【论文阅读笔记】QwenLM 多模态版本 —— Qwen-VL/Qwen2-VL
论文地址:https://arxiv.org/pdf/2409.12191
代码地址:https://github.com/QwenLM/Qwen2-VL

Qwen
Qwen(通义千问)为大模型家族,其 base model 为 Qwen,目前已经衍生出众多适应下游任务的大模型(图一 [1]),本篇博客重点探讨多模态版本 Qwen-VL 以及 Qwen2-VL。
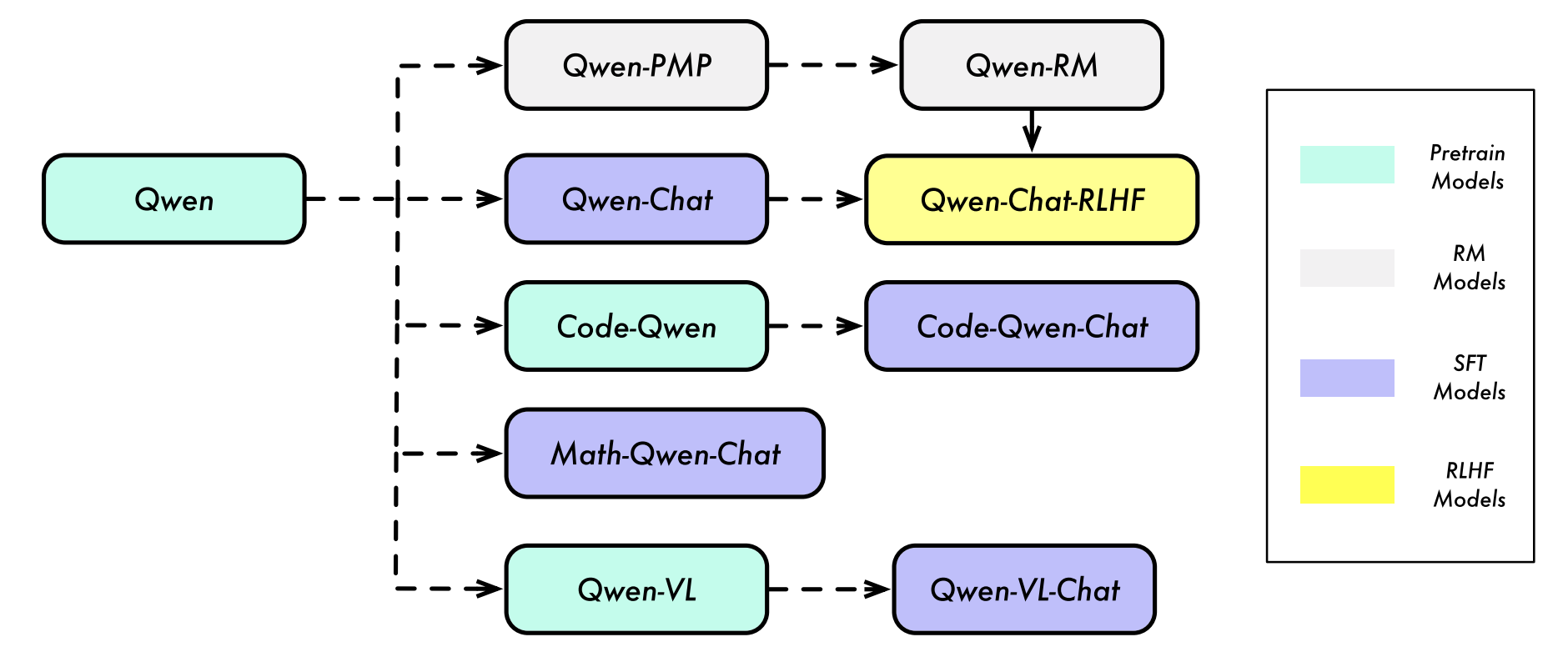
图 1:Qwen 大模型家族
Qwen-VL
Qwen-VL 是基于 Qwen-7B 的一系列高性能、通用的 LVLM(Large Vision-Language Model)。
Features of Qwen-VL: Leading performance, Multi-lingual(most base on Chinese and English), Multi-image, Fine-grained visual understanding.
模型架构
- Foundation Component: initialized with pretrained weights from Qwen-7B
- Visual Encoder: Vision Transformer, initialized with pre-trained weights from ViT-bigG.
- Position-aware Vision-Language Adapter: a single-layer cross-attention module initialized randomly
输入图片首先被裁剪为统一像素,然后被 Encoder 分割成 14*14 的小块。最后通过一个交叉注意力模块(模块提供 \(Q\),Encoder 输出序列提供 \(KV\))压缩成长度 256 ,包含 2D 位置信息的序列。Detail 和 Pipline 如图 2 [2]所示。

图 2:Detail of parameters and training pipline.
