Centos7部署k8s[v1.16]高可用[keepalived]集群
实验目的
一般情况下,k8s集群中只有一台master和多台node,当master故障时,引发的事故后果可想而知。
故本文目的在于体现集群的高可用,即当集群中的一台master宕机后,k8s集群通过vip的转移,又会有新的节点被选举为集群的master,并保持集群的正常运作。
因本文体现的是master节点的高可用,为了实现效果,同时因资源条件限制,故总共采用4台服务器完成本次实验,3台master,1台node。
看到这也需有人有疑惑,总共有4台机器的资源,为啥不能2台master呢?这是因为通过kubeadm部署的集群,当中的etcd集群默认部署在master节点上,3节点方式最多能容忍1台服务器宕机。如果是2台master,当中1台宕机了,直接导致etcd集群故障,以至于k8s集群异常,这些基础环境都over了,vip漂移等高可用也就在白瞎。
环境说明
基本信息
# 主机列表
10.2.2.137 master1
10.2.2.166 master2
10.2.2.96 master3
10.2.3.27 node0
# 软件版本
docker version:18.09.9
k8s version:v1.16.4
架构信息
本文采用kubeadm方式搭建集群,通过keepalived的vip策略实现高可用,架构图如下:
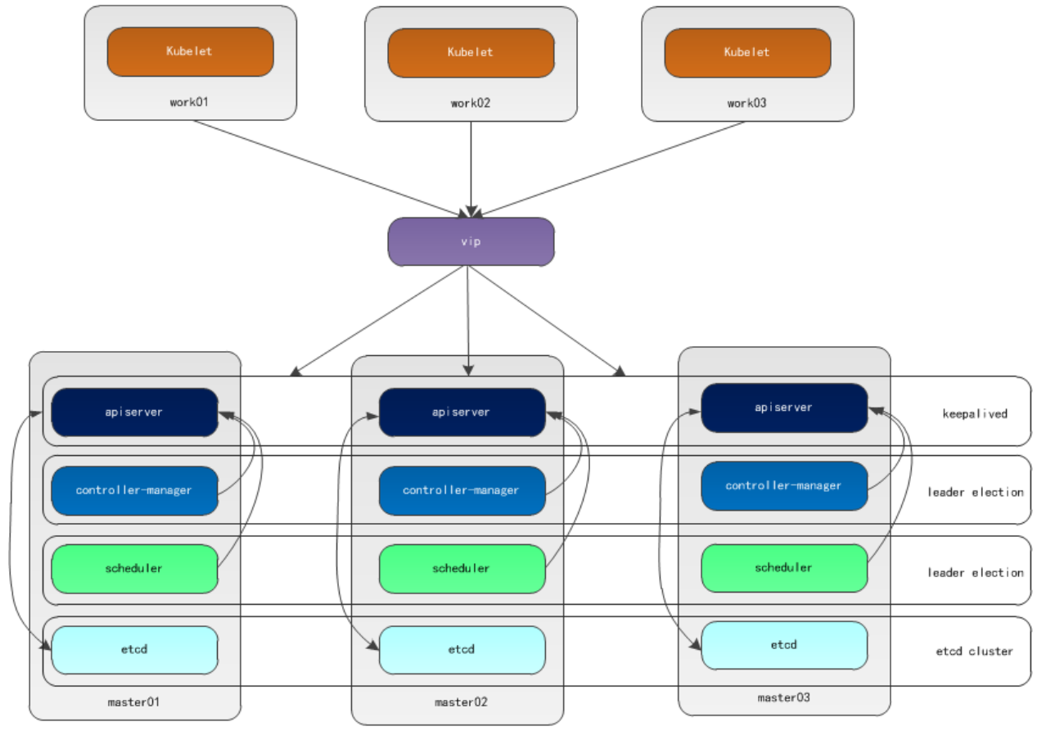
# 主备模式高可用架构说明

a)apiserver通过keepalived实现高可用,当某个节点故障时触发vip转移;
b)controller-manager和scheduler在k8s内容通过选举方式产生领导者(由leader-elect选型控制,默认为true),同一时刻集群内只有一个scheduler组件运行;
c)etcd在kubeadm方式实现集群时,其在master节点会自动创建etcd集群,来实现高可用,部署的节点为奇数,3节点方式最多容忍一台机器宕机。
环境准备
说明
1、大多数文章都是一步步写命令写步骤,而对于有部署经验的人来说觉得繁琐化了,故本文大部分服务器shell命令操作都将集成到脚本;
2、本文相关shell脚本地址: https://gitee.com/kazihuo/k8s-install-shell
3、所有要加入到k8s集群的机器都执行本部分操作。
操作
a)将所有服务器修改成对应的主机名,master1示例如下;
# hostnamectl set-hostname master1 #重新登录后显示新设置的主机名
b)配置master1到master2、master3免密登录,本步骤只在master1上执行;
[root@master1 ~]# ssh-keygen -t rsa # 一路回车
[root@master1 ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub root@10.2.2.166
[root@master1 ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub root@10.2.2.96
c)脚本实现环境需求配置;
# sh set-prenv.sh



#!/bin/bash #==================================================== # Author: LuoMuRui # Blog: https://www.cnblogs.com/kazihuo # Create Date: 2020-04-02 # Description: System environment configuration. #==================================================== # Stop firewalld firewall-cmd --state #查看防火墙状态 systemctl stop firewalld.service #停止firewall systemctl disable firewalld.service #禁止firewall开机启动 # Close selinux getenforce #查看selinux状态 setenforce 0 #临时关闭selinux sed -i 's/^ *SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config #永久关闭(需重启系统) # Set localhost's dns cat >> /etc/hosts << EOF 10.2.2.137 master1 10.2.2.166 master2 10.2.2.96 master3 10.2.3.27 node0 EOF # Disable swap swapoff -a #临时禁用 sed -i.bak '/swap/s/^/#/' /etc/fstab #永久禁用 # Kernel parameter modification # k8s网络使用flannel,该网络需要设置内核参数bridge-nf-call-iptables=1,修改这个参数需要系统有br_netfilter模块 lsmod |grep br_netfilter # 查看模块 modprobe br_netfilter # 临时新增 # 永久新增模块 cat > /etc/rc.sysinit << EOF #!/bin/bash for file in /etc/sysconfig/modules/*.modules ; do [ -x $file ] && $file done EOF cat > /etc/sysconfig/modules/br_netfilter.modules << EOF modprobe br_netfilter EOF chmod 755 /etc/sysconfig/modules/br_netfilter.modules cat <<EOF > /etc/sysctl.d/k8s.conf net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 EOF sysctl -p /etc/sysctl.d/k8s.conf # Set the yum of k8s cat <<EOF > /etc/yum.repos.d/kubernetes.repo [kubernetes] name=Kubernetes baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/ enabled=1 gpgcheck=1 repo_gpgcheck=1 gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg EOF yum clean all && yum -y makecache
