拓展了个新业务枚举类型,资损了
分享是最有效的学习方式。
案例背景
翻车了,为了cover线上一个业务场景,小猫新增了一个新的枚举类型,盲目自信就没有测试发生产了,由于是底层服务,上层调用导致计算逻辑有误,造成资损。老板很生气,后果很严重。
产品提出了一个新的业务场景,新增一种套餐费用的计算方式,由于业务比较着急,小猫觉得功能点比较小,开发完就决定迅速上线。不废话贴代码。
public enum BizCodeEnums {
BIZ_CODE0(50),
BIZ_CODE1(100),
BIZ_CODE2(150); //新拓展
private Integer code;
BizCodeEnums(Integer code) {
this.code = code;
}
public Integer getCode() {
return code;
}
}
套餐计费方式是一种枚举类型,每一种枚举代表一种套餐方式,因为涉及的到资金相关业务,小猫想要稳妥,于是拓展了一个新的业务类型BIZ_CODE2,接下来只要当上层传入指定的Code的时候,就可以进行计费了。下面为大概的演示代码,
public class NumCompare {
public static void main(String[] args) {
Integer inputBizCode = 150; //上层业务
if(BizCodeEnums.BIZ_CODE0.getCode() == inputBizCode) {
method0();
}else if(BizCodeEnums.BIZ_CODE1.getCode() == inputBizCode) {
method1();
//新拓展业务
}else if (BizCodeEnums.BIZ_CODE2.getCode() == inputBizCode) {
method2();
}
}
private static void method0(){
System.out.println("method0 execute");
}
private static void method1(){
System.out.println("method1 execute");
}
private static void method2(){
System.out.println("method2 execute");
}
}
上述可见,代码也没有经过什么比较好的设计,纯属堆业务代码,为了稳妥起见,小猫就照着以前的老代码拓展出来了新的业务代码,见上述备注。也没有经过仔细的测试,然后欣然上线了。事后发现压根他新的业务代码就没有生效,走的套餐计算逻辑还是默认的套餐计算逻辑。
容咱们盘一下这个技术细节,这可能也是很多初中级开发遇到的坑。
复盘分析
接下来,我们就来好好盘盘里面涉及的技术细节。其实造成这个事故的原因底层涉及两种原因,
- 开发人员并没有对Integer底层的原理吃透
- 开发人员对值比较以及地址比较没有掌握好
Intger底层分析
从上述代码中,我们先看一下发生了什么。
当Integer变量inputBizCode被赋值的时候,其实java默认会调用Integer.valueOf()方法进行装箱操作。
Integer inputBizCode = 100
装箱变成
Integer inputBizCode = Integer.valueOf(100)
接下来我们来扒一下Integer的源码看一下实现。源代码如下
@IntrinsicCandidate
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
我们点开 IntegerCache.low 以及IntegerCache.high的时候就会发现其中对应着两个值,分别是最小值为-128 最大的值为127,那么如此看来,如果目标值在-128~127之间的时候,那么直接会从cache数组中取值,否则就会新建对象。
我们再看一下IntegerCache中的cache是怎么被缓存进去的。
public final class Integer extends Number
implements Comparable<Integer>, Constable, ConstantDesc {
...此处省略无关代码
private static class IntegerCache {
static final int low = -128;
static final int high;
static final Integer[] cache;
static Integer[] archivedCache;
static {
// high value may be configured by property
int h = 127;
String integerCacheHighPropValue =
VM.getSavedProperty("java.lang.Integer.IntegerCache.high");
if (integerCacheHighPropValue != null) {
try {
h = Math.max(parseInt(integerCacheHighPropValue), 127);
// Maximum array size is Integer.MAX_VALUE
h = Math.min(h, Integer.MAX_VALUE - (-low) -1);
} catch( NumberFormatException nfe) {
// If the property cannot be parsed into an int, ignore it.
