数据挖掘的一般过程
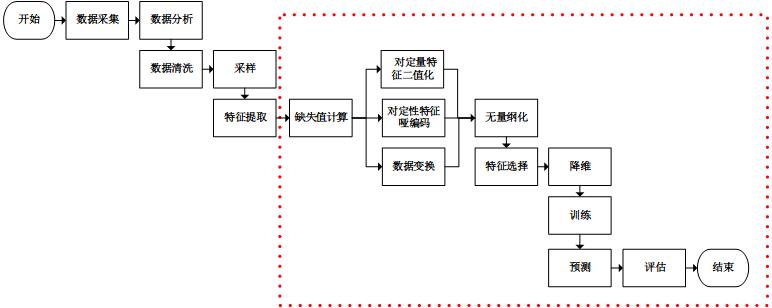
1. 数据集选取或构造
根据任务的目的,选择数据集。或者从实际中构造自己需要的数据。
2. 数据预处理
确定数据集后,就开始对数据进行预处理使得数据能够为我们所用了。数据预处理提高数据质量:准确性、完整性和一致性,包括数据清理、数据集成、数据规约和数据变换方法。 
(1)数据清理
忽略元祖、人工填写缺失值、使用属性的中心度量填充、给定同一类所有样本的属性均值或中位数填充、最可能的值填充
(2)数据集成
实体识别、冗余和相关分析(卡方检验,相关系数,协方差等,用spss比较方便)
(3)数据归约
维规约(小波变换和主成分分析,最常用)、数量规约(较小的数据替代原始数据)、数据压缩(有损无损两种,尤其对于图像视频等多媒体常用)
(4)数据变换和数据离散化
数据变换:光滑,属性构造,聚集,规范化,离散化和概念分层。 

3. 数据转换
将上面处理后的数据转换为特征,这些特征要尽可能的准确的描述数据,并且使得机器学习算法达到最优。
详见特征工程
4. 数据建模
根据机器学习模型优缺点,选择适宜本任务的最佳模型。其中一种方式是对每个模型都进行训练,再统计测试数据的误差,选择误差最小的模型即可。
另外,还需要调整模型的参数,使得模型表现尽可能最优。主要方法有手动调优、网格搜索、随机搜索以及基于贝叶斯的参数调优方法。详见机器学习调参-模型选择
5. 结果分析和改进
分析的对象主要是模型的优缺点(或者叫模型的评估),客观公正的评判自己的作品(能有高手帮忙最好啦)能清醒自己的认知。改进就是从分析当中来。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号