Input and Output
- Image Input: 输入图片经过上节的处理后,首尾加上 <img> 和 </img> 两个 token
- Bounding Box Input and Output: 利用一组形如 \((X_{topleft},Y_{topleft}),(X_{bottomright},Y_{bottomright})\) 的字符串(两端加上 <box> 和 </box>)标记出 bounding box;然后利用 <ref> 和 </ref> 将其与其对应描述性的序列对应起来。用来训练出能够应对细粒度问题(如指定区域的描述、问答等)的模型。
训练
如图 2 所示,训练需要经过 2-stage 预训练以及 1-stage 指令微调。
Pre-training
主要利用大规模的、弱标记的、网络抓取的图像-文本对,分辨率为 224*224(图 3)。
冻结 LLM,只训练 vision encoder 和 VL adapter。
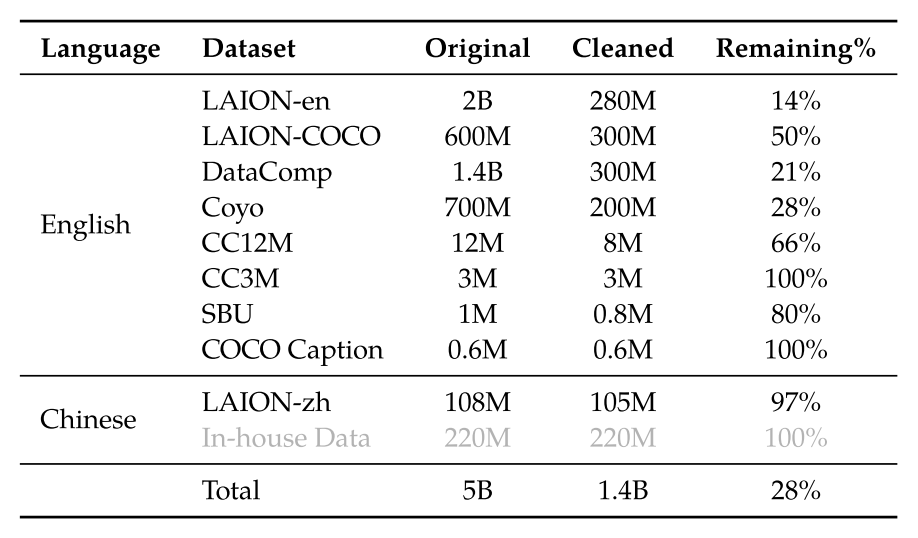
图 3:第一阶段训练数据
Multi-task Pre-training
引入了具有较大分辨率的高质量和细粒度的 VL 标注数据以及交错的图像-文本数据,分辨率为 448*448(图 4)。