软件安装
docker安装
说明:所有节点都执行本部分操作!
# sh install-docker.sh
#!/bin/bash #==================================================== # Author: LuoMuRui # Blog: https://www.cnblogs.com/kazihuo # Create Date: 2020-04-02 # Description: Install docker. #==================================================== # Install dependency package yum install -y yum-utils device-mapper-persistent-data lvm2 # Add repo yum-config-manager \ --add-repo \ https://download.docker.com/linux/centos/docker-ce.repo # Looking the version of docker yum list docker-ce --showduplicates | sort -r # Install docker yum install docker-ce-18.09.9 docker-ce-cli-18.09.9 containerd.io -y # Mirror acceleration & change Cgroup Driver # 修改cgroupdriver是为了消除告警:[WARNING IsDockerSystemdCheck]: detected “cgroupfs” as the Docker cgroup driver. The recommended driver is “systemd”. Please follow the guide at https://kubernetes.io/docs/setup/cri/ cat > daemon.json <<EOF { "registry-mirrors": ["https://registry.docker-cn.com"], "exec-opts": ["native.cgroupdriver=systemd"] } EOF # Start && enable systemctl daemon-reload systemctl start docker systemctl enable docker docker --version # Others yum -y install bash-completion source /etc/profile.d/bash_completion.sh
keepalived安装
说明:三台master节点执行本部分操作!
# 安装
# yum -y install keepalived
# 配置
# master1上keepalived配置
[root@master1 ~]# cat /etc/keepalived/keepalived.conf
! Configuration File for keepalived global_defs { router_id master1 } vrrp_instance VI_1 { state MASTER interface eth0 virtual_router_id 51 priority 150 advert_int 1 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 10.2.2.6 } }
# master2上keepalived配置
[root@master2 ~]# cat /etc/keepalived/keepalived.conf
! Configuration File for keepalived global_defs { router_id master2 } vrrp_instance VI_1 { state BACKUP interface eth0 virtual_router_id 51 priority 100 advert_int 1 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 10.2.2.6 } }
# master3上keepalived配置
[root@master3 ~]# cat /etc/keepalived/keepalived.conf
! Configuration File for keepalived global_defs { router_id master3 } vrrp_instance VI_1 { state BACKUP interface eth0 virtual_router_id 51 priority 50 advert_int 1 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 10.2.2.6 } }
# 启动
# service keepalived start
# systemctl enable keepalived
# vip查看
[root@master1 ~]# ip a
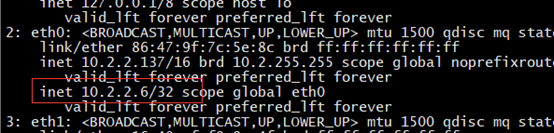
# 功能功验
将master1上的keepalived服务器停止或者master1服务器关机后,master2上接管vip,同时master2也关机后,master3接管vip。
k8s安装
说明:所有节点都执行本部分操作!
