(?<requesttime>[^ ]+ \+[0-9]+)\] "(?<requesttype>[A-Z]+) (?<requesturl>[^ ]+) HTTP/\d.\d" (?<status>[0-9]+) (?<bodysize>[0-9]+) "[^"]+" "(?<ua>[^"]+)"'
}
remove_field => ["message","@version","path"]
}
}
去除字段
3. 减小ES数据库的大小
4. 提升搜索效率
未过滤字段的数据
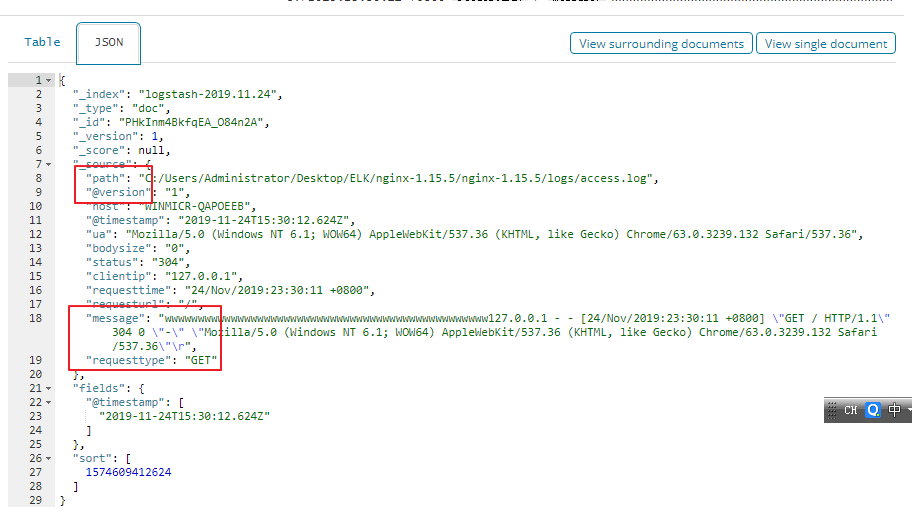
去掉过滤字段之后的数据为

没有了message等字段信息了
12_ELK覆盖时间轴和全量分析Nginx.docx
kibana中对于我们自定义的字段,我们点击add按钮,就可以在右边显示对应的字段信息

logstash默认情况下不会读取以前的历史数据,例如access.log中以前存在很长一段时间的历史数据,我们要读取历史数据,如何做了
Logstash分析所有Nginx日志
input {
file {
path => "/usr/local/nginx/logs/access.log"
start_position => "beginning"
sincedb_path => "/dev/null"
}
}
需要在配置文件中添加上上面的两条记录,注意上面两条只能在linux环境有效
通过配置文件可知,我们增加了一个参数sincedb_path,其值为“/dev/null”,这个参数的是用来配置记录logstash读取日志文件位置的文件的名称的,我们将文件的名称指定为“/dev/null”这个 Linux 系统上特殊的空洞文件,那么 logstash 每次重启进程的时候,尝试读取 sincedb 内容,都只会读到空白内容,也就会理解成之前没有过运行记录,自然就从初始位置开始读取了!
在windows上测试需要删除掉
input { file { path => "C:/Users/Administrator/Desktop/ELK/nginx-1.15.5/nginx-1.15.5/logs/access.log" start_position => "beginning" sincedb_path => "/dev/null" } } filter { grok { match => { "message" => '(?<clientip>[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}) - - \[(?<requesttime>[^ ]+ \+[0-9]+)\] "(?<requesttype>[A-Z]+) (?<requesturl>[^ ]+) HTTP/\d.\d" (?<status>[0-9]+) (?<bodysize>[0-9]+) "[^"]+" "(?<ua>[^"]+)"' } remove_field => ["message","@version","path"] } } output{ if "_grokparsefailure" not in [tags] and "_dateparsefailure" not in [tags] { elasticsearch { hosts => ["http://localhost:9200"] } } }
我们重新启动下,看下效果
默认ELK时间轴
1. 以发送日志的时间为准
2. 而Nginx上本身记录着用户的访问时间
3. 分析Nginx上的日志以用户的访问时间为准,而不以发送日志的时间
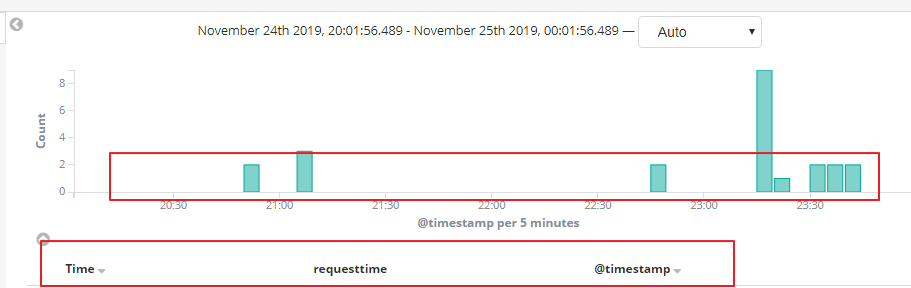

我们明显的可以看到requesttime @timestamp明显不一致,现在我们想以用户的requesttime请求时间来设置kibana的时间轴,如何实现了
Logstash的filter里面加入配置24/Feb/2019:21:08:34 +0800
filter {
grok {
match => {
"message" => '(?<clientip>[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}) - - \[(?<requesttime>[^ ]+ \+[0-9]+)\] "(?<requesttype>[A-Z]+) (?<requesturl>[^ ]+) HTTP/\d.\d" (?<status>[0-9]+) (?<bodysize>[0-9]+) "[^"]+" "(?<ua>[^"]+)"'
}
remove_field => ["message","@version","path"]
}
date {
match => ["requesttime", "dd/MMM/yyyy:HH:mm:ss Z"]
target => "@timestamp"
}
}
统计Nginx的请求和网页显示进行对比
cat /usr/local/nginx/logs/access.log |awk '{print $4}'|cut -b 1-19|sort |uniq -c
不同的时间格式,覆盖的时候格式要对应
4. 20/Feb/2019:14:50:06 -> dd/MMM/yyyy:HH:mm:ss
5. 2016-08-24 18:05:39,830 -> yyyy-MM-dd HH:mm:ss,SSS
整个配置文件如下所示
input { file { path => "C:/Users/Administrator/Desktop/ELK/nginx-1.15.5/nginx-1.15.5/logs/access.log" } } filter { grok { match => { "message" => '(?<clientip>[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}) - - \[(?<requesttime>[^ ]+ \+[0-9]+)\] "(?<requesttype>[A-Z]+) (?<requesturl>[^ ]+) HTTP/\d.\d" (?<status>[0-9]+) (?<bodysize>[0-9]+) "[^"]+" "(?<ua>[^"]+)"' } remove_field => ["message","@version","path"] } date { match => ["requesttime", "dd/MMM/yyyy:HH:mm:ss Z"] target => "@timestamp" } } output{ if "_grokparsefailure" not in [tags] and "_dateparsefailure" not in [tags] { elasticsearch { hosts => ["http://localhost:9200"] } } }