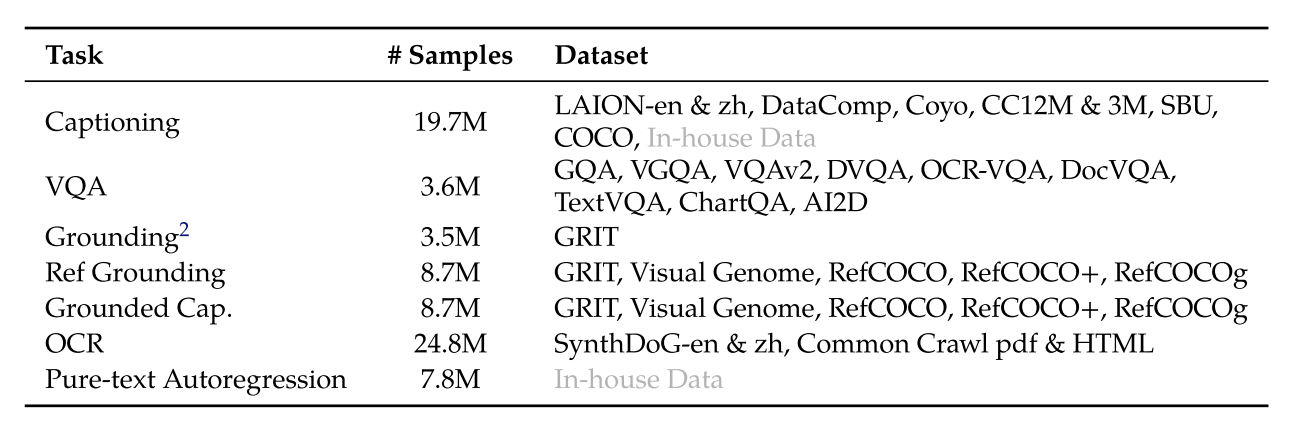
图 4:第二阶段训练数据
Supervised Fine-tuning
利用指令微调强化模型的指令遵循以及对话能力(产生了 Qwen-VL-Chat 模型)。除了大部分 LLM 自己生成的标注以及对话数据外,作者团队人工构建了高质量的对话数据;此外,团队将纯文本对话和多模态混合在一起,以确保模型在对话方面的通用性。
Evalution
表 1:Image Captioning and General VQA
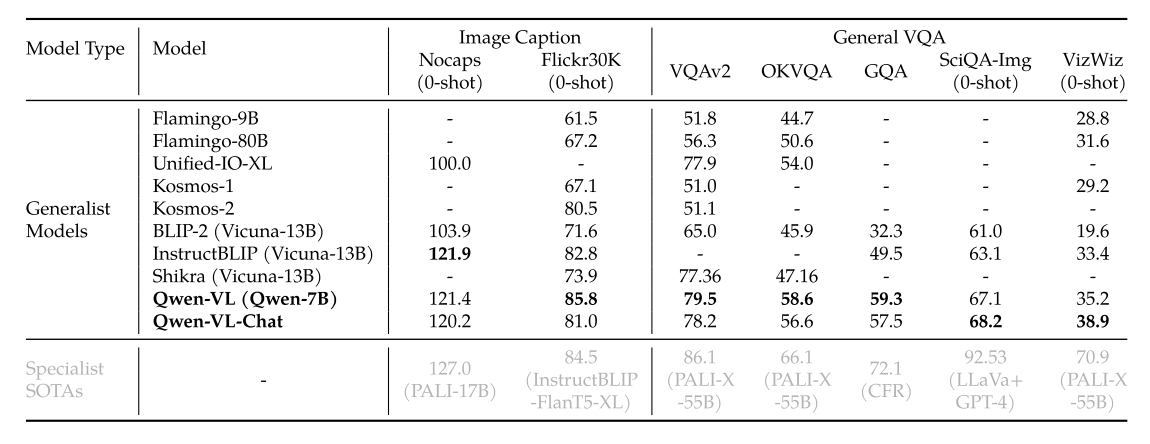
表 2:Text-oriented VQA(与普通的 VQA 相比,模型需要理解图片中的文本信息)
表 3:Referring Expression Comprehension(根据描述标出 bounding box)
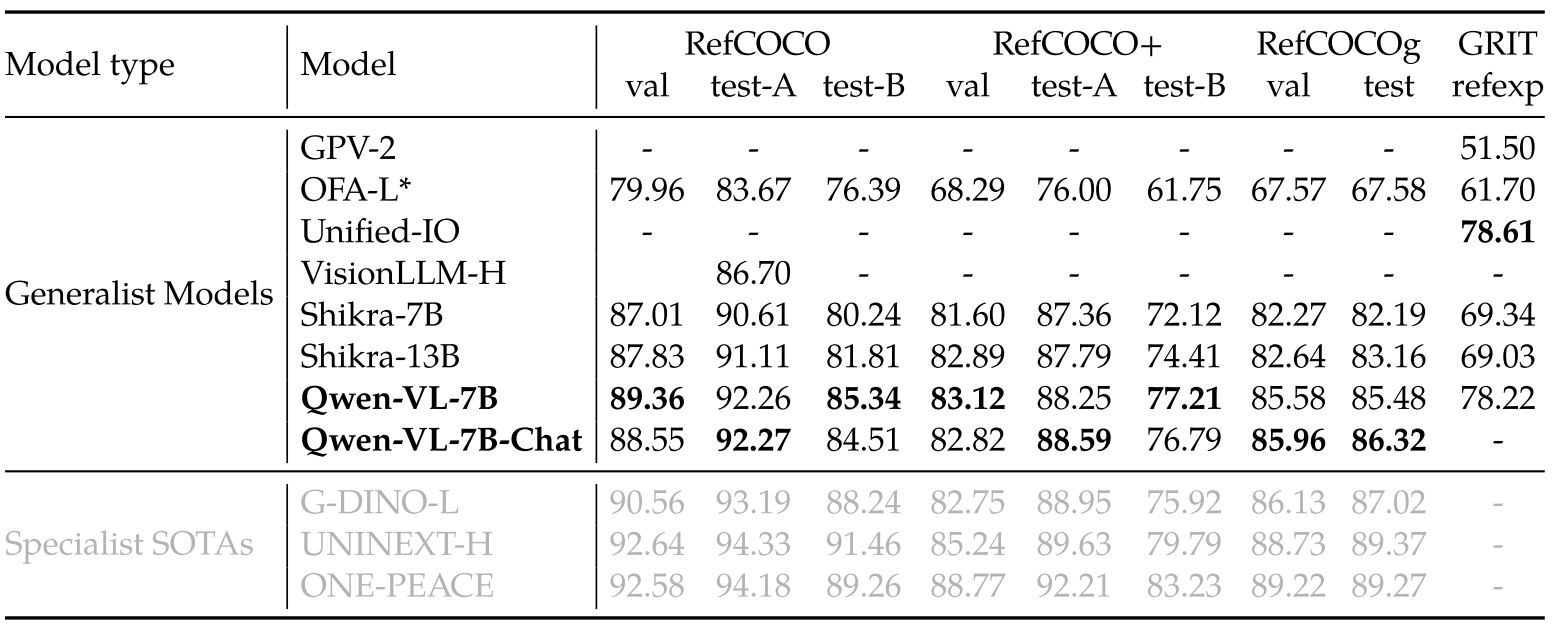
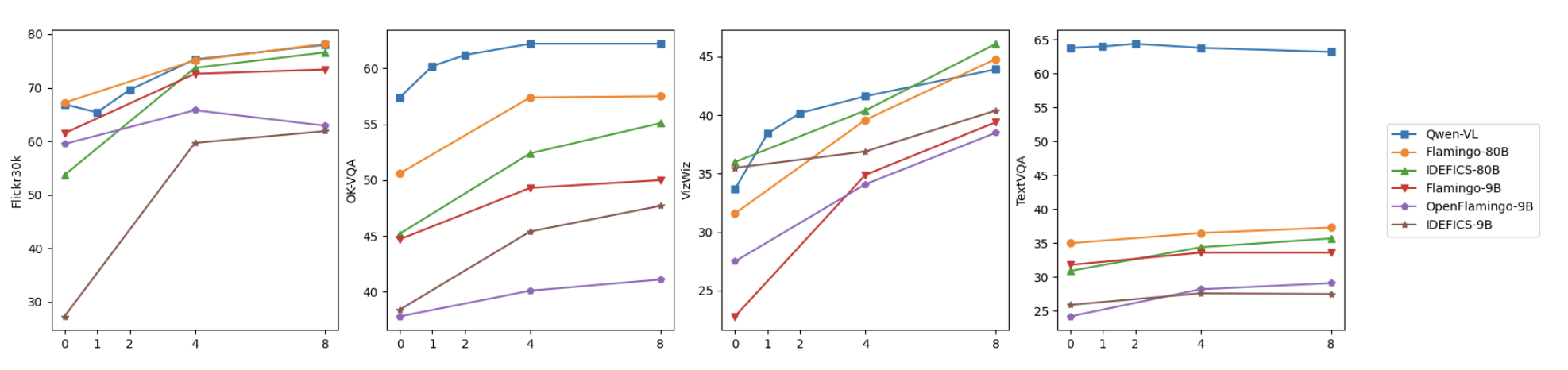
图 5:Few-shot learning results
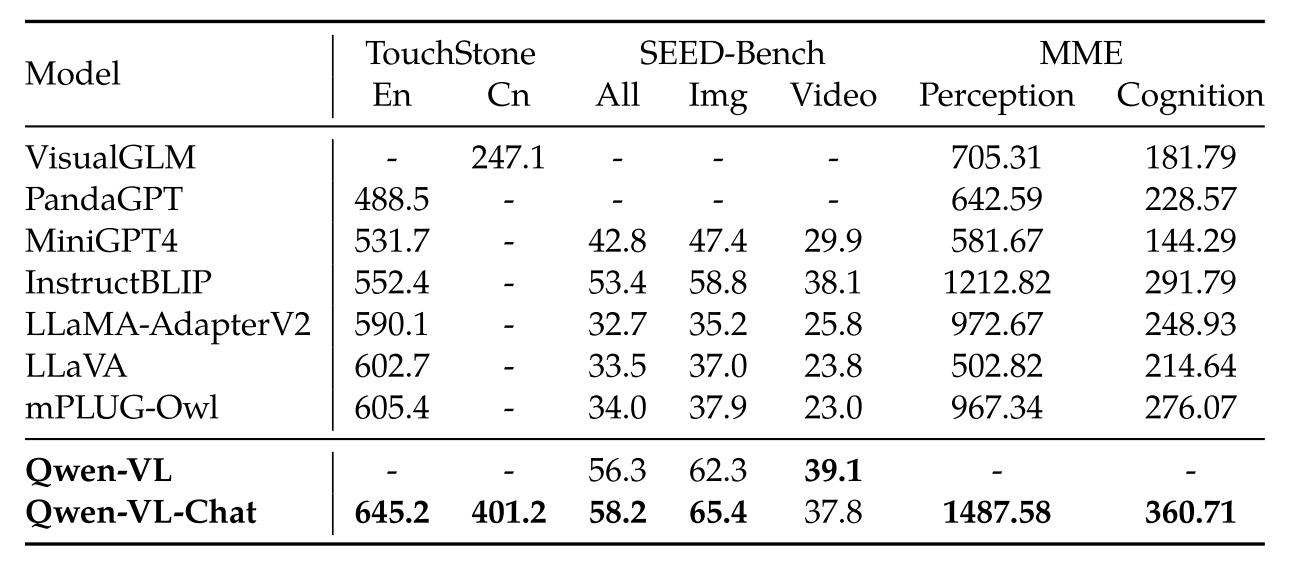