组件:
kubelet
运行在集群所有节点上,用于启动Pod和容器等对象的工具
kubeadm
用于初始化集群,启动集群的命令工具
kubectl
用于和集群通信的命令行,通过kubectl可以部署和管理应用,查看各种资源,创建、删除和更新各种组件
# sh install-k8s.sh
#!/bin/bash #==================================================== # Author: LuoMuRui # Blog: https://www.cnblogs.com/kazihuo # Create Date: 2020-04-02 # Description: Install the soft of k8s. #==================================================== # Looking the version yum list kubelet --showduplicates | sort -r # Install yum install -y kubelet-1.16.4 kubeadm-1.16.4 kubectl-1.16.4 # Start && enable systemctl enable kubelet && systemctl start kubelet # Bash env echo "source <(kubectl completion bash)" >> ~/.bash_profile source /root/.bash_profile
镜像下载
说明:所有节点都执行本部分操作!
因国内网络的限制,故从阿里云镜像仓库下载镜像后本地打回默认标签名的方式,让kubeadm在部署集群时能正常使用镜像。
# sh download-images.sh
#!/bin/bash #==================================================== # Author: LuoMuRui # Blog: https://www.cnblogs.com/kazihuo # Create Date: 2020-04-02 # Description: Download images. #==================================================== url=registry.cn-hangzhou.aliyuncs.com/loong576 version=v1.16.4 images=(`kubeadm config images list --kubernetes-version=$version|awk -F '/' '{print $2}'`) for imagename in ${images[@]} ; do docker pull $url/$imagename docker tag $url/$imagename k8s.gcr.io/$imagename docker rmi -f $url/$imagename done
master初始化
初始化操作
[root@master1 ~]# cat kubeadm-config.yaml
apiVersion: kubeadm.k8s.io/v1beta2 kind: ClusterConfiguration kubernetesVersion: v1.16.4 apiServer: certSANs: - 10.2.2.6 controlPlaneEndpoint: "10.2.2.6:6443" networking: podSubnet: "10.244.0.0/16"
[root@master01 ~]# kubeadm init --config=kubeadm-config.yaml
# 初始化成功后末尾显示kubeadm join的信息,记录下来;
You can now join any number of control-plane nodes by copying certificate authorities and service account keys on each node and then running the following as root: kubeadm join 10.2.2.6:6443 --token 2ccecd.v72vziyzdfnbr46u \ --discovery-token-ca-cert-hash sha256:eb92768acb748d722ef7d97bc60751a375b67b12a46c7a7232c54cdb378d2e61 \ --control-plane Then you can join any number of worker nodes by running the following on each as root: kubeadm join 10.2.2.6:6443 --token 2ccecd.v72vziyzdfnbr46u \ --discovery-token-ca-cert-hash sha256:eb92768acb748d722ef7d97bc60751a375b67b12a46c7a7232c54cdb378d2e61
# 初始化失败后可重新初始化
# kubeadm reset
# rm -rf $HOME/.kube/config
添加环境变量
echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
source ~/.bash_profile
安装flannel插件
# wget https://raw.githubusercontent.com/coreos/flannel/2140ac876ef134e0ed5af15c65e414cf26827915/Documentation/kube-flannel.yml
# kubectl apply -f kube-flannel.yml
control plane节点加入
证书分发
# master1将认证文件同步到其他master节点
[root@master1 ~]# sh cert-others-master.sh
USER=root CONTROL_PLANE_IPS="master2 master3" #CONTROL_PLANE_IPS="master2 master3" for host in ${CONTROL_PLANE_IPS}; do scp /etc/kubernetes/pki/ca.crt "${USER}"@$host: scp /etc/kubernetes/pki/ca.key "${USER}"@$host: scp /etc/kubernetes/pki/sa.key "${USER}"@$host: scp /etc/kubernetes/pki/sa.pub "${USER}"@$host: scp /etc/kubernetes/pki/front-proxy-ca.crt "${USER}"@$host: scp /etc/kubernetes/pki/front-proxy-ca.key "${USER}"@$host: scp /etc/kubernetes/pki/etcd/ca.crt "${USER}"@$host:etcd-ca.crt # Quote this line if you are using external etcd scp /etc/kubernetes/pki/etcd/ca.key "${USER}"@$host:etcd-ca.key done