}
}
high = h;
// Load IntegerCache.archivedCache from archive, if possible
CDS.initializeFromArchive(IntegerCache.class);
int size = (high - low) + 1;
// Use the archived cache if it exists and is large enough
if (archivedCache == null || size > archivedCache.length) {
Integer[] c = new Integer[size];
int j = low;
for(int i = 0; i < c.length; i++) {
c[i] = new Integer(j++);
}
archivedCache = c;
}
cache = archivedCache;
// range [-128, 127] must be interned (JLS7 5.1.7)
assert IntegerCache.high >= 127;
}
private IntegerCache() {}
}
}
上述其实我们不难发现,原来IntegerCache是Integer这个类的静态内部类,里面的数组进行初始化的时候其实就是在Integer进行初始化进行类加载的时候就被缓存进去了,被static修饰的属性会存储到我们的栈内存中。在上面枚举BizCodeEnums.BIZ_CODE1.getCode()也是Integer类型,说白了当值在-127~128之间的时候,jvm拿到的其实是同一个地址的值。所以两个值当前相等。
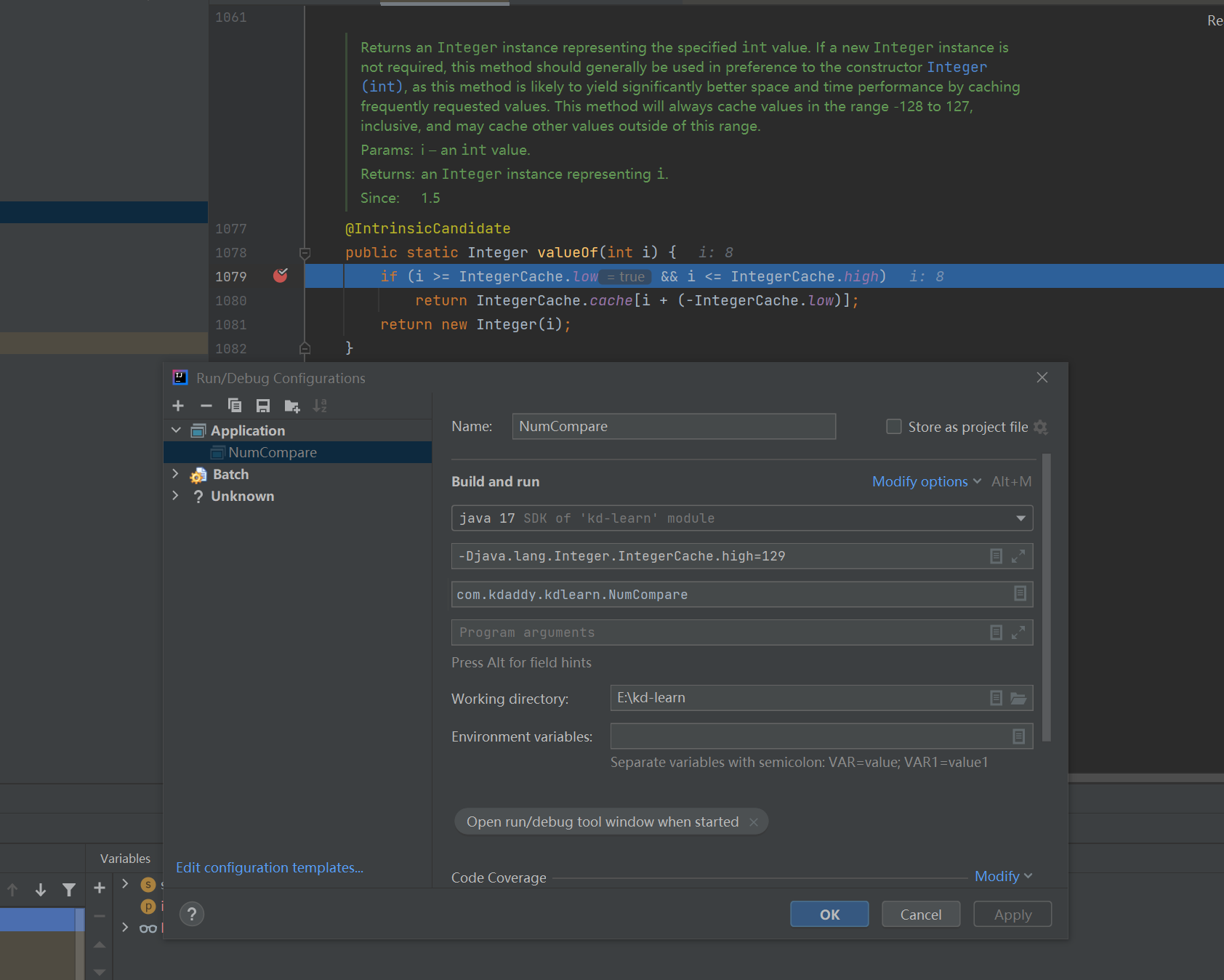
当然我们从上面的源码中其实不难发现其实最大值128并不是一成不变的,也可以通过自定义设置变成其他范围,具体的应该是上述的这个配置:
java.lang.Integer.IntegerCache.high
本人自己亲测设置了一下,如下图,是生效了的。
那么Integer为什么是-127~128进行缓存了呢?翻了一下Java API中,大概是这么解释的:
Returns an Integer instance representing the specified int value. If a new Integer instance is not required, this method should generally be used in preference to the constructor Integer(int), as this method is likely to yield significantly better space and time performance by caching frequently requested values. This method will always cache values in the range -128 to 127, inclusive, and may cache other values outside of this range.
