
【杂学】先进的 NLP 技术 —— 旋转位置编码(Rotary Position Embedding,RoPE)
Transformer 已经渐渐成为目前 LLM 最通用底层架构之一,其中的位置编码也显得极其重要,由于注意力分数本质上是每个 token 的 val 加权和,并没有考虑其中的空间信息,因此需要在自注意力模块之前就将位置信息融合进序列中。
绝对位置编码
绝对位置编码是一种将序列中的每个位置进行编码的方法,它为每个位置分配一个唯一的编码向量。其优势在于它不依赖于序列中的其他元素,可以独立地表示每个位置的信息,比较简单容易计算。
Transformer 所用的就是绝对位置编码策略,计算公式如下:
其缺点也比较明显:
- 绝对位置编码无法反应不同词之间的相对关系,例如位置 1 和 2 跟 5 和 500 的差异是一样的
- 表示不了比预训练文本长度更长的位置向量表示,如果预训练最大长度为 512 的话,那么最多就只能处理长度为 512 的句子,再长就处理不了了
相对位置编码
相对位置编码不是关注词在句子中的绝对位置,而是关注词和词之间的距离。该方法不会直接向词向量添加位置向量。而是改变了注意力机制以纳入相对位置信息。
比较经典的是 T5 模型中所用的相对位置编码。具体来说,T5 并没有像 Transformer 一样使用 PE,而是在第一个 encoder 的
而其中的
相对位置编码的缺点有:
- 增添了计算量,需要额外维护
- 无法适用于 KV-cache 技术。使用 KV-cache 的一项要求是已经生成的单词的位置编码,在生成新单词时不改变,而相对位置编码会变化
旋转位置编码
如上所述,相对或绝对位置编码均有其局限性。旋转位置编码(RoPE)是一种全新的方法,巧妙地融合了传统方法的优点。
二维
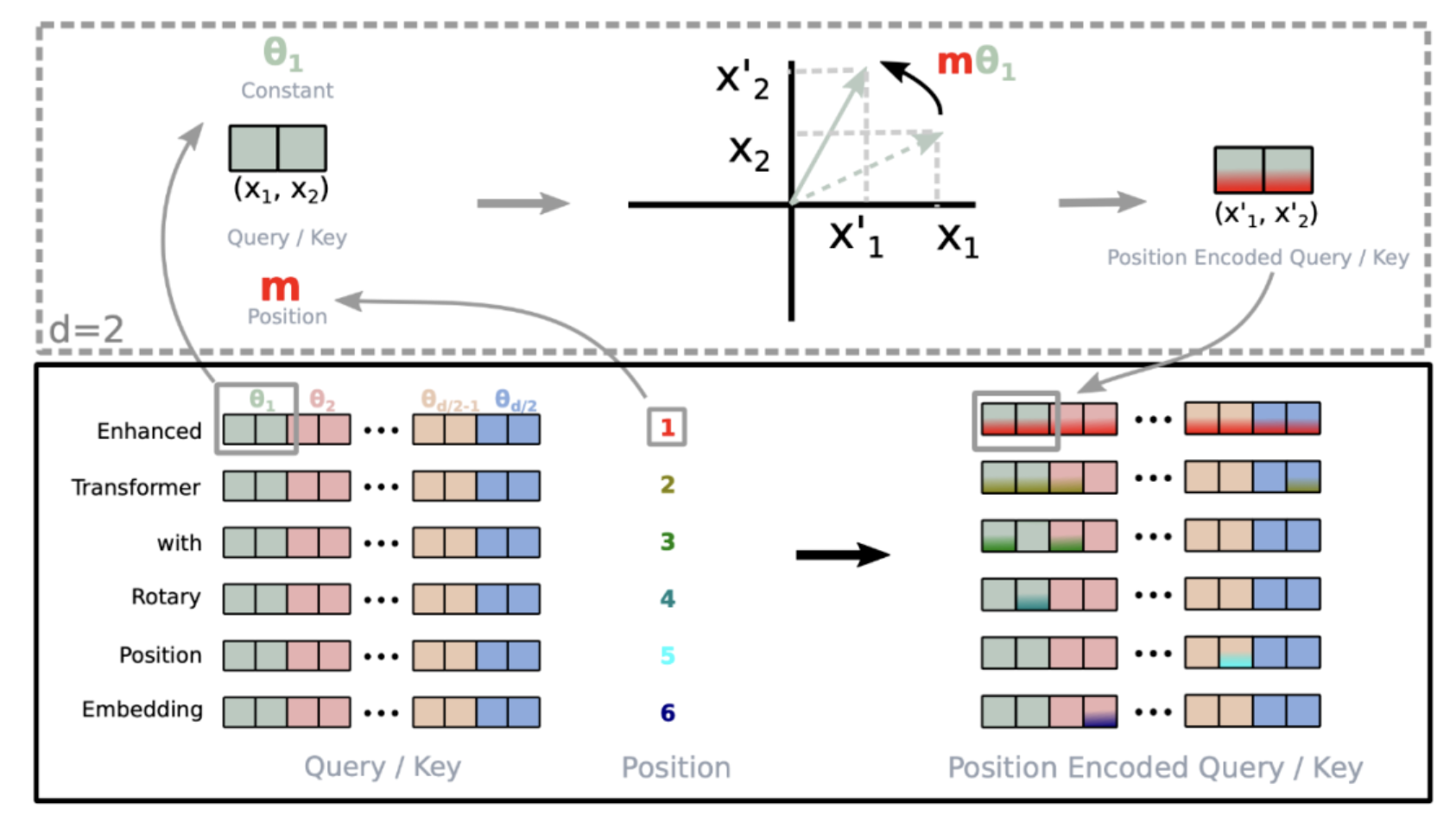
二维的旋转位置编码可以理解为在二维平面上将不同的 token 进行不同角度的旋转。计算公式可以推导为如下形式:
其中
扩展到多维
由于内积满足线性叠加性,因此对于偶数维度的 RoPE,我们可以基于二维进行叠加扩展:
总结
RoPE 不仅解决了输入文本过长之后引起的上下文无法关联问题,并且还提高了训练和推理的速度。总的来说,RoPE 的 self-attention 操作的流程是:
- 对于 token 序列中的每个词嵌入向量,首先计算其对应的 query 和 key 向量
- 对每个 token 位置都计算对应的旋转位置编码
- 接着对每个 token 位置的 query 和 key 向量的元素按照两两一组应用旋转变换
- 最后再计算 query 和 key 之间的内积得到 self-attention 的计算结果。
本文作者:KeanShi
本文链接:https://www.cnblogs.com/keanshi/p/18540794
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律