Logstash收集日志
- 依赖于Java环境,用来收集日志比较重,占用内存和CPU
- Filebeat相对轻量,占用服务器资源小
- 一般选用Filebeat来进行日志收
logstash运行必须服务器要安装了jdk,依赖java环境,如果当前运行的收集的日志没有jdk,那么就无法收集日志,并且logstash占用内存和cpu
Filebeat收集到日志可以不依赖logstash直接将数据传递给es,如果需要对日志进行分析和过滤就需要logstash,filebeat不依赖java环境
Filebeat的安装
- 下载二进制文件
- 解压移到对应的目录完成安装/usr/local/
Filebeat的二进制安装
cd /usr/local/src/
tar -zxf filebeat-6.6.0-linux-x86_64.tar.gz
mv filebeat-6.6.0-linux-x86_64 /usr/local/filebeat-6.6.0
部署服务介绍
- 192.168.237.50: Kibana、ES
- 192.168.237.51: Filebeat
Filebeat发送日志到ES配置/usr/local/filebeat-6.6.0/filebeat.yml
filebeat.inputs:
- type: log
tail_files: true
backoff: "1s"
paths:
- /usr/local/nginx/logs/access.log
output:
elasticsearch:
hosts: ["192.168.237.50:9200"]
启动Filebeat
- 前台启动: /usr/local/filebeat-6.6.0/filebeat -e -c /usr/local/filebeat-6.6.0/filebeat.yml
- 后台启动:nohup /usr/local/filebeat-6.6.0/filebeat -e -c /usr/local/filebeat-6.6.0/filebeat.yml >/tmp/filebeat.log 2>&1 &
Kibana上查看日志数据
- GET /xxx/_search?q=*
- 创建索引观察
Filebeat -> ES -> Kibana
- 适合查看日志
- 不适合具体日志的分析
backoff: "1s"
在windows环境上整个配置文件如下
filebeat.prospectors: # Each - is a prospector. Most options can be set at the prospector level, so # you can use different prospectors for various configurations. # Below are the prospector specific configurations. - type: log # Change to true to enable this prospector configuration. enabled: true # Paths that should be crawled and fetched. Glob based paths. paths: #- /var/log/*.log - C:/Users/Administrator/Desktop/ELK/nginx-1.15.5/nginx-1.15.5/logs/access.log #============================= Filebeat modules =============================== filebeat.config.modules: # Glob pattern for configuration loading path: ${path.config}/modules.d/*.yml # Set to true to enable config reloading reload.enabled: true # Period on which files under path should be checked for changes #reload.period: 10s #==================== Elasticsearch template setting ========================== setup.template.settings: index.number_of_shards: 3 #index.codec: best_compression #_source.enabled: false setup.kibana: #-------------------------- Elasticsearch output ------------------------------ #output.elasticsearch: # Array of hosts to connect to. #hosts: ["localhost:9200"] # Optional protocol and basic auth credentials. #protocol: "https" #username: "elastic" #password: "changeme" #----------------------------- Logstash output -------------------------------- output: elasticsearch: hosts: ["localhost:9200"]
