【杂学】大模型推理加速 —— KV-cache 技术
如果不熟悉 Transformer 的同学可以点击这里了解
自从《Attention Is All You Need》问世以来,Transformer 已经成为了 LLM 中最基础的架构,被广泛使用。KV-cache 是大模型推理加速的关键技术之一,已经成为了 Transformer 标配的功能,不过其只能用于 Decoder 结构:由于 Decoder 中有 Mask 机制,推理的时候前面的词不需要与后面的词计算 attention score,因此 KV 矩阵可以被缓存起来用于多次计算。
例如,我们要生成 "I love Tianjin University" 这句话。首先是只有开头标记 <s>,计算过程如下图所示(为了便于理解,我们将 softmax 和 scale 去掉):
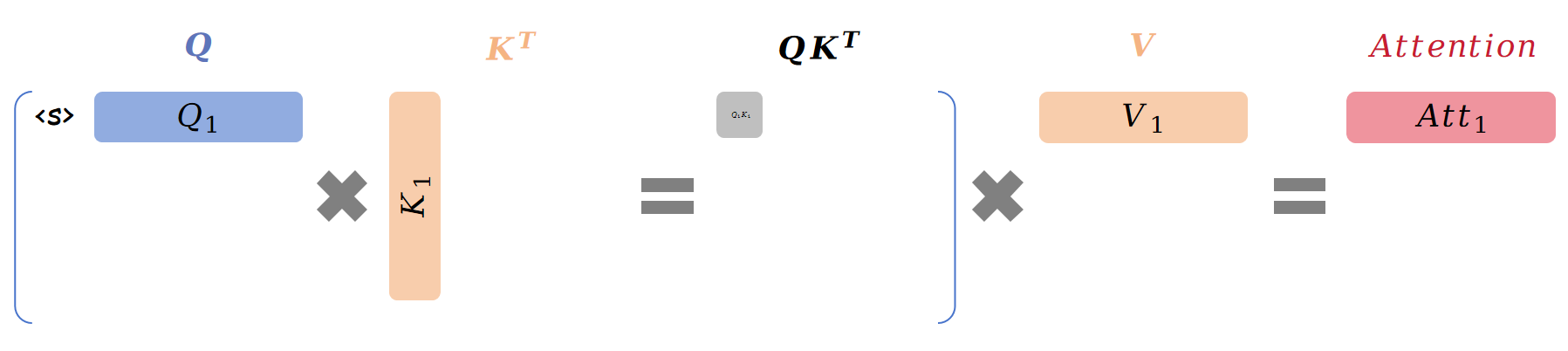
最终第一步的注意力 \(\text{Att}_{step1}\) 计算公式为:
\[{\color{red}\text{Att}_1}(Q,K,V)=({\color{red}{Q_1}}K_1^T)\overrightarrow{V_1}
\]
此时序列中的词为 "<s> I",由于有 Mask 机制,第二步计算如下图所示:
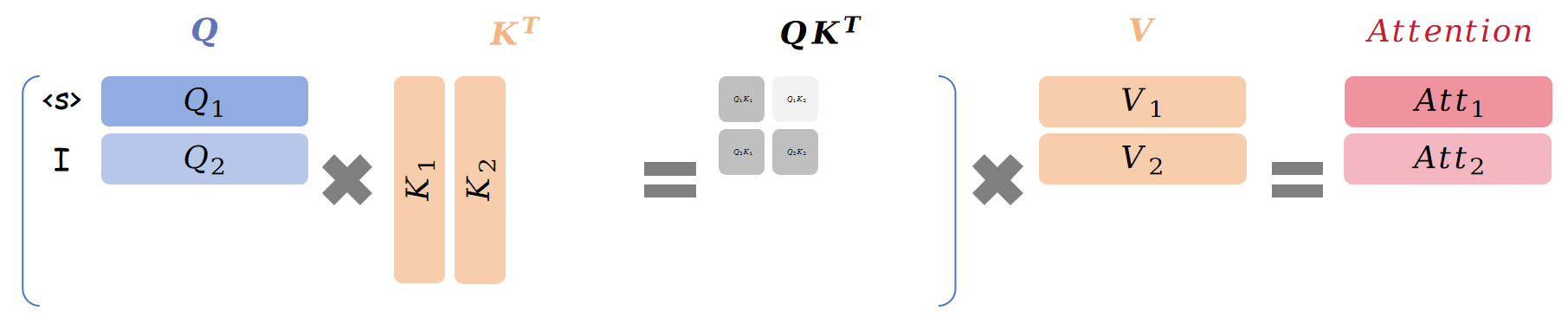
第二步的注意力为:
\[\begin{aligned}
\text{Att}_{step2}&=\begin{bmatrix}{\color{red}{Q_1}}K_{1}^{T}&0\\{\color{green}{Q_2}}K_{1}^{T}&{\color{green}{Q_2}}K_{2}^{T}\end{bmatrix}\begin{bmatrix}\overrightarrow{V_{1}}\\\overrightarrow{V_{2}}\end{bmatrix}
=\begin{bmatrix}{\color{red}{Q_1}}K_1^T\times\overrightarrow{V1}\\{\color{green}{Q_2}}K_1^T\times\overrightarrow{V1}+{\color{green}{Q_2}}K_2^T\times\overrightarrow{V2}\end{bmatrix}
\end{aligned}\]
设 \(\text{Att}_1\) 是第一行,\(\text{Att}_2\) 是第二行,则有:
\[\begin{aligned}&{\color{red}\text{Att}_1}(Q,K,V)={\color{red}{Q_1}}K_1^T\overrightarrow{V_1}\\&{\color{green}\text{Att}_2}(Q,K,V)={\color{green}{Q_2}}K_1^T\overrightarrow{V_1}+{\color{green}{Q_2}}K_2^T\overrightarrow{V_2}\end{aligned}
\]
此时我们可以大胆猜想:
- \(\text{Att}_k\) 只与 \(Q_k\) 有关