表 4:Instruction-following benchmarks
Qwen2-VL
Qwen2-VL 是对 Qwen-VL 的改进版本。具体来说,当前的 LVLM 仍然存在一些问题:
- 输入受限于必须固定图片的大小 —— Naive Dynamic Resolution 机制
- 大多数 vision-encoder 仍然依赖于固定的 CLIP-style 的结构,或 fine-tuning 的 ViT —— ViT 中加入 2D Rotary Position Embedding (RoPE)
- 真实世界是三维的,一维的 embedding 很难有效捕捉特征 —— Multimodal Rotary Position Embedding (M-RoPE) 来分别表示时间、空间信息
Improvements:
- SOTA across various resolutions and aspect ratios
- Comprehension of extended-duration videos (20 min+)
- Robust agent capabilities for device operation
- Multilingual support
模型架构
Qwen2-VL 保留了 Qwen-VL 的架构:Vision-encoder + LLM
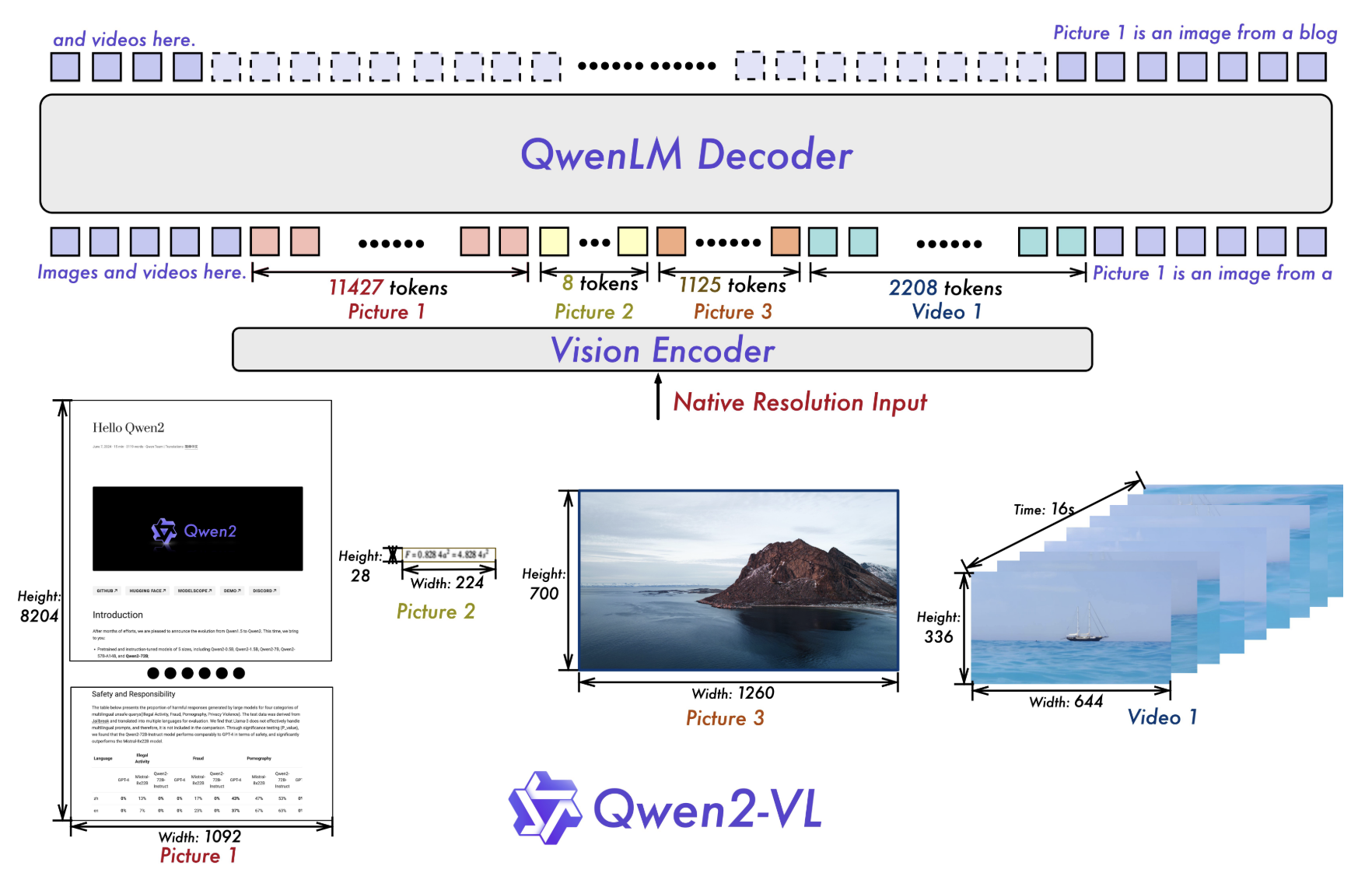
图 6:Qwen2-VL 整体架构
Naive Dynamic Resolution
核心思想:模型能够动态地处理不同分辨率的图片,并将其转化为不等长的序列。
- 在 ViT 中加入了 2D-RoPE[3] 以更好地捕捉二维信息
- 在推理阶段,所有图或视频被打包为一个序列
- 另外,作者还加入了一个 MLP 层将相邻 \(2 \times 2\) 映射为 \(1 \times 1\) 来减轻 GPU 计算负担
- 最后在视觉 token 开始和结束的位置加上 <|vision_start|> 和 <|vision_end|>。
举例来说:一个 224*224 大小的图像最后会变成长度为 66 的序列; \(224 \times 224 \div 14 \div 14 \div 4 + 2 = 66\),其中的 14 代表 14 patches 分割。
Multimodal Rotary Position Embedding (M-RoPE)
关于 RoPE 可以点击这里学习

图 7:M-RoPE 示意图