filebeat直接将数据发送给es,会产生filebeat开头当前时间结尾的索引
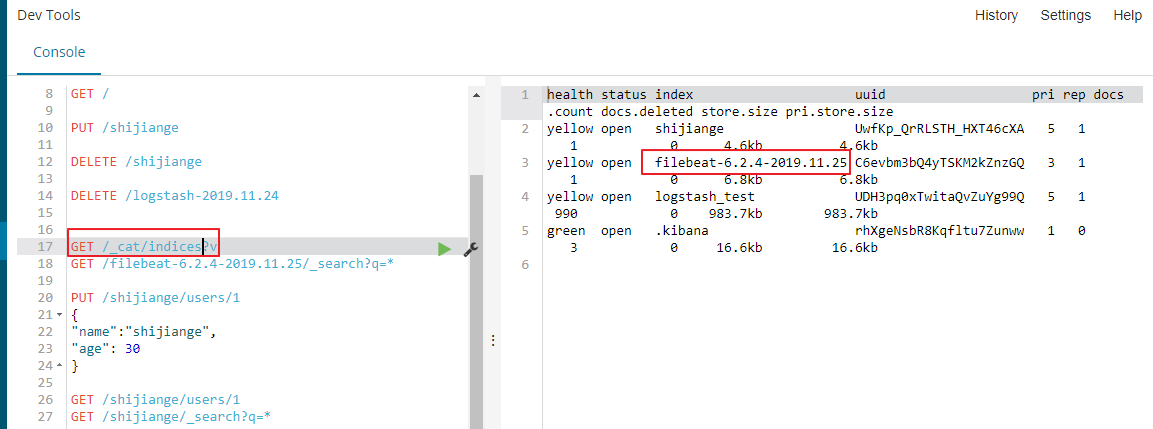
索引的日志内容如下
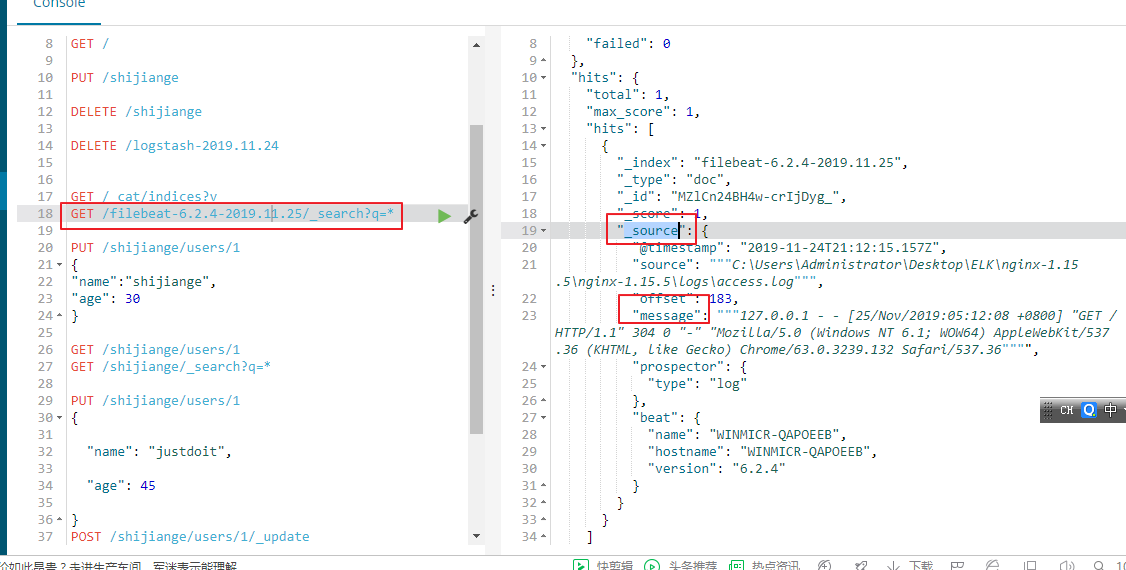
我们可以创建索引在kibana中进行展示

14_Filebeat+Logstash新架构.docx
首先需要修改logstash的配置文件
之前logstash的配置文件如下
input { file { path => "C:/Users/Administrator/Desktop/ELK/nginx-1.15.5/nginx-1.15.5/logs/access.log" } } filter { grok { match => { "message" => '(?<clientip>[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}) - - \[(?<requesttime>[^ ]+ \+[0-9]+)\] "(?<requesttype>[A-Z]+) (?<requesturl>[^ ]+) HTTP/\d.\d" (?<status>[0-9]+) (?<bodysize>[0-9]+) "[^"]+" "(?<ua>[^"]+)"' } remove_field => ["message","@version","path"] } date { match => ["requesttime", "dd/MMM/yyyy:HH:mm:ss Z"] target => "@timestamp" } } output{ if "_grokparsefailure" not in [tags] and "_dateparsefailure" not in [tags] { elasticsearch { hosts => ["http://localhost:9200"] } } }
filter和output我们都不需要修改,只需要修改input,让input接入filebeat传递的数据,filtebeat传递的数据还是存在message信息
input { beats { host => '0.0.0.0' port => 5044 } } filter { grok { match => { "message" => '(?<clientip>[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}) - - \[(?<requesttime>[^ ]+ \+[0-9]+)\] "(?<requesttype>[A-Z]+) (?<requesturl>[^ ]+) HTTP/\d.\d" (?<status>[0-9]+) (?<bodysize>[0-9]+) "[^"]+" "(?<ua>[^"]+)"' } remove_field => ["message","@version","path"] } date { match => ["requesttime", "dd/MMM/yyyy:HH:mm:ss Z"] target => "@timestamp" } } output{ if "_grokparsefailure" not in [tags] and "_dateparsefailure" not in [tags] { elasticsearch { hosts => ["http://localhost:9200"] } } }
此外filebeat的配置文件也需要修改
filebeat.prospectors:
# Each - is a prospector. Most options can be set at the prospector level, so
# you can use different prospectors for various configurations.
# Below are the prospector specific configurations.
- type: log
# Change to true to enable this prospector configuration.
enabled: true
# Paths that should be crawled and fetched. Glob based paths.
paths:
#- /var/log/*.log
- C:/Users/Administrator/Desktop/ELK/nginx-1.15.5/nginx-1.15.5/logs/access.log
#============================= Filebeat modules ===============================
filebeat.config.modules:
# Glob pattern for configuration loading
path: ${path.config}/modules.d/*.yml
# Set to true to enable config reloading
reload.enabled: true
# Period on which files under path should be checked for changes
#reload.period: 10s
#==================== Elasticsearch template setting ==========================
setup.template.settings:
index.number_of_shards: 3
#index.codec: best_compression
#_source.enabled: false
setup.kibana:
#-------------------------- Elasticsearch output ------------------------------
#output.elasticsearch:
# Array of hosts to connect to.
#hosts: ["localhost:9200"]