上述大概意思就是-128~127数据在int范围内使用最频繁,为了减少频繁创建对象带来的内存消耗,这里其实采用了以空间换时间的涉及理念,也就是设计模式中的享元模式。
其实在JDK中享元模式的应用不仅仅只是局限于Integer,其实很多其他基础类型的包装类也有使用,咱们来看一下比较:
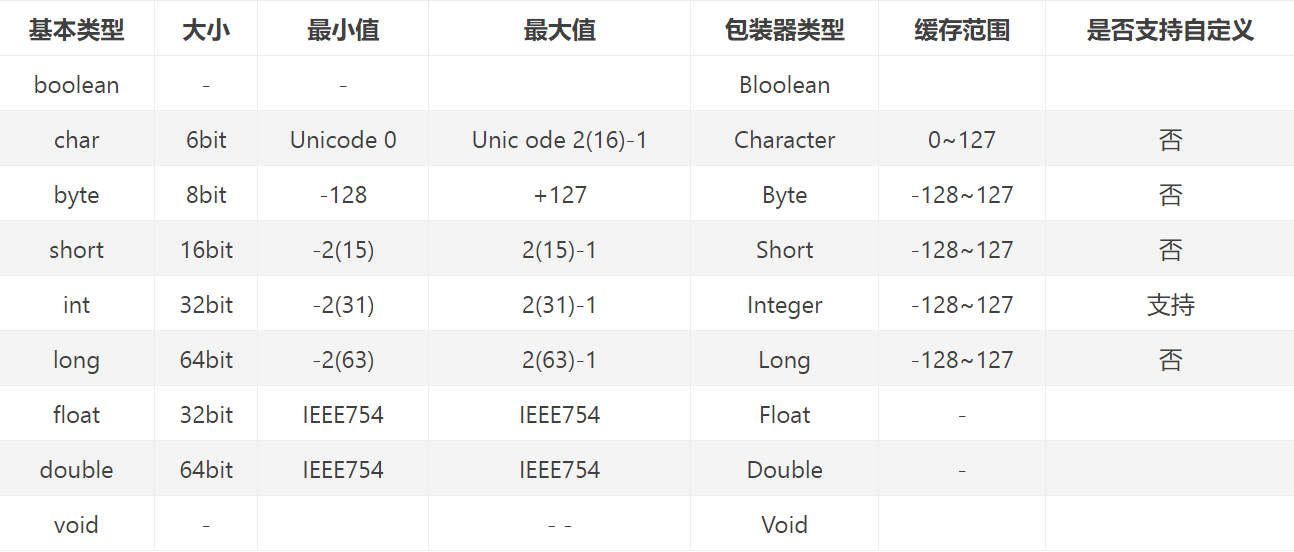
此处其实也是面试中的一个高频考点,需要大家注意,另外的话关于享元模式此处不展开讨论,后续老猫会穿插到设计模式中和大家一起学习使用。
值比较以及对象比较
我们再来看一下两种比较方式。
“==”比较
- 基本数据类型:byte,short,char,int,long,double,float,blooean,它们之间的比较,比较是它们的值;
- 引用数据类型:使用==比较的时候,比较的则是它们在内存中的地址(heap上的地址)。
业务代码中赋值为150的时候,底层代码重新new出来一个新的Integer对象,那么此时new出来的那个对象的值在栈内存中其实是新分配的一块地址,和之前的缓存中的地址完全不同。两分值进行等号比较的时候当然不会相等,所以也就不会走到method2方法块中。
“equals”比较
equals方法本质其实是属于Object方法:
public boolean equals(Object obj) {
return (this == obj);
}
但是从上面这段代码中我们可以明显地看到 默认的Object对象的equals方法其实和“==”是一样的,比较的都是引用地址是否一致。
我们测试一下将上述的==变成equals的时候,其实代码就没有什么问题了
if (BizCodeEnums.BIZ_CODE2.getCode() == inputBizCode)
改成
if (BizCodeEnums.BIZ_CODE2.getCode().equals(inputBizCode))
那么这个又是为什么呢?其实在一般情况下对象在集成Object对象的时候都会去重写equals方法,Integer类型中的equals也不例外。我们来看一下重写后的代码:
public boolean equals(Object obj) {
if (obj instanceof Integer) {
return value == ((Integer)obj).intValue();
}
return false;
}
上述我们看到如果使用Integer中的equals进行比较的时候,最终比较的是基本类型值,就上述代码比较的其实就是150==150?那么这种情况下,返回的就自然是true了,那么所以对应的mthod也会执行到了。
“hashCode”
既然已经聊到equals重写了,那么我们不得不再聊一下hashCode重写。可能经常会有面试官这么问“为什么重写 equals方法时一定要重写hashCode方法?”。
其实重写equals方法时一定要重写hashCode方法的原因是为了保证对象在使用散列集合(如HashMap、HashSet等)时能够正确地进行存储和查找。
在Java中,hashCode方法用于计算对象的哈希码,而equals方法用于判断两个对象是否相等。在散列集合中,对象的哈希码被用作索引,通过哈希码可以快速定位到存储的位置,然后再通过equals方法判断是否是相同的对象。
我们知道HashMap中的key是不能重复的,如果重复添加,后添加的会覆盖前面的内容。那么我们看看HashMap是如何来确定key的唯一性的(估计会有小伙伴对底层HashMap的完整实现感兴趣,另外也是面试的高频题,不过在此我们不展开,老猫后续尽量在其他文章中展开分析)。老猫的JDK版本是java17,我们一起看下源码
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
查看代码发现,它是通过计算Map key的hashCode值来确定在链表中的存储位置的。那么这样就可以推测出,如果我们重写了equals但是没重写hashCode,那么可能存在元素重复的矛盾情况。
咱们举个例子简单实验一下:
public class Person {
