【杂学】知识蒸馏原理解读
参考:https://zhuanlan.zhihu.com/p/102038521 ;https://intellabs.github.io/distiller/knowledge_distillation.html
论文:https://arxiv.org/pdf/1503.02531
背景
首先我们先了解一下蒸馏的定义:蒸馏(distillation)是一种热力学的分离工艺,它利用混合液体或液-固体系中各组分沸点不同,使低沸点组分蒸发,再冷凝以分离整个组分的单元操作过程,是蒸发和冷凝两种单元操作的联合。[1]
从其定义我们可以得知,蒸馏的核心是“分离”;在神经网络中,“知识”可以抽象为模型蕴含的参数信息,因此知识蒸馏就是将模型的部分参数(知识)分离出来提供给其他的模型。这一技术的理论来自于 2015 年 Hinton 等人发表的一篇论文:Distilling the Knowledge in a Neural Network。
理论基础
Teacher 和 Student
一般认为,大模型往往比小模型能学习更多、更复杂的知识。但在落地应用时,大模型存在着部署困难、推理效率低、资源耗费多等问题,因此 Hinton 等人想出将“训练”和“部署”解耦:训练时使用参数量多的“Teacher”(大模型),部署时使用速度快的“Student”模型(小模型),即 Teacher -- Student 结构。
- Teacher 是“知识”的输出者,记为 \(Net_T\),不受模型参数、架构限制,但需要被充分预训练,任务与 Student 匹配;
- Student 是“知识”的接受者,记为 \(Net_S\),需要采用架构相对简单、参数量较小的模型。
Soft Target
在知识蒸馏时,我们做的就是让 \(Net_S\) 学习泛化能力比较强的 \(Net_T\)。一个很直白且高效的迁移泛化能力的方法就是:使用 soft target。
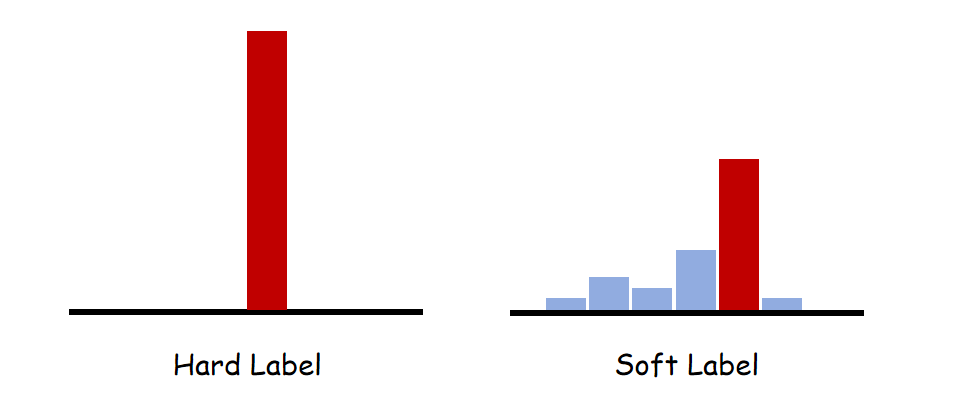
可以知道 soft target 分布的熵更高,含有的信息也就越多。