# Optional protocol and basic auth credentials.
#protocol: "https"
#username: "elastic"
#password: "changeme"
#----------------------------- Logstash output --------------------------------
output:
logstash:
hosts: ["localhost:5044"]
Filebeat发过来的无用字段比较多,需要重新对logstash上的文件进行配置,去除无效字段
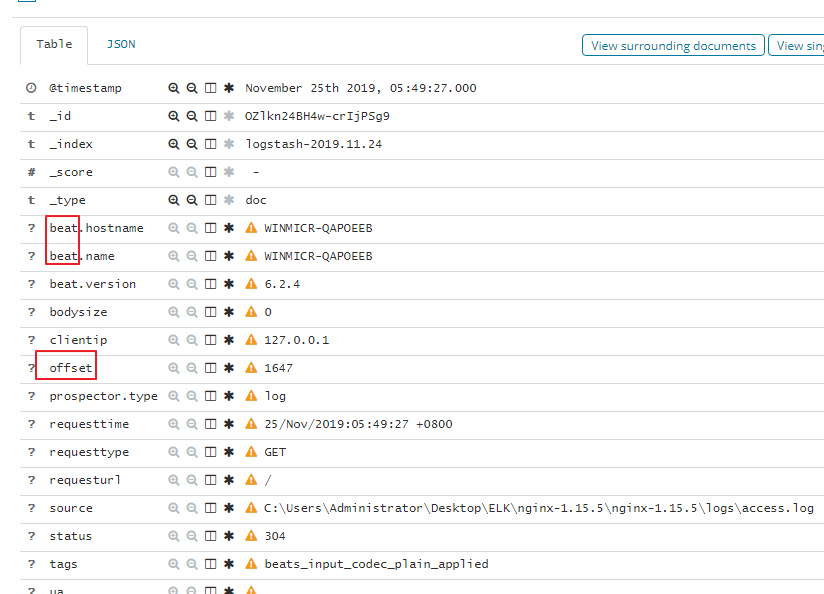
remove_field => ["message","@version","path","beat","input","log","offset","prospector","source","tags"]
logstash的配置文件修改为如下
input { beats { host => '0.0.0.0' port => 5044 } } filter { grok { match => { "message" => '(?<clientip>[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}) - - \[(?<requesttime>[^ ]+ \+[0-9]+)\] "(?<requesttype>[A-Z]+) (?<requesturl>[^ ]+) HTTP/\d.\d" (?<status>[0-9]+) (?<bodysize>[0-9]+) "[^"]+" "(?<ua>[^"]+)"' } remove_field => ["message","@version","path","beat","input","log","offset","prospector","source","tags"] } date { match => ["requesttime", "dd/MMM/yyyy:HH:mm:ss Z"] target => "@timestamp" } } output{ if "_grokparsefailure" not in [tags] and "_dateparsefailure" not in [tags] { elasticsearch { hosts => ["http://localhost:9200"] } } }
整个修改如下
Filebeat和Logstash说明
1. Filebeat:轻量级,但不支持正则、不能移除字段等
2. Logstash:比较重,但支持正则、支持移除字段等
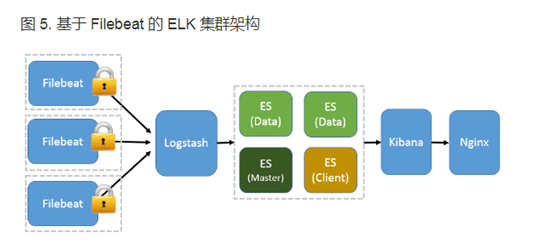
搭建架构演示
3. Logstash -> Elasticsearch -> Kibana
4. Filebeat -> Elasticsearch -> Kibana
5. Filebeat -> Logstash -> Elasticsearch -> Kibana
部署服务介绍
6. 192.168.237.50: Kibana、ES
7. 192.168.237.51: Logstash、Filebeat
Filebeat配置发往Logstash
filebeat.inputs:
- type: log
tail_files: true
backoff: "1s"
paths:
- /usr/local/nginx/logs/access.log
output:
logstash:
hosts: ["192.168.237.51:5044"]
Logstash配置监听在5044端口,接收Filebeat发送过来的日志
input {
beats {
host => '0.0.0.0'
port => 5044
}
}
Kibana上查看数据
8. GET /xxx/_search?q=*
9. 创建索引查看数据
Logstash上移除不必要的字段
10. Filebeat发过来的无用字段比较多
11. remove_field => ["message","@version","path","beat","input","log","offset","prospector","source","tags"]
Filebeat批量部署比Logstash要方便得多
12. Logstash监听在内网
13. Filebeat发送给内网的Logstash
新架构
Filebeat(多台)
Filebeat(多台) -> Logstash(正则) -> Elasticsearch(入库) -> Kibana展现
Filebeat(多台)
这里需要特别注意的是日志文件是logstash存储到es的,所以创建的索引默认是logstash开始的,filebeat不再把数据存储到es,所以索引不是filebeat开始的,这里需要注意下
15_Json格式日志的采集.docx
第一需要修改nginx产生的日志文件为json的格式
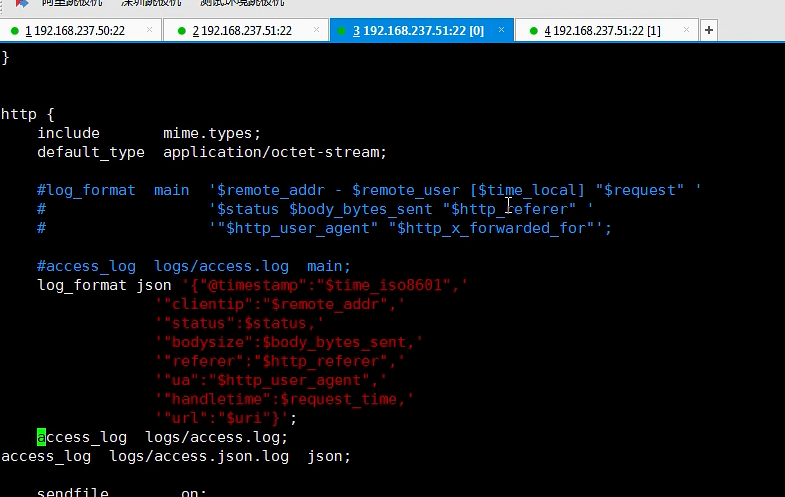
上面nginx会产生两个日志一个是原生的access.log日志,另外一种是json的日志access.json.log

第二因为filebeat发送过来的数据是json格式,所以logstash不需要在进行正则表达式的过滤,需要进行修改‘
input {
beats {
host => '0.0.0.0'
port => 5044
}
}
filter {
json { source => "message" remove_field => ["message","@version","path","beat","input","log","offset","prospector","source","tags"] }
}
output {
elasticsearch {
hosts => ["http://localhost:9200"]
}
doc
Json的好处
1. 原生日志需要做正则匹配,比较麻烦
2. Json格式的日志不需要正则能直接分段采集
Nginx使用Json格式日志
log_format json '{"@timestamp":"$time_iso8601",'
'"clientip":"$remote_addr",'
'"status":$status,'
'"bodysize":$body_bytes_sent,'
'"referer":"$http_referer",'
'"ua":"$http_user_agent",'
'"handletime":$request_time,'
'"url":"$uri"}';
access_log logs/access.log;
access_log logs/access.json.log json;
部署服务介绍
3. 192.168.237.50: Kibana、ES
4. 192.168.237.51: Logstash、Filebeat
Filebeat采集Json格式的日志
filebeat.inputs:
- type: log
tail_files: true
backoff: "1s"
paths:
- /usr/local/nginx/logs/access.json.log
output:
logstash:
hosts: ["192.168.237.51:5044"]
Logstash解析Json日志
input {
beats {
host => '0.0.0.0'
port => 5044
}
}
filter {
json { source => "message" remove_field => ["message","@version","path","beat","input","log","offset","prospector","source","tags"] }
}
output {
elasticsearch {
hosts => ["http://192.168.237.50:9200"]
}
}
16_Filebeat采集多个日志.docx
采集多个日志
1. 收集单个Nginx日志
2. 如果有采集多个日志的需求
Filebeat采集多个日志配置
filebeat.inputs:
- type: log
tail_files: true
backoff: "1s"
paths:
- /usr/local/nginx/logs/access.json.log
fields:
type: access
fields_under_root: true