这部分为 Qwen2-VL 的一个重点创新,目的是为了更有效地处理多模态输入(文本、图像和视频)中的位置信息。M-RoPE 基本原理是将传统的 RoPE 分解为时间、宽度和高度 \((t, h, w)\),同时捕捉不同模态的时空信息。
- 文本输入:三部分为相同的数字,与普通 RoPE 相同
- 图像输入:\(t\) 固定,\(h\) 和 \(w\) 根据 token 位置定义
- 视频输入:视频被视为帧序列,每一帧的 \(t\) 递增,\(h\) 和 \(w\) 与图像输入相同
- 当模型输入包含多种模态时,每种模态的位置编号从前一个模态的最大位置 ID 加一开始。
图像与视频处理
为了使模型拥有强大的处理图像-视频混合输入的能力,作者团队首先将视频进行 2 帧/秒的采样,然后使用了两层的卷积来进行 3D 的立体捕捉;另外为了保持一致,图片会被复制为两份进行卷积。为了控制高效性,模型会对视频的帧进行动态裁剪采样,每个视频的 token 数量会被限制在 16384 之内。
训练细节
延续 Qwen-VL,Qwen2-VL 也采用了 3-stage 的训练过程:ViT训练 \(\rightarrow\) 全参数训练 \(\rightarrow\) LLM 指令微调。
多样性的数据包括:图像文本对、OCR 数据、图像文本的文章、VQA 数据、视频对话以及图像知识。来源于网站、开源数据集以及人造数据。