private Integer age;
private String name;
public Person(Integer age, String name) {
this.age = age;
this.name = name;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
return Objects.equals(age, person.age) && Objects.equals(name, person.name);
}
// @Override
// public int hashCode() {
// return Objects.hash(age, name);
// }
}
public class TestPerson {
public static void main(String[] args) {
Person p1 = new Person(18,"ktdaddy");
Person p2 = new Person(18,"ktdaddy");
HashMap<Person,Object> map = new HashMap<>();
map.put(p1, "1");
System.out.println("equals:" + p1.equals(p2));
System.out.println(map.get(p2));
}
}
上述的结果输出为
equals:true
null
由于没有重写hashCode方法,p1和p2的hashCode方法返回的哈希码不同,导致它们在HashMap中被当作不同的键,因此无法正确地获取到值。如果重写了hashCode方法,使得相等的对象返回相同的哈希码,就可以正确地进行存储和查找操作。
案例总结
其实当我们在日常维护的代码的时候要勇于去质疑现有代码体系,如果发现不合理的地方,隐藏的坑点,咱们还是需要立刻将其填好,以免发生类似小猫遇到的这种情况。
另外的话,写代码还是不能停留于会写,必要的时候还是得翻看底层的源码实现。只有这样才能知其所以然,未来也才能够更好地用好大神封装的一些代码。或者可以自主封装一些好用的工具给他人使用。
派生面试题
上面的案例中涉及到的知识点可能会牵扯到这样的面试题。
问题1: 如何自定义一个类的equals方法?
答案: 要自定义一个类的equals方法,可以按照以下步骤进行:
- 在类中创建一个equals方法的覆盖(override)。
- 确保方法签名为public boolean equals(Object obj),并且参数类型是Object。
- 在equals方法中,首先使用==运算符比较对象的引用,如果引用相同,返回true。
- 如果引用不同,检查传递给方法的对象是否属于相同的类。
- 如果属于相同的类,将传递的对象强制转换为相同类型,然后比较对象的字段,以确定它们是否相等。
- 最后,返回比较结果,通常是true或false。
问题2:equals 和 hashCode 之间有什么关系?
答案:
equals 和 hashCode 在Java中通常一起使用,以维护对象在散列集合(如HashMap和HashSet)中的正确行为。
如果两个对象相等(根据equals方法的定义),那么它们的hashCode值应该相同。
也就是说,如果重写了一个类的equals方法,通常也需要重写hashCode方法,以便它们保持一致。
这是因为散列集合使用对象的hashCode值来确定它们在内部存储结构中的位置。
问题3:== 在哪些情况下比较的是对象内容而不是引用?
答案:
在Java中,== 运算符通常比较的是对象的引用。但在以下情况下,== 可以比较对象的内容而不是引用:
对于基本数据类型(如int、char等),== 比较的是它们的值,而不是引用。
字符串常量池:对于字符串字面值,Java使用常量池来存储它们,因此相同的字符串字面值使用==比较通常会返回true。
我是老猫,10Year+资深研发老鸟,让我们一起聊聊技术,聊聊人生。
个人公众号,“程序员老猫”

 浙公网安备 33010602011771号
浙公网安备 33010602011771号