- type: log
tail_files: true
backoff: "1s"
paths:
- /var/log/secure
fields:
type: secure
fields_under_root: true
output:
logstash:
hosts: ["192.168.237.51:5044"]
Logstash如何判断两个日志
3. Filebeat加入一字段用来区别
4. Logstash使用区别字段来区分
Logstash通过type字段进行判断
input {
beats {
host => '0.0.0.0'
port => 5044
}
}
filter {
if [type] == "access" {
json {
source => "message"
remove_field => ["message","@version","path","beat","input","log","offset","prospector","source","tags"]
}
}
}
output{
if [type] == "access" {
elasticsearch {
hosts => ["http://192.168.237.50:9200"]
index => "access-%{+YYYY.MM.dd}"
}
}
else if [type] == "secure" {
elasticsearch {
hosts => ["http://192.168.237.50:9200"]
index => "secure-%{+YYYY.MM.dd}"
}
}
}
网页上建立索引
5. access索引
6. secure索引
filebeat收集两个日志
/var/log/secure
/usr/local/nginx/logs/access.json.log
所以在filebeat中配置文件中新增加了一个type字段,用来区分两种日志的类型
其中 /usr/local/nginx/logs/access.json.log是json格式在logstash中进行json解析, /var/log/secure不是json格式在logstash中不进行转换直接发生给es,
两个日志在es中建立不同的名称的索引
17_Redis服务器的编译安装.docx
之前架构
Filebeat(多台)
Filebeat(多台) -> Logstash(正则) -> Elasticsearch(入库) -> Kibana展现
Filebeat(多台)
架构存在的问题
1. Logstash性能不足的时候
2. 扩容Logstash,Filebeat的配置可能会不一致
架构优化
Filebeat(多台) Logstash
Filebeat(多台) -> Redis、Kafka -> Logstash(正则) -> Elasticsearch(入库) -> Kibana展现
Filebeat(多台) Logstash
部署服务介绍
3. 192.168.237.50: Kibana、ES
4. 192.168.237.51: Logstash、Filebeat、Redis
Redis服务器搭建
yum install -y wget net-tools gcc gcc-c++ make tar openssl openssl-devel cmake
cd /usr/local/src
wget 'http://download.redis.io/releases/redis-4.0.9.tar.gz'
tar -zxf redis-4.0.9.tar.gz
cd redis-4.0.9
make
mkdir -pv /usr/local/redis/conf /usr/local/redis/bin
cp src/redis* /usr/local/redis/bin/
cp redis.conf /usr/local/redis/conf
验证Redis服务器
5. 更改Redis配置(daemon、dir、requirepass)
6. 密码设置为shijiange
7. 验证set、get操作
Redis的启动命令
/usr/local/redis/bin/redis-server /usr/local/redis/conf/redis.conf
Redis的简单操作
8. /usr/local/redis/bin/redis-cli
9. auth 'shijiange'
10. set name shijiange
11. get name
18_Filebeat和Logstash间引入Redis.docx
首先需要修改filebeat的配置文件如下
filebeat.prospectors: - type: log # Change to true to enable this prospector configuration. enabled: true # Paths that should be crawled and fetched. Glob based paths. paths: #- /var/log/*.log - C:/Users/Administrator/Desktop/ELK/nginx-1.15.5/nginx-1.15.5/logs/access.log #============================= Filebeat modules =============================== filebeat.config.modules: # Glob pattern for configuration loading path: ${path.config}/modules.d/*.yml # Set to true to enable config reloading reload.enabled: true # Period on which files under path should be checked for changes #reload.period: 10s #==================== Elasticsearch template setting ========================== setup.template.settings: index.number_of_shards: 3 #index.codec: best_compression #_source.enabled: false setup.kibana: output: redis: hosts: ["localhost"] port: 6379 key: 'access' password: '123456'
接下来修改logstash的配置文件
Logstash从Redis中读取数据
input { redis { host => 'localhost' port => 6379 key => "access" data_type => "list" password => '123456' } } filter { grok { match => { "message" => '(?<clientip>[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}) - - \[(?<requesttime>[^ ]+ \+[0-9]+)\] "(?<requesttype>[A-Z]+) (?<requesturl>[^ ]+) HTTP/\d.\d" (?<status>[0-9]+) (?<bodysize>[0-9]+) "[^"]+" "(?<ua>[^"]+)"' } remove_field => ["message","@version","path","beat","input","log","offset","prospector","source","tags"] } date { match => ["requesttime", "dd/MMM/yyyy:HH:mm:ss Z"] target => "@timestamp" } } output{ if "_grokparsefailure" not in [tags] and "_dateparsefailure" not in [tags] { elasticsearch { hosts => ["http://localhost:9200"] } } }
这里特别需要强调的是一定给nginx服务器设置密码,否则会报错
Windows下安装redis并且设置密码
使用记事本打开文件:redis-windows.conf.