实验结果
作者做了大量的实验,包括视觉问答、对话阅读、多语言文本识别、数学推理、视觉定位理解、视频理解、可视化 agent(包括 UI 操作、机械控制、卡牌游戏、视觉-语言导航)等。Qwen2-VL 在不同的任务中均能取得 SOTA 或 接近 SOTA 的效果。
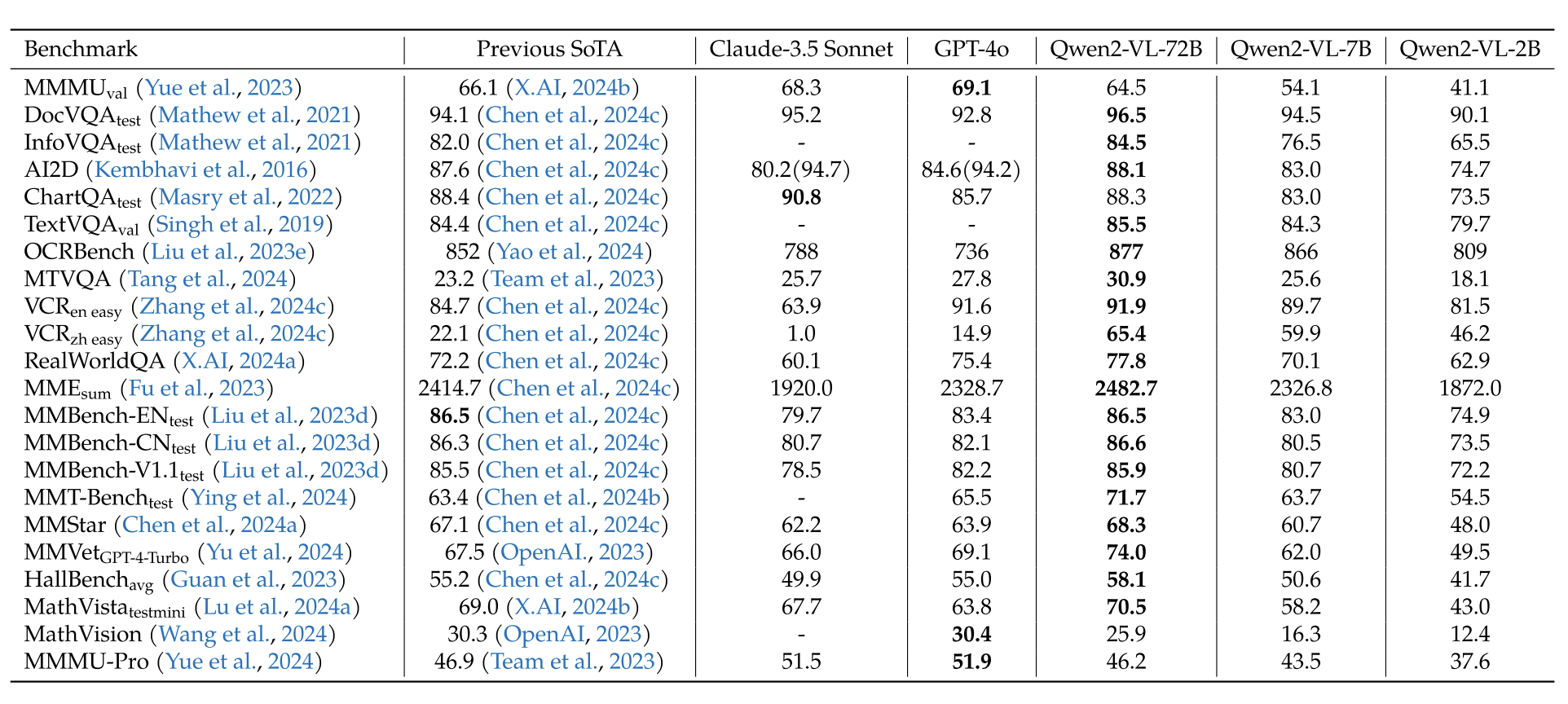
图 8:与 SOTA 进行对比

图 9:OCR 任务的比较

图 10:视频 benchmark 的比较
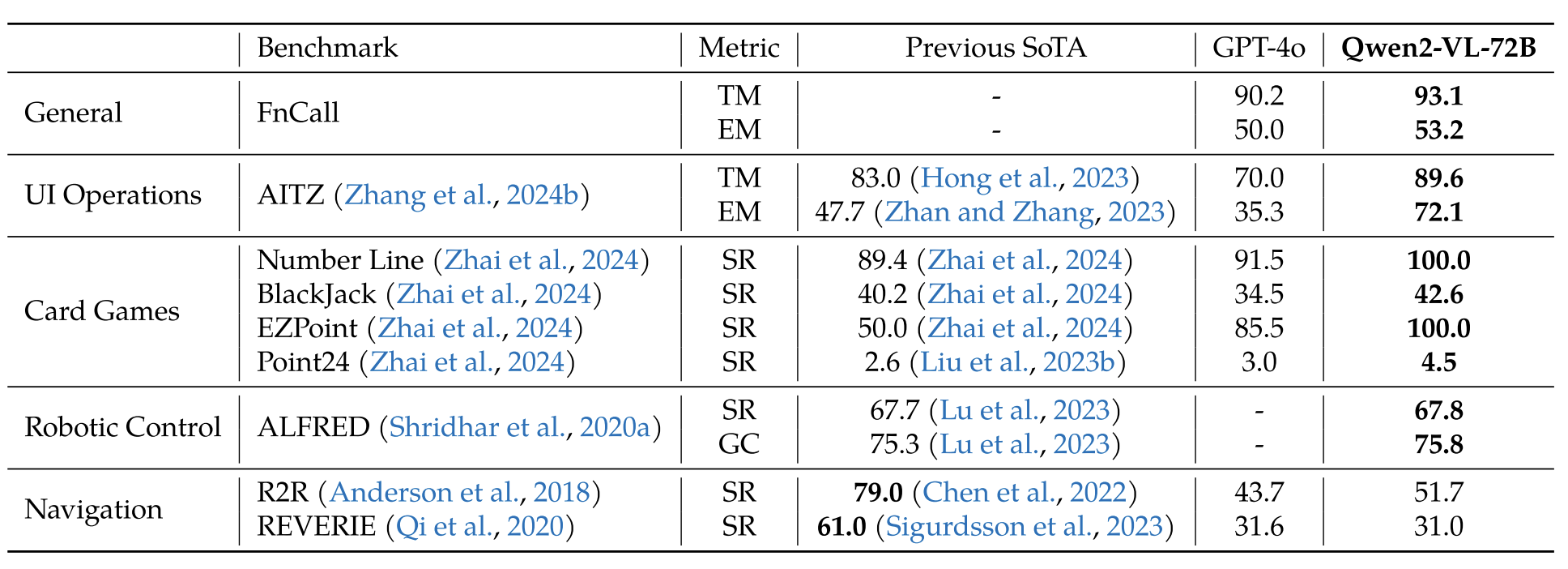
图 11:Agent 表现
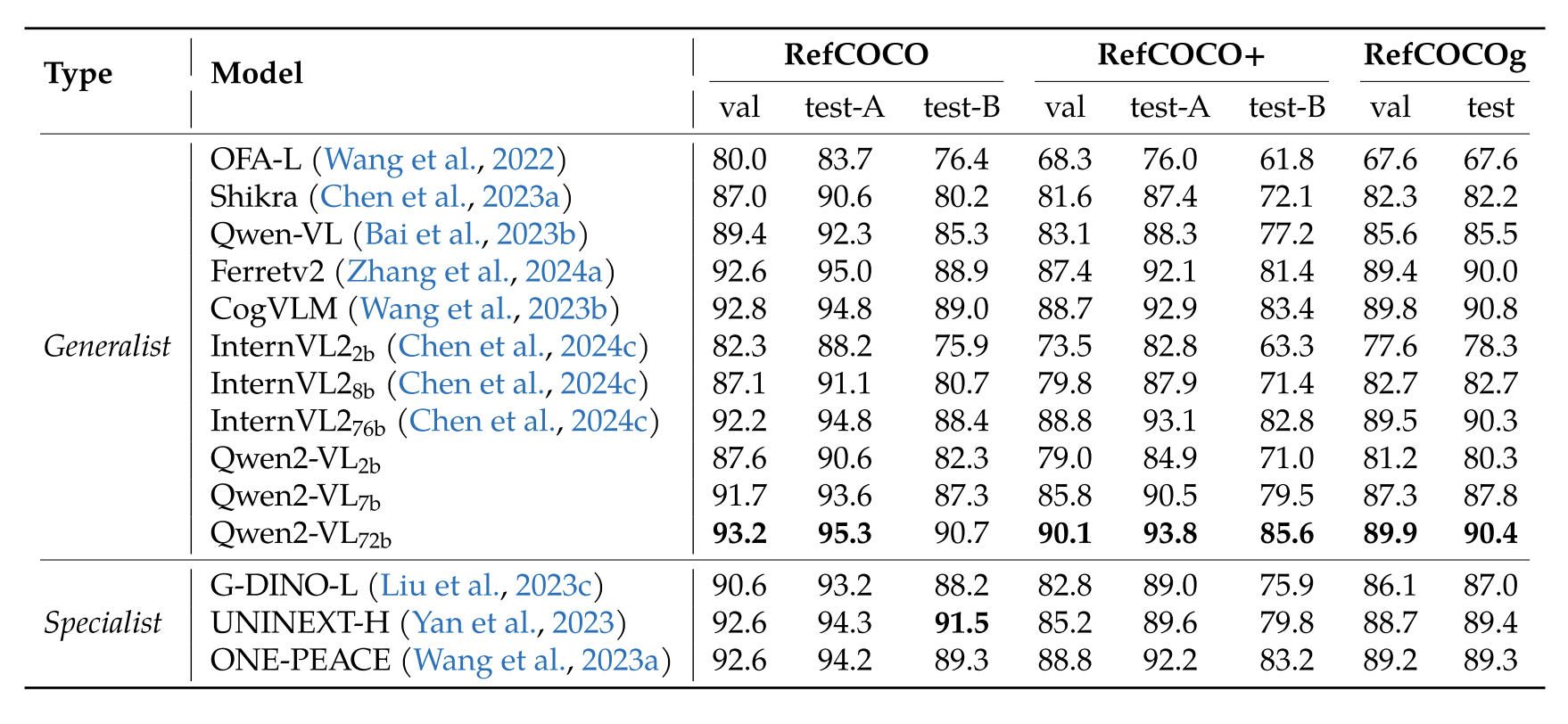
图 12:视觉定位理解任务
消融实验
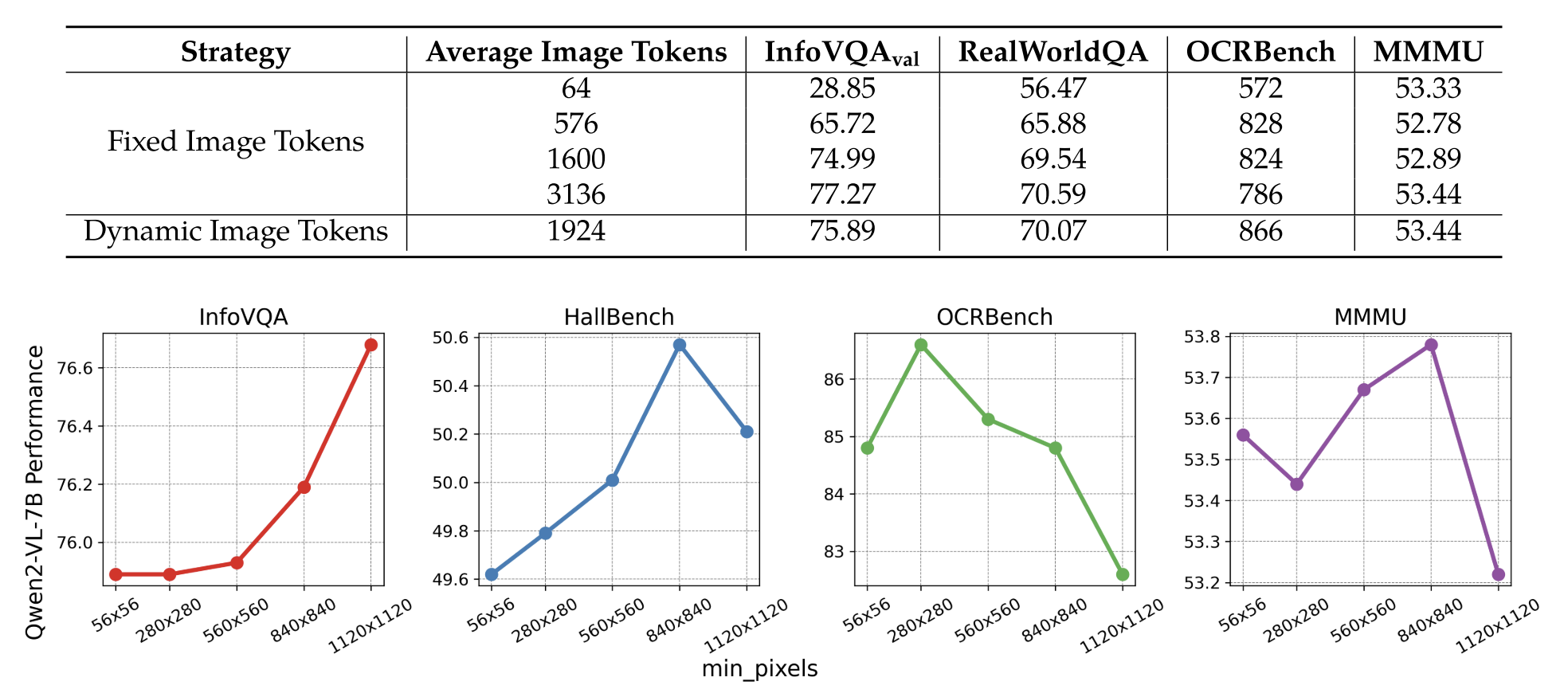
图 13:w/o 动态分辨率处理,以及动态分辨率最小的像素阈值比较
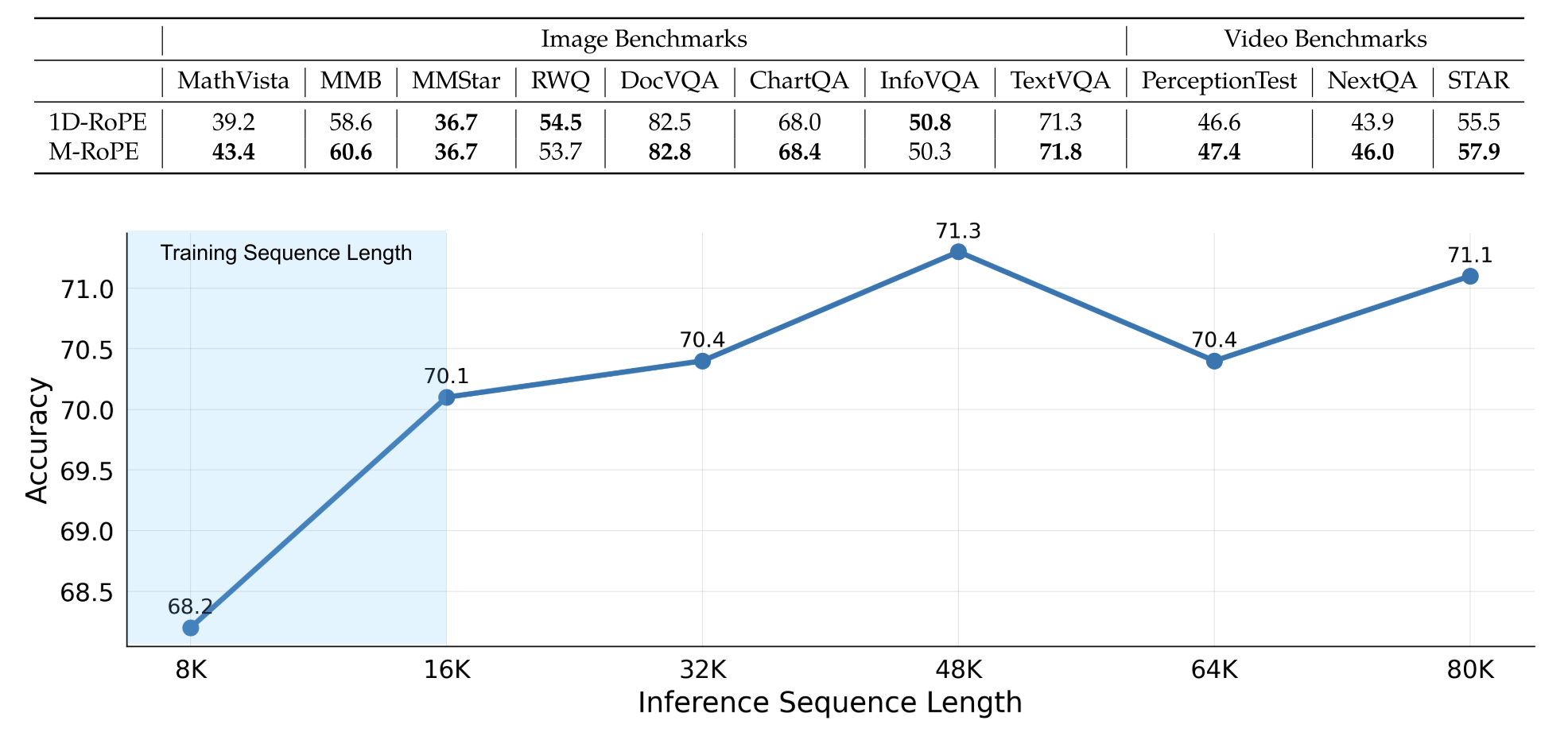
图 14:w/o M-RoPE,以及推理序列长度(为什么超过 16k 还能更好?)
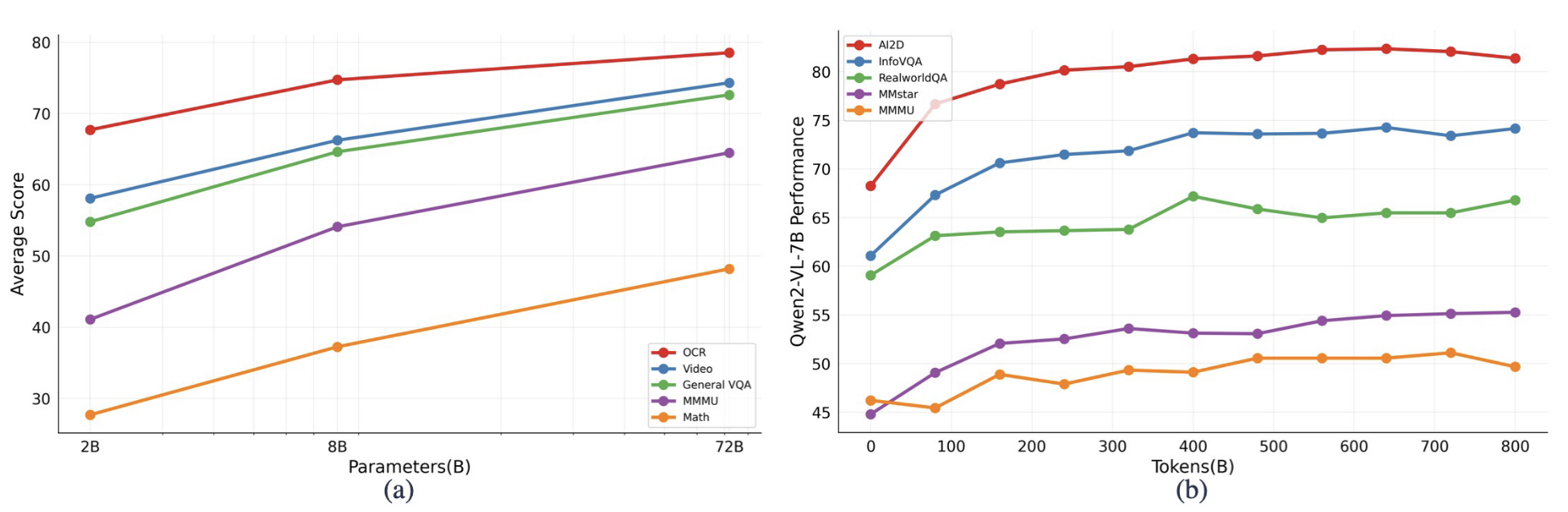
图 15:模型规模
总结
Qwen 作为最具有国际竞争力的国产大模型之一,已经取得了令人瞩目的效果。此次 Qwen2-VL 的问世再次打破了国人对于国产 LVLM 的认知,其性能已经可以和 GPT-4o 媲美,甚至超过它。更值得一提的是 Qwen 完全开源,因此更多的 researcher 可以加入进来,共同为 Qwen 的进步努力。我们共同期待 Alibaba 的 Qwen team 研究出更好的产品!
Bai, Jinze, et al. "Qwen technical report." arXiv preprint arXiv:2309.16609 (2023). ↩︎
Bai, Jinze, et al. "Qwen-vl: A frontier large vision-language model with versatile abilities." arXiv preprint arXiv:2308.12966 (2023). ↩︎
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding. In Neurocomputing, 2024. 4 ↩︎

 浙公网安备 33010602011771号
浙公网安备 33010602011771号