Softmax
传统的 softmax 函数如下:
但是如果当 softmax 之后的分布熵相对较小时,负标签的值都很接近 0,对损失函数的贡献非常小,小到可以忽略不计,此时温度 \(T\) 就派上了用场。
下面的公式时加了温度这个变量之后的 softmax 函数:
\(T\) 越高,softmax 的输出分布越趋于平滑,其分布的熵越大,负标签携带的信息会被相对地放大,模型训练将更加关注负标签。
方法
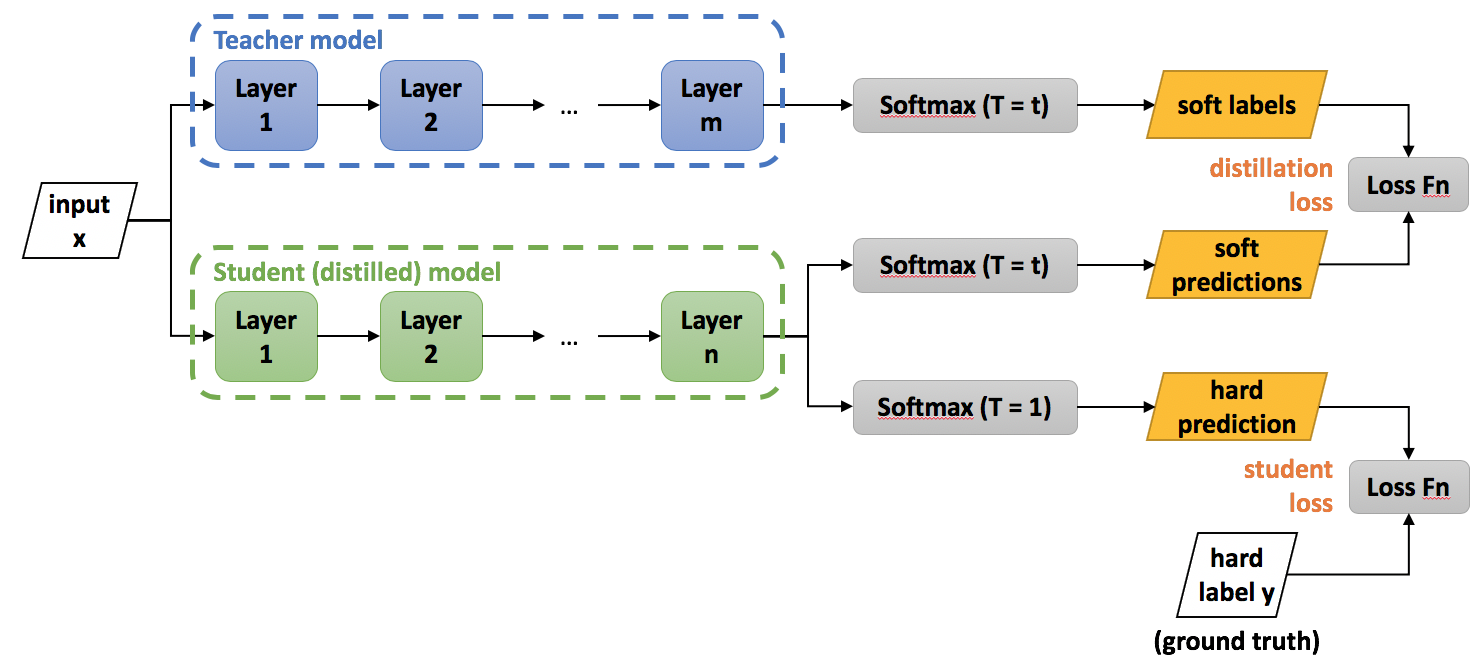
图片来源:https://intellabs.github.io/distiller/knowledge_distillation.html
知识蒸馏需要用到一个预训练的教师模型以及一个结构简单的学生模型,最终的损失需要用到老师对学生的指导 \(L_{soft}\)(distillation loss)以及学生参考标准答案的误差 \(L_{hard}\)(student loss)。即:
其中,\(p_i^T=\frac{\exp(v_i/T)}{\sum_k^N\exp(v_k/T)}\),\(q_i^T=\frac{\exp(z_i/T)}{\sum_k^N\exp(z_k/T)}\);\(c_j\) 为真实标签,\(v_i\) 为 \(Net_T\) 的 logits,\(z_i\) 为 \(Net_S\) 的 logits。
这个训练过程比较通俗易懂的解释就是:老师的各方面知识水平远在学生以上,他会挑选重点进行讲授(由温度控制);但是他仍然有出错的可能,而这时候如果学生在老师的教授之外,可以同时参考到标准答案,就可以有效地降低被老师偶尔的错误“带偏”的可能性。
对于温度的选择,一般可以考虑:
- 从有部分信息量的负标签中学习 --> 温度要高一些
- 防止受负标签中噪声的影响 --> 温度要低一些
- \(Net_S\) 参数量比较小的时候,相对比较低的温度就可以了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号