设置redis的密码:
全局搜索requirepass找到后打开注释,并且在后面添加自己的密码,博主密码设置的是123456,如下图所示:
设置好后保存退出,cmd进入Windows命令窗口:切换到解压文件目录下,运行命令:
redis-server.exe redis-windows.conf
使用redis-windows.conf的配置,启动redis-server.exe,启动后界面如下图所示:
可以看到redis的版本号和监听的端口证明redis服务端启动成功,
测试存入取出数据:
另开一个命令窗口,运行redis客户端,键入命令:redis-cli.exe -h 127.0.0.1 -a 123456
命令的格式是;redis-cli.exe -h IP -a password
在不输入密码时对数据的存取效果如下,如图所示,不输入密码时存取数据有误,不能进行存取操作,输入密码后存取成功!
19_Kafka服务器二进制安装.docx
19_Kafka服务器二进 制安装.docxz 实战环境 192.168.237.51: Logstash、Kafka、Filebeat Kafka 1. Kafka依赖于Zookkeeper 2. 两个都依赖于Java Kafka依赖于Zookeeper 3. 官方网站:https://zookeeper.apache.org/ 4. 下载ZK的二进制包 5. 解压到对应目录完成安装 ZK的安装命令 tar -zxf zookeeper-3.4.13.tar.gz mv zookeeper-3.4.13 /usr/local/ cp /usr/local/zookeeper-3.4.13/conf/zoo_sample.cfg /usr/local/zookeeper-3.4.13/conf/zoo.cfg ZK的启动 6. 更改配置:clientPortAddress=0.0.0.0 7. 启动:/usr/local/zookeeper-3.4.13/bin/zkServer.sh start Kafka下载地址 8. Kafka官网:http://kafka.apache.org/ 9. 下载Kafka的二进制包 10. 解压到对应目录完成安装 Kafka的安装命令 cd /usr/local/src/ tar -zxf kafka_2.11-2.1.1.tgz mv kafka_2.11-2.1.1 /usr/local/kafka_2.11 Kafka的启动 11. 更改kafka的配置:更改监听地址、更改连接zk的地址 12. 前台启动:/usr/local/kafka_2.11/bin/kafka-server-start.sh /usr/local/kafka_2.11/config/server.properties 13. 启动kafka:nohup /usr/local/kafka_2.11/bin/kafka-server-start.sh /usr/local/kafka_2.11/config/server.properties >/tmp/kafka.log 2>&1 &
20_Filebeat和Logstash间引入Kafka.docx
filebeat配置文件的修改如下
Filebeat日志发送到Kafka filebeat.inputs: - type: log tail_files: true backoff: "1s" paths: - /usr/local/nginx/logs/access.json.log fields: type: access fields_under_root: true output: kafka: hosts: ["192.168.237.51:9092"] topic: shijiange
windows下面的配置文件如下
filebeat.prospectors: - type: log # Change to true to enable this prospector configuration. enabled: true # Paths that should be crawled and fetched. Glob based paths. paths: #- /var/log/*.log - C:/Users/Administrator/Desktop/ELK/nginx-1.15.5/nginx-1.15.5/logs/access.log #============================= Filebeat modules =============================== filebeat.config.modules: # Glob pattern for configuration loading path: ${path.config}/modules.d/*.yml # Set to true to enable config reloading reload.enabled: true # Period on which files under path should be checked for changes #reload.period: 10s #==================== Elasticsearch template setting ========================== setup.template.settings: index.number_of_shards: 3 #index.codec: best_compression #_source.enabled: false setup.kibana: output: kafka: hosts: ["localhost:9092"] topic: shijiange
