Hadoop 之 Spark 安装配置与示例
Spark 安装配置与示例
Spark,它是大规模数据处理通用的并行化计算框架,基于MapReduce实现分布式计算,其中间结果可以保存在内存中,从而不再需要读写HDFS。Spark 是 Scala 语言实现的, Scala 也被用作其应用程序框架,Spark 和 Scala 能够紧密集成,Scala 可以像操作本地集合对象一样轻松地操作分布式数据集。
Spark主要特点是,简单方便,与RDD(是一种只读的、分区的记录集合),很好结合;计算速度快,中间结果缓存在内存中;操作较为丰富。
Spark可应用于各种运算,如迭代式算法、交互式数据挖掘,还可以应用在 SQL 查询、文本处理、机器学习等方面。相对Hadoop的优势不仅体现在性能提升上,其框架也为Spark Core(批处理),Spark SQL(交互式),Spark Streaming(流式),MLlib(机器学习),Graphx(图计算)等提供了统一的数据处理平台。
接下来我们看一下Spark的安装配置及简单示例
当然在安装Spark前,检查Hadoop及JDK等有没安装,若没安装,可参考我前几篇文章,这里不再赘述。
一、Spark&Scala安装
1、下载spark-2.1.0-bin-hadoop2.7.tgz安装包
http://spark.apache.org/downloads.html
2、 scala-2.11.8.tgz安装包
http://www.scala-lang.org/download/2.11.8.html
3、 分别解压
spark-2.1.0-bin-hadoop2.7.tgz、scala-2.11.8.tgz
到指定目录,如:/opt/spark/、 /opt/scala
mv spark-2.1.0-bin-hadoop2.7.tgz /opt/spark/ tar -zxvf spark-2.1.0-bin-hadoop2.7.tgz mv scala-2.11.8.tgz /opt/scala tar -zxvf scala-2.11.8.tgz
二、配置环境变量
/etc/profile
增加如下内容:
#spark enviroment export SPARK_HOME=/opt/spark/spark-2.1.0-bin-hadoop2.7 export PATH=$PATH:$SPARK_HOME/bin #scla enviroment export SCALA_HOME=/opt/scala/scala-2.11.8 export PATH=$PATH:$SCALA_HOME/bin
三、复制新建两个配置文件
1、进入$SPARK_HOME/conf目录
cp spark-env.sh.template spark-env.sh cp slaves.template slaves
2、修改spark-env.sh文件
export JAVA_HOME=/usr/java/jdk1.7.0_80 export HADOOP_HOME=/opt/hadoop/hadoop-2.7.3 export HADOOP_CONF_DIR=/opt/hadoop/hadoop-2.7.3/etc/hadoop export SCALA_HOME=/opt/scala/scala-2.11.8 export SPARK_MASTER_IP=kencentos01 export SPARK_WORKER_MEMORY=1g export SPARK_LOCAL_DIRS=/opt/spark/spark-2.1.0-bin-hadoop2.7 export SPARK_DRIVER_MEMORY=1g
3、配置slaves文件
# A Spark Worker will be started on each of the machines listed below.
kencentos01
kencentos02
kencentos03
四、同步Spark与scala文件到集群其他节点上
scp -r /opt/spark/spark-2.1.0-bin-hadoop2.7 hadoop@kencentos02:/opt/spark scp -r /opt/spark/spark-2.1.0-bin-hadoop2.7 hadoop@kencentos03:/opt/spark scp -r /opt/scala/scala-2.11.8 hadoop@kencentos02:/opt/scala scp -r /opt/scala/scala-2.11.8 hadoop@kencentos03:/opt/scala
也可以用命令rsync来实现文件同步
rsync –av /opt/spark/spark-2.1.0-bin-hadoop2.7 hadoop@kencentos02:/opt/spark rsync -av /opt/scala/scala-2.11.8 hadoop@kencentos02:/opt/scala
五、运行Spark
1、启动Spark
[hadoop@kencentos01 sbin]$ ./start-all.sh


[hadoop@kencentos01 sbin]$ ./start-all.sh starting org.apache.spark.deploy.master.Master, logging to /opt/spark/spark-2.1.0-bin-hadoop2.7/logs/spark-hadoop-org.apache.spark.deploy.master.Master-1-kencentos01.out kencentos02: starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark/spark-2.1.0-bin-hadoop2.7/logs/spark-hadoop-org.apache.spark.deploy.worker.Worker-1-kencentos02.out kencentos03: starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark/spark-2.1.0-bin-hadoop2.7/logs/spark-hadoop-org.apache.spark.deploy.worker.Worker-1-kencentos03.out kencentos01: starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark/spark-2.1.0-bin-hadoop2.7/logs/spark-hadoop-org.apache.spark.deploy.worker.Worker-1-kencentos01.out
为了避免与hadoop的启动命令冲突,最好到spark目录下或指定目录执行启动命令start-all
2、查看进程是否正常启动
[hadoop@kencentos01 sbin]$ jps 28678 SecondaryNameNode 31505 Master 28289 FsShell 29148 DataNode 31570 Worker 18144 FsShell 31648 Jps 28503 NameNode 28864 ResourceManager
3、进入UI界面,可以看到运行的节点
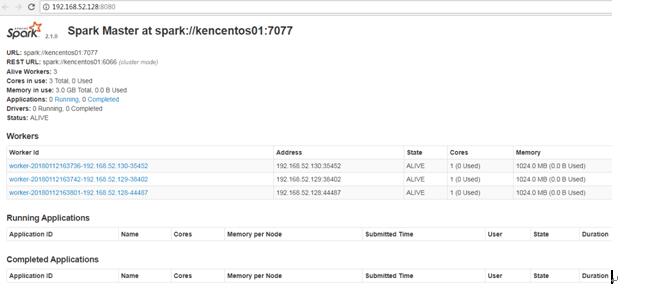
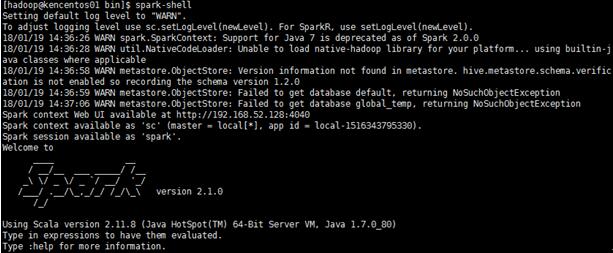
4、进入spark-shell,可用用交互式命令操作
Scala 是 Spark 的主要编程语言,写 Spark 应用,并不一定要用 Scala,用 Java、Python 都是也可以,但Scala 的优势是开发效率高,代码精简,可以通过 Spark Shell 进行交互式实时查询,方便排查问题,进入spark-shell
六、运行Spark示例
/examples/src/main 目录下有 Scala、Java、Python、R 等语言的版本的示例程序,这里运行一个计算 π 的近似值的SparkPi示例程序,
采用grep 命令进行过滤,因为不过滤会有很多运行的内容输出,不易查看
[hadoop@kencentos01 bin]$ ./run-example SparkPi 2>&1 | grep "Pi is roughly" Pi is roughly 3.1409357046785233

 浙公网安备 33010602011771号
浙公网安备 33010602011771号