- 已经计算出的 \(\text{Att}\) 永远都不会改变
带着这个猜想,继续生成下面的词,容易计算第三步可以得到:
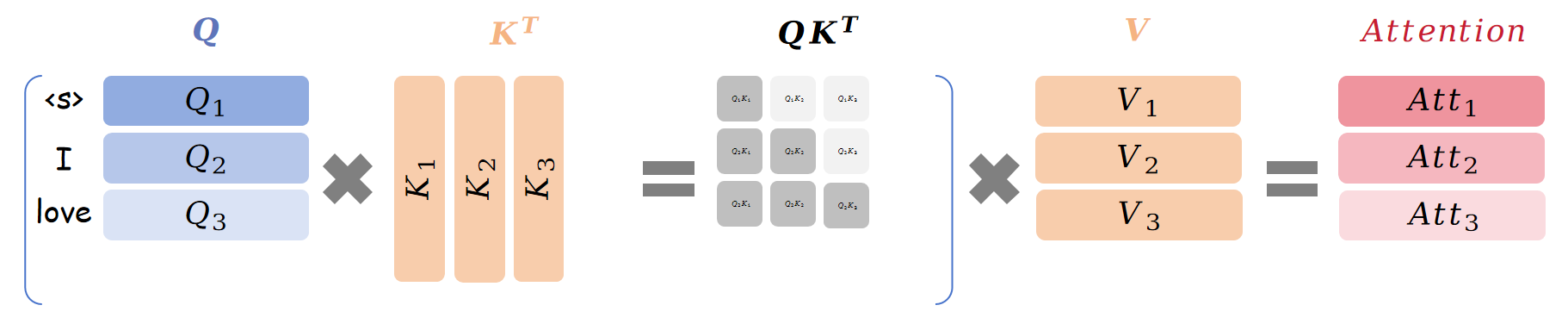
\[\begin{aligned}&{\color{red}\text{Att}_1}(Q,K,V)={\color{red}{Q_1}}K_1^T\overrightarrow{V_1}\\&{\color{green}\text{Att}_2}(Q,K,V)={\color{green}{Q_2}}K_1^T\overrightarrow{V_1}+{\color{green}{Q_2}}K_2^T\overrightarrow{V_2}\\&{\color{blue}\text{Att}_3}(Q,K,V)={\color{blue}{Q_3}}K_1^T\overrightarrow{V_1}+{\color{blue}{Q_3}}K_2^T\overrightarrow{V_2}+{\color{blue}{Q_3}}K_3^T\overrightarrow{V_3}\end{aligned}
\]
同样的,\(\text{Att}_k\) 只与 \(Q_k\) 有关。第四步也相同。
看上面的图和公式,我们可以归纳出性质:
- 朴素的 Attention 计算存在大量冗余
- \(\text{Att}_k\) 只与 \(Q_k\) 有关,即预测词 \(x_k\) 仅依赖于 \(x_{k-1}\)
- \(K\) 和 \(V\) 全程参与计算,可以缓存起来
- 虽然叫做 KV-cache,但其实真正优化掉的是冗余的 \(Q\) 和 \(\text{Att}\)
当然,这有点类似于动态规划思想,也存在利用空间换取时间的问题,因此当序列很长时,KV-cache 有可能会出现内存爆炸的情况。
下面附上 gpt 的 KV-cache 代码,非常简单,仅仅是做了 concat 操作。不过值得注意的是,attention 的计算并没有使用 cache。
if layer_past is not None:
past_key, past_value = layer_past
key = torch.cat((past_key, key), dim=-2)
value = torch.cat((past_value, value), dim=-2)
if use_cache is True:
present = (key, value)
else:
present = None
if self.reorder_and_upcast_attn:
attn_output, attn_weights = self._upcast_and_reordered_attn(query, key, value, attention_mask, head_mask)
else:
attn_output, attn_weights = self._attn(query, key, value, attention_mask, head_mask)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号