接下来需要修改logstash的配置文件
这里我们来进行验证下,我们看到通过filebeat通过kafak收集到的日志信息如下
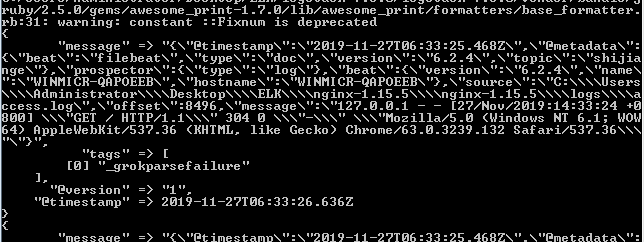
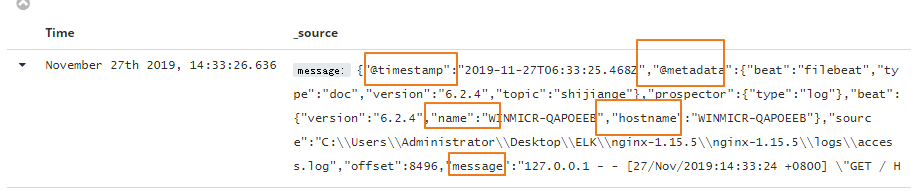
在有效的message数据的前面又重新封装了name hostname metadata等字段信息
kafak对源数据信息进行了修改,logstash如果还继续使用下来的解析方式进行解析,会存在问题

上面这种方式解析会存在问题,会解析失败,我们可以让nginx产生的日志信息为json格式,我们采用json的方式进行解析
Json的好处
1. 原生日志需要做正则匹配,比较麻烦
2. Json格式的日志不需要正则能直接分段采集
nginx需要进行下面的修改
Nginx使用Json格式日志 log_format json '{"@timestamp":"$time_iso8601",' '"clientip":"$remote_addr",' '"status":$status,' '"bodysize":$body_bytes_sent,' '"referer":"$http_referer",' '"ua":"$http_user_agent",' '"handletime":$request_time,' '"url":"$uri"}'; access_log logs/access.log; access_log logs/access.json.log json;

这里比较关键的配置是"@timestamp":"$time_iso8601",使用nginx中用户请求的时间覆盖kibana中默认的@timestamp,这样kibana中的时间轴就是用户访问的请求时间
否则就要按照上面的正则表达式如下所示进行转换
date { match => ["requesttime", "dd/MMM/yyyy:HH:mm:ss Z"] target => "@timestamp" }
在nginx的日志目录下就会产生这样一个日志
因为读取的是nginx的log日志,filebeat需要进行下面的修改
filebeat.prospectors:
- type: log
# Change to true to enable this prospector configuration.
enabled: true
# Paths that should be crawled and fetched. Glob based paths.
paths:
#- /var/log/*.log
- C:/Users/Administrator/Desktop/ELK/nginx-1.15.5/nginx-1.15.5/logs/access.json.log
#============================= Filebeat modules ===============================
filebeat.config.modules:
# Glob pattern for configuration loading
path: ${path.config}/modules.d/*.yml
# Set to true to enable config reloading
reload.enabled: true
# Period on which files under path should be checked for changes
#reload.period: 10s
#==================== Elasticsearch template setting ==========================
setup.template.settings:
index.number_of_shards: 3
#index.codec: best_compression
#_source.enabled: false
setup.kibana:
output:
kafka:
hosts: ["localhost:9092"]
topic: shijiange
filebeat输出到kafaka需要指定kafak的topic,以及kafak服务器的端口和地址
接下来我来看logstash的配置
input {
kafka {
bootstrap_servers => "localhost:9092"
