【论文阅读笔记】大模型推理加速 —— FastV
论文地址:https://arxiv.org/pdf/2403.06764
代码地址:https://github.com/pkunlp-icler/FastV

Introduction
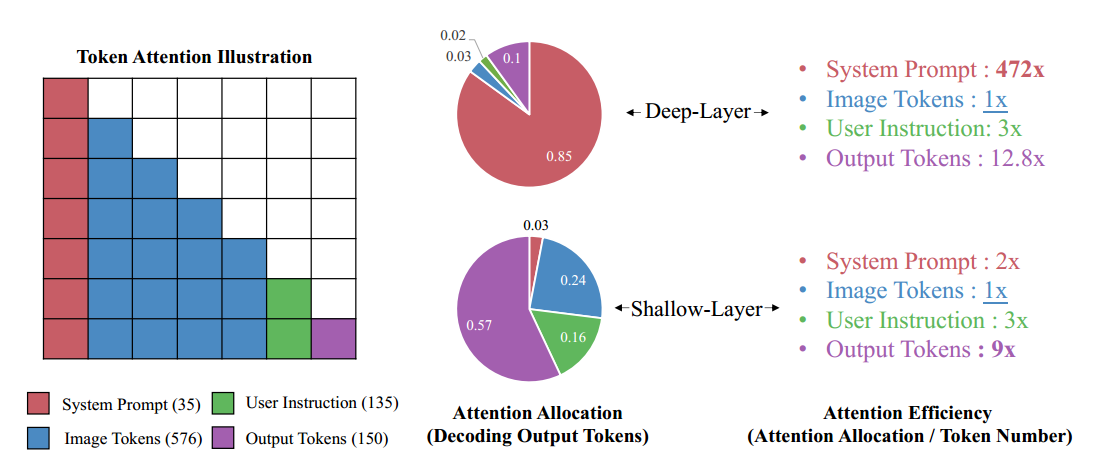
- 现象(问题):大多数 LVLM 在深层的 attention 分数很低;
- 推测:视觉信号的冗余导致在千层会被聚合为 "anchor" token,在深层中,网络更关注这些 "anchor";
- FastV:应用于某一层中,前面的 layer 正常计算,后面的根据 threshold 随机丢弃;

Inefficient Visual Attention in VLLMs
Preliminaries
给定 image-question pair \((d, t)\),利用 decoder 自回归生成过程:
\[p(\hat{y})=\prod_{i=1}^Np_M\left(\hat{y}_i\mid\hat{y}_{1\sim i-1};d;t\right)
\]
两种分数
另 \(\alpha^{i,j}_{sys},\alpha^{i,j}_{img},\alpha^{i,j}_{ins},\alpha^{i,j}_{out}\) 代表第 \(j\) 层,第 \(i\) 个 token 的注意力分数。则有下面两种分数:
\[\text{total attention of system prompt in layer}\ j :\ \lambda_{sys}^{j}=\sum_{i=1}^{n}\alpha_{sys}^{i,j}
\]
\[\text{attention efficiency of image tokens in layer}\ j:\ \epsilon_{img}^{j}=\frac{\sum_{i=1}^{n}\alpha_{img}^{i,j}}{|img|}
\]
结果分析
FastV
Overview
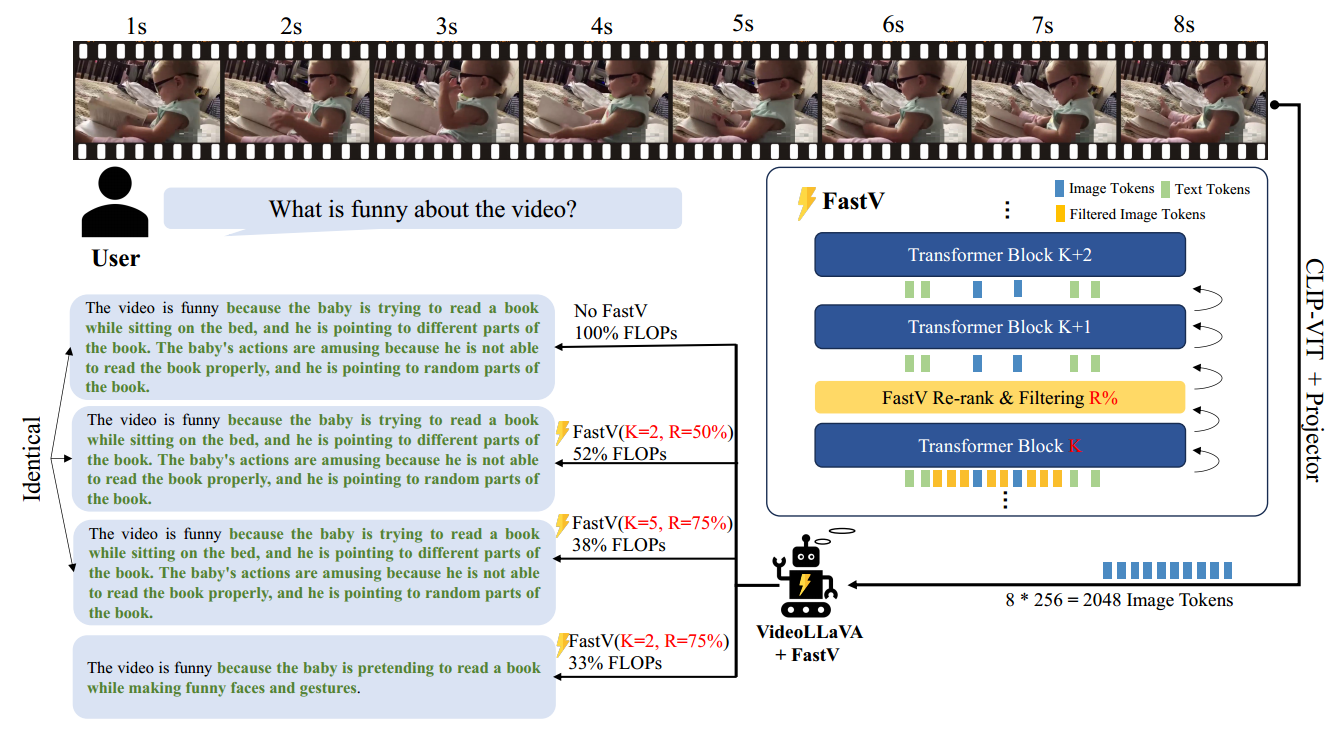
Re-rank and Filtering module (core)
\[ranking \ \ function: f_{\phi}
\]
\[filtering \ \ layer: K
\]
\[filtering \ \ ratio: R
\]
在第 \(K\) 层后,利用 \(f_{\phi}\) 对 token 的注意力分数进行排序(利用该 token 对于其他所有 token 的平均注意力得分),后 \(R\%\) 会被丢弃。
Thought
Same as LoRA, so straightforward that everyone can make delevopment based on this. It's a good start for MLLM's inference using plug-and-play module.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号