# master2和master3节点配置证书
说明:只将master1的部分证书同步到master2和master3,因为在后续的 kubeadm join 中,会自动生成部分证书配置。
[root@master2 ~]# sh cert-set.sh
[root@master3 ~]# sh cert-set.sh
mv /${USER}/ca.crt /etc/kubernetes/pki/ mv /${USER}/ca.key /etc/kubernetes/pki/ mv /${USER}/sa.pub /etc/kubernetes/pki/ mv /${USER}/sa.key /etc/kubernetes/pki/ mv /${USER}/front-proxy-ca.crt /etc/kubernetes/pki/ mv /${USER}/front-proxy-ca.key /etc/kubernetes/pki/ mv /${USER}/etcd-ca.crt /etc/kubernetes/pki/etcd/ca.crt # Quote this line if you are using external etcd mv /${USER}/etcd-ca.key /etc/kubernetes/pki/etcd/ca.key
others master加入集群
# master2和master3加入集群,下文以master2为示例,master3按部就班即可;
[root@master2 ~]# kubeadm join 10.2.2.6:6443 --token 2ccecd.v72vziyzdfnbr46u \
--discovery-token-ca-cert-hash sha256:eb92768acb748d722ef7d97bc60751a375b67b12a46c7a7232c54cdb378d2e61 \
--control-plane
[root@master2 ~]# scp master1:/etc/kubernetes/admin.conf /etc/kubernetes/
[root@master2 ~]# echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile && source .bash_profile
集群节点查看
# kubectl get nodes
NAME STATUS ROLES AGE VERSION master1 Ready master 20h v1.16.4 master2 Ready master 20h v1.16.4 master3 Ready master 19h v1.16.4
node节点加入
加入操作
[root@node0 ~]# kubeadm join 10.2.2.6:6443 --token 2ccecd.v72vziyzdfnbr46u \
--discovery-token-ca-cert-hash sha256:eb92768acb748d722ef7d97bc60751a375b67b12a46c7a7232c54cdb378d2e61
节点查看
# kubectl get nodes
NAME STATUS ROLES AGE VERSION node0 Ready <none> 18h v1.16.4 master1 Ready master 20h v1.16.4 master2 Ready master 20h v1.16.4 master3 Ready master 19h v1.16.4
集群功能验证
操作
# 关机master1,模拟宕机
[root@master1 ~]# init 0
# vip飘到master2
[root@master2 ~]# ip a |grep '2.6'
inet 10.2.2.6/32 scope global eth0
# 组件controller-manager和scheduler发生迁移
# kubectl get endpoints kube-controller-manager -n kube-system -o yaml |grep holderIdentity
control-plane.alpha.kubernetes.io/leader: '{"holderIdentity":"master3_885468ec-f9ce-4cc6-93d6-235508b5a130","leaseDurationSeconds":15,"acquireTime":"2020-04-01T10:15:28Z","renewTime":"2020-04-02T06:02:46Z","leaderTransitions":8}'
# kubectl get endpoints kube-scheduler -n kube-system -o yaml |grep holderIdentity
control-plane.alpha.kubernetes.io/leader: '{"holderIdentity":"master2_cf16fd61-0202-4610-9a27-3cd9d26b4141","leaseDurationSeconds":15,"acquireTime":"2020-04-01T10:15:25Z","renewTime":"2020-04-02T06:03:09Z","leaderTransitions":9}'
# 集群创建pod,依旧正常使用
# cat nginx.yaml
apiVersion: apps/v1 kind: Deployment metadata: name: nginx-test spec: selector: matchLabels: app: nginx replicas: 3 template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:latest
# kubectl apply -f nginx.yaml
# kubectl get pods

结论
1、集群中3个master节点,无论哪个节点宕机,都不影响集群的正常使用;
2、当集群中3个master节点有2个故障,则造成etcd集群故障,直接影响集群,导致异常!
========================================
转载请保留此段声明,且在文章页面明显位置给出原文链接,谢谢!
==============================================================================
^_^ 如果觉得这篇文章对你有小小的帮助的话,记得在右下角点个“推荐”哦,您的“推荐”将是我最大的写作动力 ^_^
==============================================================================


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构