topics => ["shijiange"]
group_id => "kafakaweithlogsh"
codec => "json"
}
}
filter {
json {
source => "message"
remove_field => ["message","@version","path","beat","input","log","offset","prospector","source","tags"]
}
}
output{
elasticsearch {
hosts => ["http://localhost:9200"]
}
stdout {
codec=>rubydebug
}
}
这里有几个参数需要强调
第一就是logsstah可以监控多个topic
bootstrap_servers => "localhost:9092"
topics => ["shijiange"]
group_id 是kafak通信机制中的原理,不清除的看kafak的信息
codec => "json"表示Logstash使用codec处理json数据
filter中数据解析也采用json的形式
filter {
json {
source => "message"
remove_field => ["message","@version","path","beat","input","log","offset","prospector","source","tags"]
}
}
kafak提供了消费者查看的命令
linux环境如下
1. 查看Group: ./kafka-consumer-groups.sh --bootstrap-server 192.168.237.51:9092 --list
2. 查看队列:./kafka-consumer-groups.sh --bootstrap-server 192.168.237.51:9092 --group shijiange --describe
windows环境如下

这个就是我们logstash中定义的groupid
我们现在要查询队列中的消息情况

这里client-id为0表示队列中没有多余的数据
doc文档
Filebeat日志发送到Kafka
filebeat.inputs:
- type: log
tail_files: true
backoff: "1s"
paths:
- /usr/local/nginx/logs/access.json.log
fields:
type: access
fields_under_root: true
output:
kafka:
hosts: ["192.168.237.51:9092"]
topic: shijiange
Logstash读取Kafka
input {
kafka {
bootstrap_servers => "192.168.237.51:9092"
topics => ["shijiange"]
group_id => "shijiange"
codec => "json"
}
}
filter {
if [type] == "access" {
json {
source => "message"
remove_field => ["message","@version","path","beat","input","log","offset","prospector","source","tags"]
}
}
}
output {
stdout {
codec=>rubydebug
}
}
Kafka查看队列信息
1. 查看Group: ./kafka-consumer-groups.sh --bootstrap-server 192.168.237.51:9092 --list
2. 查看队列:./kafka-consumer-groups.sh --bootstrap-server 192.168.237.51:9092 --group shijiange --describe
注意事项:
1.引入kafak之后,会将数据存储到文件中,当重启了kafak和logstash之后,kafak会将重启之前的数据重发发送给logstash
当重启kafak之后,我们可以使用下面的命令查看kafak中的数据
、
100530就是kafak重启之前保存的数据,会将这些数据发送给logstash
kibana使用饼图
y轴设置如下所示
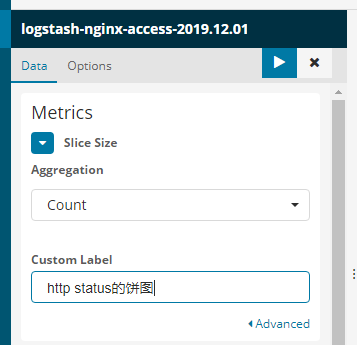
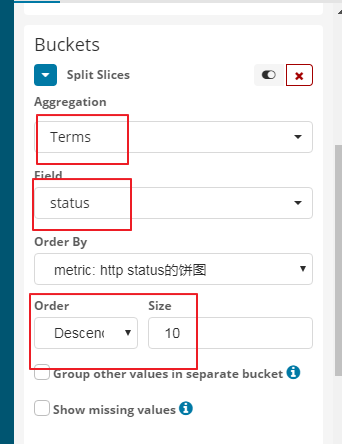
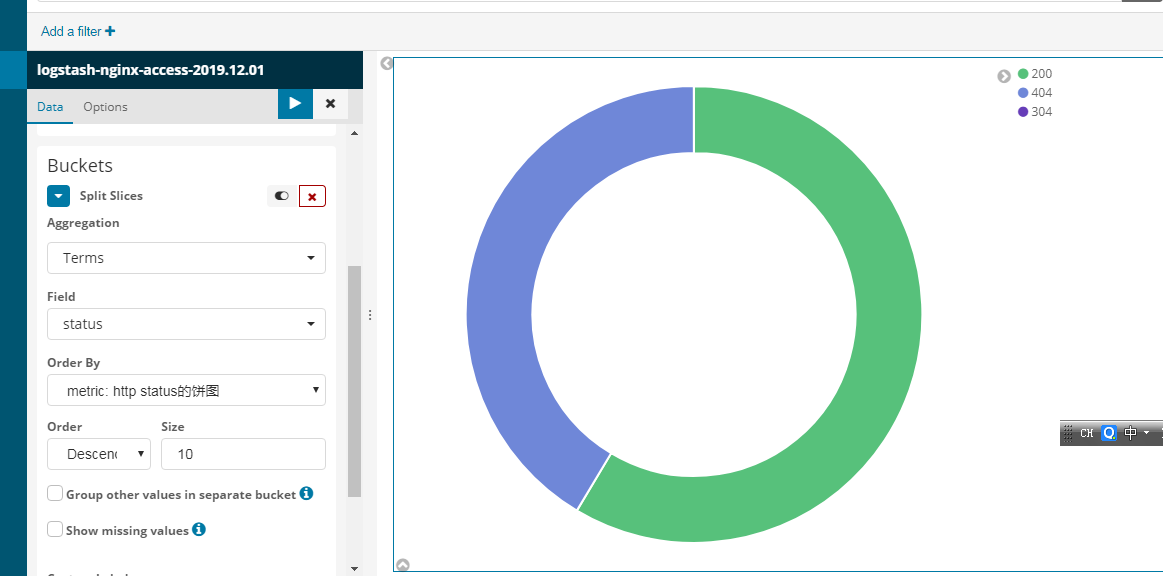
整个效果如下所示
右上角可以选择要查看的时间和刷新的频率
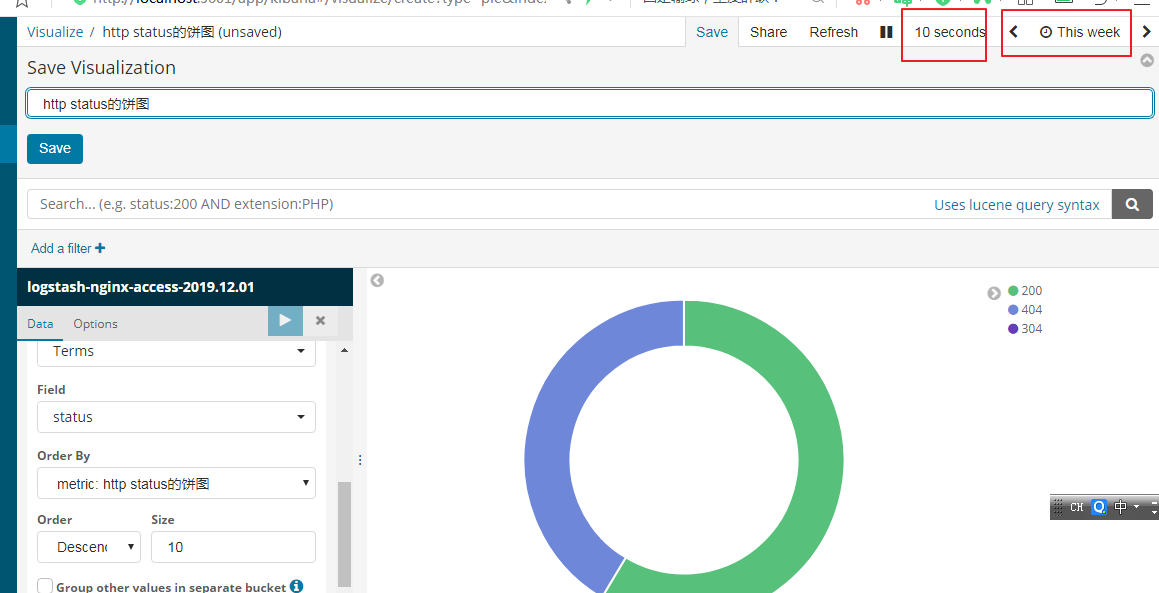
勾选上show label可以看到具体的提示

posted on 2019-11-24 16:41 luzhouxiaoshuai 阅读(678) 评论(0) 编辑 收藏 举报


